对应吴恩达机器学习网易云课程第13章的内容。
在监督学习方面,与神经网络和逻辑回归相比,支持向量机在学习复杂的非线性方程时有很大的优势。
SVM优化目标
- 支持向量机的优化目标:支持向量机的优化目标表达式是从逻辑回归改进而来的。在cost函数中,在y=0和y=1时使用两条直线来代替曲线,分别得到的两个表达式我们定为
和
。进而我们将最小值表达式乘m,使用新的权重表示变量C代替原有的
。得到SVM的优化目标表达式如下。

- 与逻辑回归
输出概率不同,SVM直接输出结果,也即,利用求得的
向量,计算
:
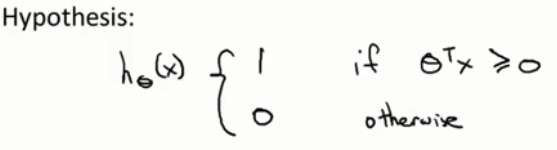
SVM大间隔

- 从直观上来说,SVM(也被称为大间距分类器)求得的决策边界与样本的最大间距更大一些。这个间距称为支持向量机的间距。

- 当我们将C设置的非常大时,我们的分类器将对异常数据非常敏感,即,当增加了图中这样的异常点时,决策边界将从竖直线变为斜线。但如果C不被设置为这么大,它将对敏感数据有一定的“宽容性”,决策边界极有可能保持竖直线不变。
核函数


通过定义核函数产生新的特征,也即任选一些点,对每一个点周围的点有一个量化相似度的函数,称为核函数(这里我们使用高斯核函数),当相似度高时,核函数值趋近于甚至等于1,否则则无限趋近于0。在公式中我们将不同点对应的衡量相似度的函数记为
,那么给定一个待判断点,我们可以结合参数向量通过计算
是否大于0来得到模型预计的结果,>=0默认预测结果为1,否则为0。

因此,在SVM中,我们可以通过标记点和相似性函数,来定义新的特征变量,从而训练复杂的非线性边界。
那么,我们如何得到并选择这些标记点?其他的核函数是什么样子的?
我们可以就选择训练集中的点作为标记点。。


所以每个样本的对应一个特征向量
。
代表训练样本点
与预设点
之间的相似度。故
。我们还会在特征向量
中添加一个分量
=1。
所以加入核函数改进后的SVM是根据给定的特征向量得到新的特征向量
,它是m+1维的。

得到新的代价函数如上,我们求得的是使得上式取得最小值的向量。需要注意的是,不仅cost函数内部被更换,后面正则项中n代表的是新特征的数目,即m。而
不参与正则化。
SVM参数
:较大的C,正则化程度越低,越容易过拟合。
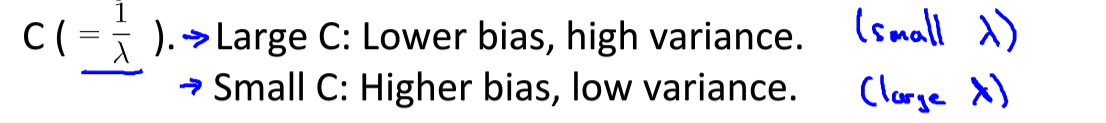
:
越大,曲线越平缓,容易得到一个高偏差、低方差的模型。它倾向于得到一个随着x变化得缓慢的模型。
