Pyramid Scene Parsing Network–CVPR,2017
Github代码链接
一、背景介绍
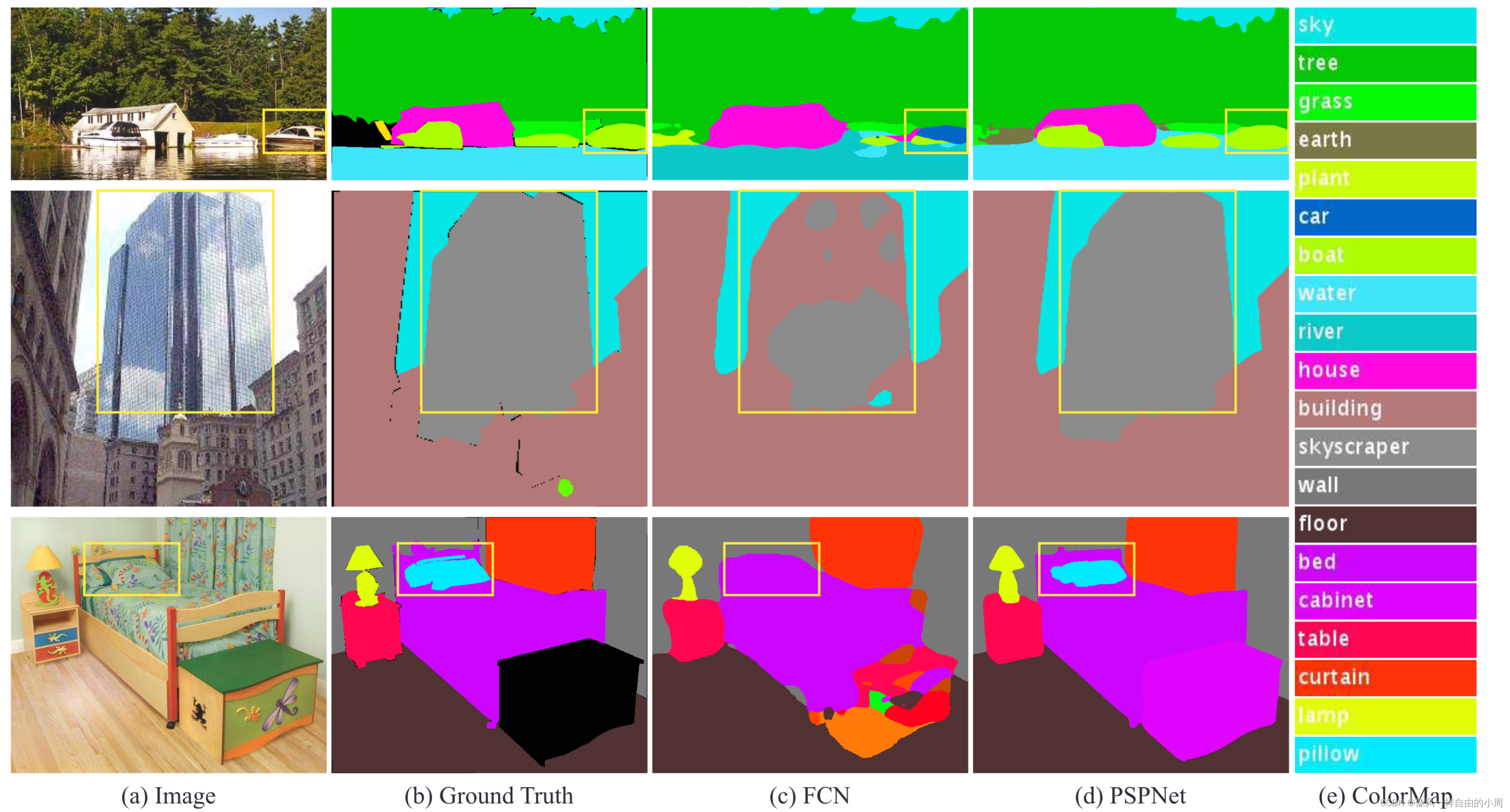
现阶段随着数据集制作精细化、标签种类变多、具有语义相似标签等导致出现一些困难样本,使得经典的语义分割网络无法很好的处理(如FCN,作者认为FCN缺乏合适的策略去利用全局场景类别线索)这些困难样本。如下,作者挑选了ADE20K数据集中几个具有代表性的困难样本,第一行因为FCN没有正确捕获图像内容之间的关系,错误的将外形和汽车相似的游艇识别为汽车,要是能够正确识别出其在水面上就能够避免这种错误;第二行是因为FCN没有捕获类别之间的关系导致遇到相似的类别如building和skyscraper这两类,就无法正确区分;第三行是因为类别代表的物体相对大小各有区别,但FCN没有针对该问题进行处理,导致和床纹理相似的枕头被错误识别成床。
总结这些观察结果,许多错误部分或完全与不同感受野的上下文关系和全局信息相关。
提高模型感受野是解决该问题的切入点,虽然通过理论分析ResNet获得的感受野比原图还大(也就是能够感知全图),但是通过实验发现CNN的感受野是小于理论分析的。
不少人提出用Global average pooling来提高模型感受野,但是作者认为对于困难样本经过Global average pooling后的特征仅用一个特征向量来代表许多的物体类别会导致空间信息的丢失或者引起歧义。故作者认为可以对于局部区域进行全局平均池化就可以缓解该问题。
此外,随着网络变得越来越深,会带来优化困难这一问题。ResNet通过skip connection来缓解优化问题,作者提出通过添加附加损失来辅助训练(附加损失及其相关分支只在训练时使用,测试时就会丢弃)。
二、网络结构和优化方法
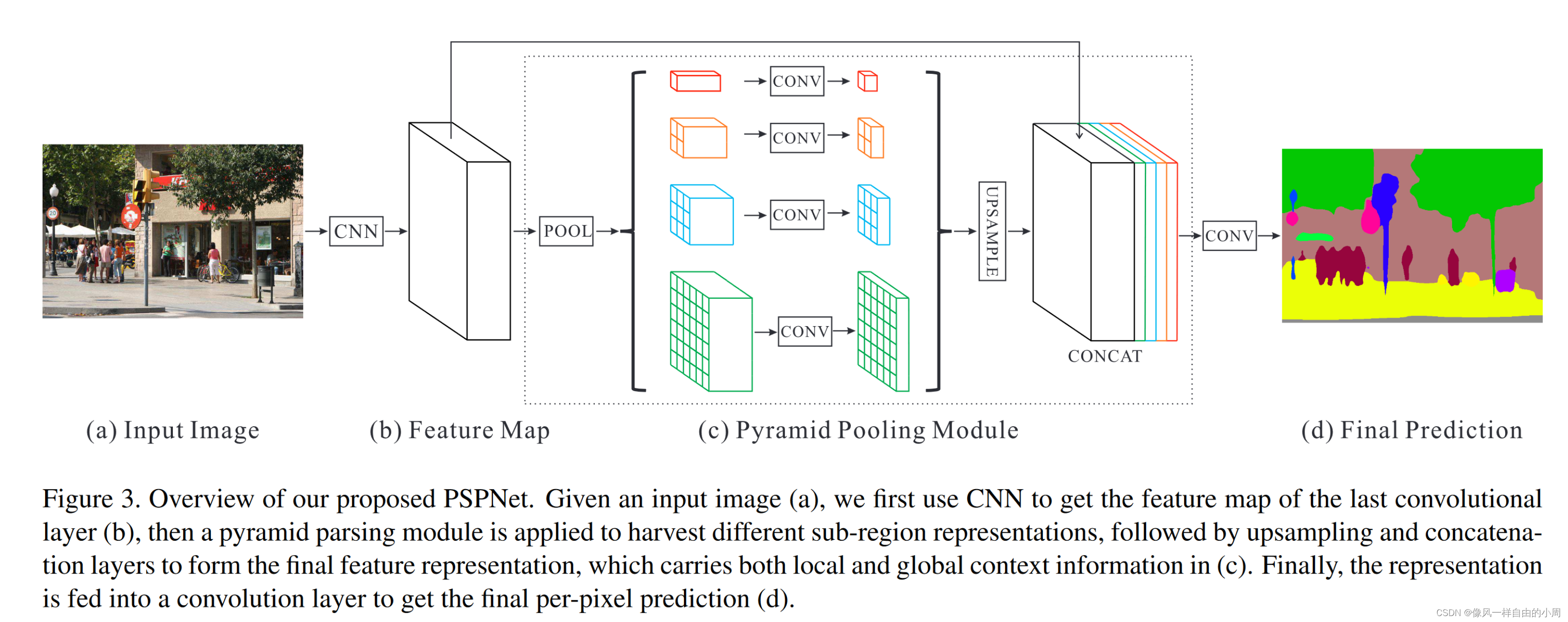
结构如上图所示,从图上就能大致看出网络forward过程是什么样子。首先输入图片,通过特征提取网络如ResNet等提取到特征X后(这里作者为了扩大感受野使用的是包含空洞卷积的ResNet,X特征为原图的1/8大小)。之后X输入进作者提出的pyramid pooling module,该模块分为四个分支,通过AdaptiveAvgPool2d函数将特征X池化为1x1、2x2、3x3和6x6大小的4个特征。这四个特征分别对应不同尺度的特征,比如1x1的表示全图。之后这4个特征通过卷积层减少网络通道数,方便后面和特征X沿着通道维度拼接。在拼接前要将特征图的大小统一,这里作者使用了线性插值法将4个特征上采样到和特征X大小一样的特征。之后通过卷积层获取最终的输出。
这里多说一嘴,通常图片大小为256或者512,1/8就是32或者64。这样看就大体知道作者为什么选择1、2、3、6了。
为了方便大家理解,这里贴一下Pyramid Pooling Module的Pytorch代码:
class PPM(nn.Module):
def __init__(self, in_dim, reduction_dim, bins): #这里的in_dim就是特征X的通道数、reduction_dim就是获得的4个特征通过卷积层减少通道后的数量,通常取in_dim/4。bins为列表,表示通过AdaptiveAvgPool2d后获得的4个分支的特征大小。
super(PPM, self).__init__()
self.features = []
for bin in bins:
self.features.append(nn.Sequential(
nn.AdaptiveAvgPool2d(bin),
nn.Conv2d(in_dim, reduction_dim, kernel_size=1, bias=False),
nn.BatchNorm2d(reduction_dim),
nn.ReLU(inplace=True)
))
self.features = nn.ModuleList(self.features)
def forward(self, x):
x_size = x.size()
out = [x]
for f in self.features:
out.append(F.interpolate(f(x), x_size[2:], mode='bilinear', align_corners=True))
return torch.cat(out, 1)
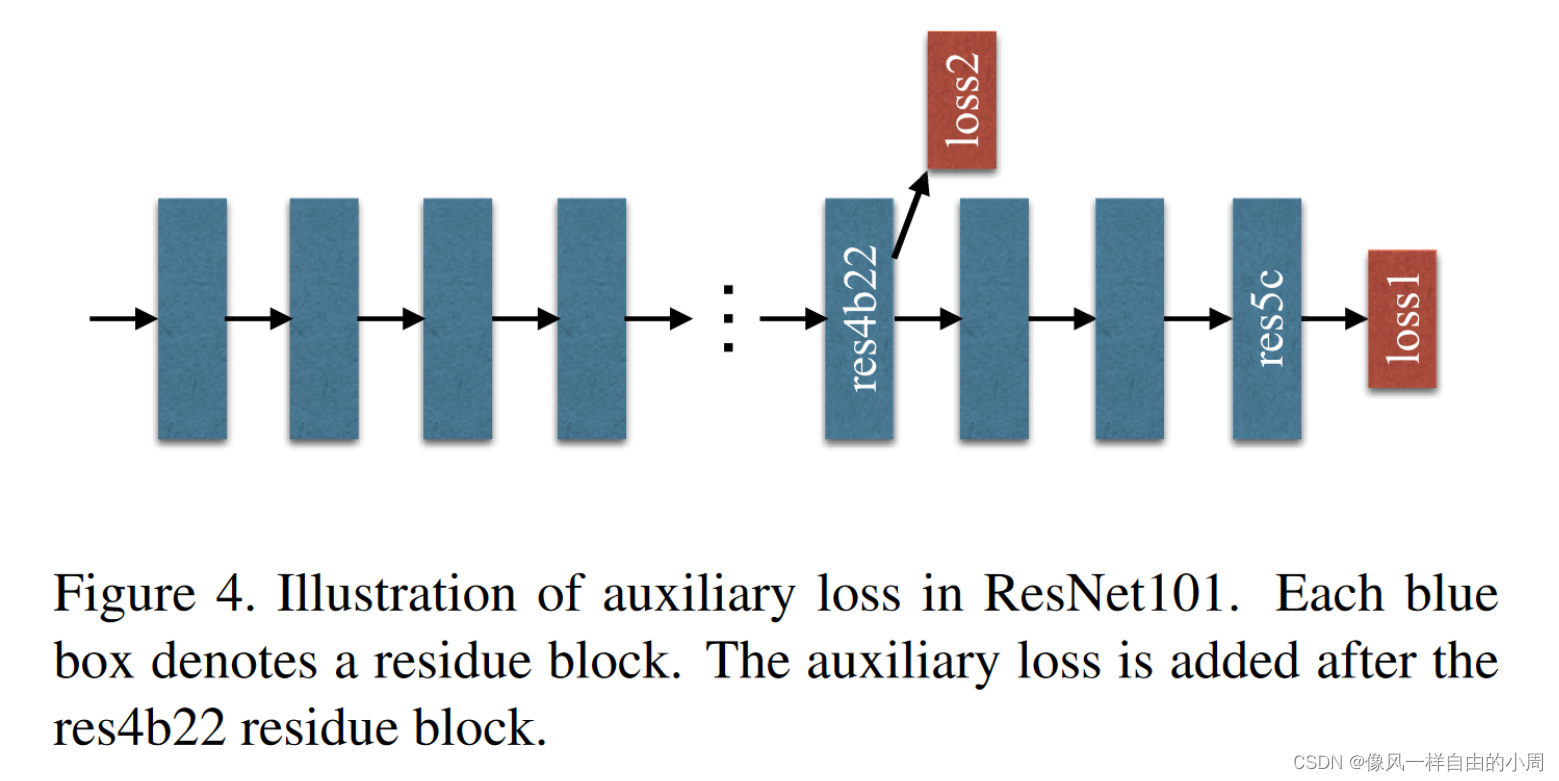
为了方便优化,作者在ResNet网络上除了主损失函数loss1还添加了loss2。这里因为要使用loss2是一个有监督损失,对应的标签为Ground Truth,就必须添加单独的分支让获取到的特征能够和Ground Truth对应。作者使用了卷积层+上采样构造这个分支。
三、实验结果
For a practical deep learning system, devil is always in the details.
实验结果在当时遥遥领先