对数损失函数(log loss):分类问题的输出结果是每个类别的概率,log-loss的输出的概率就表示其所属的类别的置信度。
对于二分类问题,log loss的计算公式为:
其中N代表样本数量,代表第i个样本的真实值(0或1),
代表第i个样本为1的概率。
对于多分类问题,log loss的计算公式为:
其中N代表样本数量,C为类别数量,代表第i个样本的真实类别为第j个类别(值为0或1),
代表第i个样本被判别为第j个类别的概率。
log loss是对额外噪声的度量,这个噪声是由于预测值与实际值不同而产生的。最小化logloss(或称作交叉熵)便是最大化分类器的准确率。
混淆矩阵:对分类结果进行详细描述的表,对于二分类问题,矩阵是一个2*2的,对于多分类问题,矩阵是n*n的。在二分类问题中,分类结果分为4种,即positive-positive(TP),positive-negative(FN),negative-positive(FP),negative-negative(TN)。根据混淆矩阵可以衍生出多个评价指标,即accuracy(准确度),precision(精确度),recall(召回率),F1-score。
| predicted as positive | predicted as negative | |
| labeled as positive | True Positive(TP) | False Negative(FN) |
| labeled as negative | False Positive(FP) | True Negative(TP) |
accuracy(正确率):表示在所有样本中,正样本被判断为正的与负样本被判断为负的,所占总量的比例。计算公式如下。
precision(准确率/查准率):表示在所有被判断为正的样本中,真正是正样本的比例。计算公式如下。
要增加查准率,需要把判断条件设置的严格一些,FP减小的出现,即使得负样本判断为正的数量减少。
recall(召回率/查全率):表示在所有被判断正确的样本中,正样本的比例。计算公式如下。
要增加查全率,需要把判断条件设置的松弛一些,FN减小的出现,即使得正样本判断为负的数量减少。
查准率与查全率是一对矛盾的度量,一般情况下,查准率高时,查全率往往偏低,因为判断条件严格,减少FP的同时,也使得一些正例被误判成负(TP减小);查全率高时,查准率往往偏低,因为判断条件松弛,增加了TP的同时,也使得一些负例被误判成正(FP增加)。
PRC曲线:以查准率为Y轴,查全率为X轴画出的曲线图。
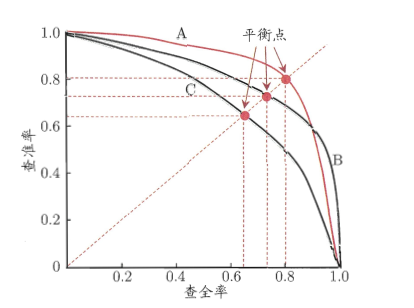
上图就是一幅P-R图,它能直观地显示出学习器在样本总体上的查全率和查准率,显然它是一条总体趋势是递减的曲线。在进行比较时,若一个学习器的PR曲线被另一个学习器的曲线完全包住,则可断言后者的性能优于前者,比如上图中A优于C。但是B和A谁更好呢?因为AB两条曲线交叉了,所以很难比较,这时比较合理的判据就是比较PR曲线下的面积,该指标在一定程度上表征了学习器在查准率和查全率上取得相对“双高”的比例。因为这个值不容易估算,所以人们引入“平衡点”(BEP)来度量,他表示“查准率=查全率”时的取值,值越大表明分类器性能越好,以此比较我们一下子就能判断A较B好。
F1-score:是一个综合考虑precision和recall的指标,比BEP更为常用,它的值往往接近较小的那个。计算公式如下。
Kappa指数:主要用于比较分析两幅地图或图像的差异性是“偶然”因素还是“必然”因素所引起的,还经常用于检查卫星影像分类对于真实地物判断的正确性程度。能够计算整体的一致性和分类一致性的指数。计算公式如下。kappa计算结果为-1~1,但通常kappa是落在 0~1 间,可分为五组来表示不同级别的一致性:0.0~0.20极低的一致性(slight)、0.21~0.40一般的一致性(fair)、0.41~0.60 中等的一致性(moderate)、0.61~0.80 高度的一致性(substantial)和0.81~1几乎完全一致(almost perfect)。
被称为观测精确性或一致性单元的比例,即混淆矩阵对角线元素的和除以总数,
被称为偶然性一致或期望的偶然一致的单元的比例,即各个行向量和与列向量和的总和除以总数的平方。计算示例如下。

=(2+4+4+1)/20
=(2*4+9*7+8*4+5*1)/20^2
gini系数:指绝对公平线(line of equality)和洛伦茨曲线(Lorenz Curve)围成的面积与绝对公平线以下面积的比例。gini系数代表了模型的不纯度,gini系数越小,不纯度越低,特征越好。
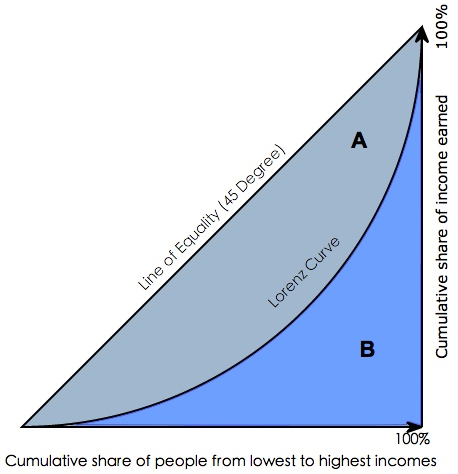
gini coefficient = A/(A+B)
gini系数用在评判分类模型的预测效力时,是指ROC曲线和中线围成的面积与中线之上面积的比例。
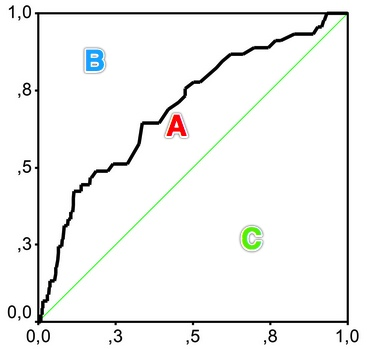
gini coefficient = A/(A+B)
gini系数与AUC可以相互转换:gini coefficient = (AUC-C)/(A+B)=(AUC-0.5)/0.5=2*AUC-1。需要注意的是,这里的AUC并不是ROC_AUC(y是二值的)计算里的ROC曲线面积,而是X,Y坐标计算出来的面积(y是连续的)。
ROC曲线
ROC曲线(Receiver Operating Characteristics)是以真正率为纵,假正率为横的曲线。
TPR真正率是TP/(TP+FN)即所有正样本中被真正识别为正样本的概率。越高越好
FPR假正率是FP/(TN+FP)即所有负样本中被错误地识别为正样本的概率。越低越好。
TPR与FPR两者是相互制约的。如果一个医生把所有没病和有病的人都看成是有病的,那么TPR=1而FPR=1.

图中,黑线是阈值,若正样本为90个,负样本为10个,把阈值左移到B,使得所有正样本被识别,整体正确确率有90%,但是没有现实意义。

左上点(0,1)即TPR=1,FPR=0,正类被完全分对,医生把有病的人(正例)全都识别了出来;A点,TPR>FPR,判断大体正确;B点TPR=FPR,蒙对一半,蒙错一半;C点FPR>TPR,没病的(负例)也被看成有病(正例)的。

取不同的阈值作为判断为正的条件,可以得到ROC曲线。点A时,TPR较小,但FPR也很小,B和C时两个都变大,说明虽然正样本被更多的识别出来,但也使得负样本被识别为正。
ROC曲线越靠左上,分类器越好。
AUC
AUC值(Area Under ROC Curve)是量化这个结果的好坏的。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
AUC物理意义——假设分类器的输出是样本属于正类的socre(置信度)——预测为正的概率值,则AUC的物理意义为,任取一对(正、负)样本,正样本的score大于负样本的score的概率(即正样本预测为正的概率比负样本预测为正的概率大的概率)。
AUC的计算方法:
(1)AUC就是ROC曲线下许多个小梯形的面积相加,即
(2)第二种方法:根据AUC的物理意义,我们计算正样本score大于负样本的score的概率。取N*M(N为正样本数,M为负样本数)个二元组,比较score,最后得到AUC。时间复杂度为O(N*M)。
(3)第三种方法:与第二种方法相似,直接计算正样本score大于负样本的score的概率。我们首先把所有样本按照score排序,依次用rank表示他们,如最大score的样本,rank=n(n=N+M),其次为n-1。那么对于正样本中rank最大的样本(rank_max),有M-1个其他正样本比他score小,那么就有(rank_max-1)-(M-1)个负样本比他score小。其次为(rank_second-1)-(M-2)。最后我们得到正样本大于负样本的概率为:
公式解释:
1、为了求的组合中正样本的score值大于负样本,如果所有的正样本score值都是大于负样本的,那么第一位与任意的进行组合score值都要大,我们取它的rank值为n,但是n-1中有M-1是正样例和正样例的组合这种是不在统计范围内的(为计算方便我们取n组,相应的不符合的有M个),所以要减掉,那么同理排在第二位的n-1,会有M-1个是不满足的,依次类推,故得到后面的公式M*(M+1)/2,我们可以验证在正样本score都大于负样本的假设下,AUC的值为1
2、根据上面的解释,不难得出,rank的值代表的是能够产生score前大后小的这样的组合数,但是这里包含了(正,正)的情况,所以要减去这样的组(即排在它后面正例的个数),即可得到上面的公式
AUC计算主要与排序有关,所以它对排序敏感,对预测分数不敏感。
参考: