1. 摘要
对于人来说,一般不会固定的注视某个场景。 取而代之的是,人眼四处走动,定位物体的部分信息以了解物体的位置。 这种主动的感知移动过程称为saccade。
受这种机制的启发,本文提出了一种称为SaccadeNet的快速,准确的物体检测器。 它包含四个主要模块,即中心注意力模块(Center Attentive Module),角点注意力模块(Corner Attentive Module),注意力传递模块(Attention Transitive Module)和聚合注意力模块(Aggregation Attentive Module),中心注意力模块预测目标中心的位置和类别。 同时,对于每个预测的目标中心,注意力传递用于预测相应边界框角的粗略位置。 为了提取提供信息的角点特征,使用角点注意模块来强制CNN更加关注物体边界,从而使回归边界框更加准确。 最后,聚合注意模块利用从中心和角点聚合的特征来优化物体边界框,这使网络可以使用好几个不同的提供信息的物体关键点,并预测目标的位置(从粗到精)。(角点注意力模块仅在训练过程中使用,以提取更多的拐角信息特征,从而带来性能提升)
SaccadeNet采用了包括中心点和4个边角点在内的多个物体关键点,这些关键点编码并提取了目标的多层次的丰富的细节特征。此外,与CenterNet相比几乎没有速度损失(同时预测角点和中心,而且没有分组操作),但是精度提升许多。在MS COCO数据集上,在28 FPS时达到40.4%mAP的性能,在118 FPS时达到30.5%mAP的性能。
2. 相关工作
- 在 CornerNet 的开创性工作之后,基于关键点的 Anchor-free 目标检测器引起了人们的注意。 在CornerNet中,FCN可以直接预测拐角热图,每个角的嵌入向量和一组偏移量。 嵌入向量用于对成对的角进行分组以形成边界框,偏移量作用于将角从低分辨率热图重新映射到高分辨率输入图像。 为了更好地定位角,引入并使用角池化层。
- ExtremeNet 引入了一种预测极限点而不是边界框角的方法,并引入了中心热图进行分组步骤。
-Centernet(-Keypoint triplets forobject detection)通过添加中心关键点来扩展CornerNet。 中心关键点用于启发式地定义中心区域,然后他们使用该区域来细化分组的角。 - 为了避免复杂的分组过程,CenterNet (objects as points)直接预测中心关键点和目标的大小。 此外,它通过峰值关键点提取代替了基于IoU的非最大抑制(NMS),减少了推理时间。
- 在Fcos:Fully convolutional one-stage object detection中,中心度用于表示在每个位置预测的边界框的物体性。
- 在RepPoints 中,学习了一组采样点来限制目标在关键点预测框架下的空间范围。
3. 本文方法
3.1 总体结构
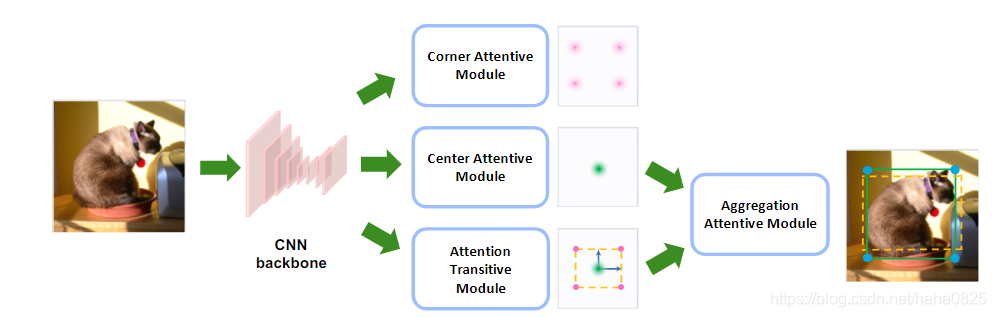
在SaccadeNet中,利用5个关键点来检测物体的信息:物体中心点和4个边界框角点。 在CNN backbone 之后,中心注意力模块专注于预测物体中心关键点; 然后底部的注意力传递模块将注意力从物体中心切换到估计物体四个拐角的粗略位置。 之后,“聚合注意模块”使用从中心和角关键点聚合的信息,并预测物体的精确位置。 此外,为了获得信息丰富的拐角特征,顶部的拐角注意模块(仅在训练中使用)用于强制CNN backbone 更加关注物体边界。
3.2 中心注意力模块
中心注意力提供SaccadeNet第一眼看到在其中心的目标,并预测目标中心的关键点。它以CNN主干网的特征作为输入,预测中心热图。中心热图用于估计图像中所有物体的类别和中心位置。中心热图中的通道数是类别数。在中心注意力中,它包含两个卷积层。这种双卷积结构称为head module。它是构建其他SaccadeNet模块的基本组件(3.6中是对于他的详细描述)。
与很多现有方法一样,本文也是使用高斯热图作为ground truth。关键点的ground truth热图并未定义为0或1,这是因为目标关键点附近的位置应该比远处的位置得到更少的惩罚。假设关键点位于位置X_k,则ground truth热图上位置X处的值定义为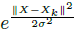 。
。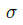 设置为半径的1/3,半径由目标的大小决定,以确保区域内的所有位置都可以生成一个边界框(这个边界框至少与ground truth的IoU大于t,这里 t 设为0.3)。
设置为半径的1/3,半径由目标的大小决定,以确保区域内的所有位置都可以生成一个边界框(这个边界框至少与ground truth的IoU大于t,这里 t 设为0.3)。
此外,focal loss 的变体被应用于辅助高斯热图:
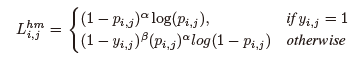
其中p_i,j是热图位置(i,j)处的得分,y_i,j是相应的ground truth。
3.3 注意力传递模块
该模块对深度特征图的所有位置的角点进行预测(Transpredicts)。对于单个图像,输出形状为w_f × h_f × 2,其中w_f, h_f分别表示特征映射的宽度和高度。最后一个维度设计为2,表示边界框的宽度和高度。在得到(i,j)位置处每个中心的边界框的宽度和高度后,我们可以计算出相应的角为:
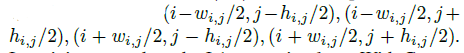
在训练中,采用L1回归损失。使用中心注意力和注意力传递,SaccadeNet可以生成边界粗糙的目标检测。
3.4 聚合注意力模块
接着提出了一种聚集注意力算法,通过重新关注目标中心和边界框角点来预测目标的精确位置。它使用双线性插值从角点和中心关键点聚合CNN特征,并输出更精确的目标边界框。
聚合注意力是一个用于目标边界求精的轻量级模块。让w_i,j,h_i,j表示(i,j)处的宽度和高度预测。然后,通过以下方法计算在位置(i,j)处居中的相应左上角、右上角、左下角和右下角:
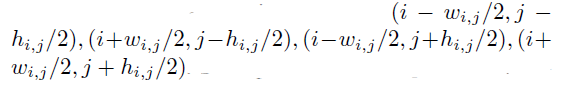
之前有工作表明,双线性采样有助于下采样特征映射,因此聚合注意力从注意力传递模块的输出中提取角点和中心点,中心注意力从双线性插值输出的主干中提取特征。
聚合注意力的结构是一个改进的head模块。改变第一卷积层的输入,让它以物体的中心和角的特征作为输入。
最后,聚合注意力通过合并角点和中心的特征来回归剩余偏移量以细化目标的边界。聚合注意力的输出由残差(residual)宽度和残差高度组成。采用L1 loss来训练这个模块。
3.5 角点注意力模块(只在训练阶段)
为了提取角点信息特征,提出了一种角点注意力分支来强制CNN backbone学习区分角点特征。角点注意力使用一个head模块来处理特征并输出4通道热图,包括左上角、右上角、左下角和右下角。因为此分支仅在训练期间使用,因此它提高推理准确性的同时并没有增加计算。
角点注意力的训练也基于focal loss 和高斯热图。本文尝试了agnostic和non-agnostic的热图,这意味着不同的物体类别是否共享相同的角热图输出。在本文的实验中,它们的性能没有显著差异。为了缩短训练时间和更容易实现,本文的实验中使用了agnostic热图的角点注意力。
3.6 基本组件head module
头部模块。头部模块是构建SaccadeNet四个模块的基本组件,本文对所有的头模块使用2个卷积层的统一结构。第一卷积层之后是ReLU层,其核大小为3 × 3和256维输出信道。第二卷积层使用1 × 1卷积核,不带激活函数。
中心注意力包含一个头部模块。此模块的输出通道数量取决于类别的数量,例如,Pascal VOC为20,MS COCO为80。
角点注意力包含一个头部模块,该模块输出一个4通道热图,表示4个角点的agnostic热图。
传递注意力包含2个头部模块,都具有2通道输出,分别指示两个方向的中心偏移和物体的宽度和高度。
聚合注意力包含一个头部模块,输出2个通道,表示目标的宽度和高度的残差偏移。
4. 实验
4.1 推理
在MS-COCO数据集上,输入图像的大小为512 × 512。当翻转图像和原始图像都被用作输入时,本文对中心点、角点和聚集点的输出进行平均。为了提高速度,使用了峰值拾取NMS,而不是基于IoU的NMS进行后处理。峰值拾取NMS是一个类似于3 × 3池化的运算符,它消除了所有非峰值激活。它的推理时间小于0.1ms,而基于IoU的NMS需要2ms进行后处理。
在NMS之后,选择中心注意力提供的centerness scores前100的目标。
4.2 与SOTA对比
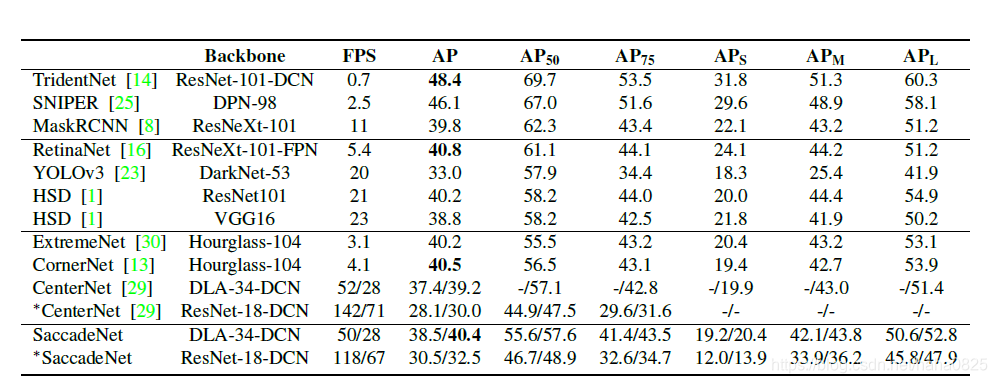
只看AP不是很先进,优点更在于结合速度和精度。
4.3 消融实验
- 聚集注意力对于获得更精确的边界至关重要。
- 大/中型目标以及较高质量的边界框(IOU 0.7,0.9的)使用聚集注意力和角点注意力的增益较多。
- 发现在除中心点以外的所有关键点中,角点是最有助于SaccadeNet的关键点。
- 发现对于聚合注意力和角点注意力,靠近角点的关键点都会导致更高的性能。一个可能的原因是角点定义了目标的范围以及使用边界框来计算损失。
- 与不使用聚合注意力模块的相比,单独使用中心特征几乎无法提高性能。单独使用角点特征,性能显著提高。结合角点和中心点的特征,又进一步提高了检测结果,特别是在高IOU阈值下。
- 迭代使用聚合注意力可以获得更精确的边界。然而,迭代求精不是很有效(提升较小)。出于对速度精度的折中考虑,本文只使用一次迭代。