论文地址:https://arxiv.org/pdf/1612.01105.pdf
项目地址:https://github.com/hszhao/PSPNet
概述
场景解析的挑战在于无限制的开放词汇和不同场景,论文使用pyramid pooling module,实现基于不同区域的上下文集成,提出PSPnet,实现利用上下文信息的能力进行场景解析。本方法的提出取得了ImageNet scene parsing 2016 的第一名,PASCAL VOC 2012 semantic segmentation 的第一名,以及Cityscapes 的第一名。
主要贡献:
- 提出了PSPNet 在基于FCN 的框架中集成困难的上下文特征
- 通过基于深度监督误差开发了针对ResNet 的高效优化策略
- 构建了一个用于state-of-the-art 的场景解析和语义分割的实践系统
Motivation
论文新思想的提出最重要的是这个思想的来源,受什么启发,我觉得作者提出这样的改进方法来源于其对现有方法的研究以及场景解析错误原因的分析。
对于scene parsing 和semantic segmentation 任务,深度卷积网络是目前的主流方法。论文的基准网络是FCN+dilated network。dilated network的目的是获得大的感受野。
两个主要的研究方向,一是特征整合(Feature Ensembling),又分为多尺度(multi-scale)特征整合和多级(multi-level)特征整合。二是结构预测(Structure Prediction),比如之前经常使用的条件随机场(CRF)以及LIP人物解析中用到的结构化loss。对于全局上下文信息,文献使用全局平均池化,但是对于复杂的ADE20K 数据库,效果不是很好。
针对ADE20K 数据集,发现语义分割中的常见问题有:
- 关系不匹配(Mismatched Relationship):比如,飞机更可能在天上或者在跑道上,而不是公路上。
- 易混淆的类别(Confusion Categories):许多类别具有高度相似的外表。
- 不显眼的类别(Inconspicuous Classes):场景中包括任意尺寸的物体,小尺寸的物体难以被识别但是有时候对于场景理解很重要。
总结以上研究方法以及存在的问题,发现这些大多数错误都部分或者完全和上下文关系以及全局信息有关系,而PSPNet 就是为了整合不同区域的context来获取全局的context 信息。这是作者改进方法的来源。
网络框架
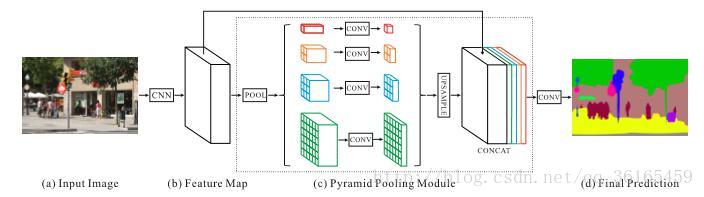
上图中图片输入的CNN 是ResNet,使用了dilated convolution。
中间模块是pyramid pooling module,是为了获得全局先验信息。在一个深度网络中,感受野的尺寸大小决定有多少context 信息可以用。理论上ResNet 的感受野尺寸要比输入图像尺寸大。但是有文章指出CNN 的实际感受野尺寸要比理论尺寸小很多。之前提出的Global average pooling 对于复杂的ADE20K 数据库来说过于简单。因此,论文借鉴Spatial pyramid pooling(SPP空间金字塔池化方法)提出pyramid pooling module。
第一行是用global pooling 生成的一个单独的输出。第二行将特征图等分为4 块,每块分别用global pooling 得到bin output,接下来的行以此类推。上图四行分别对应1×1, 2×2, 3×3 和6×6。
为了减小维度和位置全局特征的权值,在每一行使用一个1×1 卷积层。接着我们使用双线性插值,使其和原始特征图尺寸一样大小。最后和原始特征图组合起来。
优化策略
为了更好的训练网络层数较多的模型,引入了additional/auxiliary loss(辅助loss),这个辅助loss 帮助优化学习过程,并不影响主分支的训练,按照0.4×auxiliary loss + 0.6×master branch loss 的权重进行训练。实际上这个辅助loss 就是在ResNet 的res4b22 后面提取出来的。
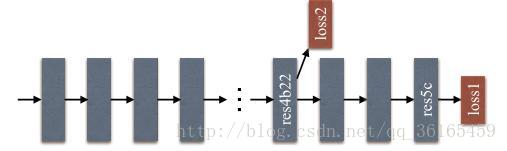
训练tricks
- poly learning rate policy:学习率下降策略
- DA(data augmentation):random mirror, random resize(0.5-2),random rotation(-10 到10 度), random Gaussian blur
- DR(dimension reduction):1×1 的卷积层
- AL(additionial loss):辅助性loss
- MS(multi-scale testing)
- 选取合适的batchsize,openMPI 并行计算
思考
这篇论文给我的启发主要以下两个方面。
一是作者分析了以往的研究方法后,尤其是在分析了ADE20K 数据集的出错原因之后,发现出错的原因主要是没有考虑全局上下文信息,想要把全局信息加入到网络训练中来。其实从大方向上来说,这种改进措施在深度卷积网络中是比较常见的,深度卷积网络提取特征的特点就是低层多是局部细节特征,高层多是全局语义特征。本文属于从高层提取全局上下文特征,在这个方面来说也是按照主流研究方法来的,但是它采用多尺度划分,我认为是为了得到不同区域的上下文信息。这些区域有比较大的以至于覆盖整张图片,PP Model 里面的第一行对应这些;也有比较小的区域,6×6 的划分足够包含这些信息,其余2×2,4×4 的是中间大小的区域。特征融合再卷积是常见的将不同特征整合的方法。
二是作者采用additional loss 作为优化策略也是比较常见的优化方法,这也是LIP 的核心思想(加入structure loss)。LIP 和PSPnet 两篇论文的联系是都是考虑添加其它特征,使解析更加准确,不同的是PSPnet 将这种特聚合到CNN 中进行训练,而LIP 将结构化特征加入到loss 中训练。PSPnet 的AL 是借鉴ResNet 的残差优化思想,通过实验确定取ResNet 第四块区域的结果作为
AL 的合理性。
综上考虑,对于human parsing,我们除了在loss 上加入结构化信息,也可以考虑人物解析出错的原因。人物解析比较容易出错的是左右手识别,左右脚识别,这些对于场景来说也是属于不起眼的信息,也可以考虑加入上下文信息。