DGST : Discriminator Guided Scene Text detector
摘要
由于自然场景文本检测广泛的应用场景已经吸引了 计算机视觉人员大量的关注。将语义分割方法引入文本检测已经获得了巨大的成功。本篇论文提出一个检测框架基于对抗生成网络来改善语义分割效果。不同于二进制文本分数图我们用更多的信息生成多尺度文本分数图来更加合理的生成文本位置图,解决了像素粘连问题。在ICDAR上获得了87%的F分数。
Introduction
自然场景文本检测当前还有很多挑战,像字体大小,多语言,复杂的光照以及背景条件。当前存在的检测方法主要基于两类,一种是基于物体检测,另一种是基于语义分割。基于语义分割的方法是更加的直观简洁,但是仍然有下述问题:
1.不精确的语义标签:由于自然场景文本分布的多样性,很多标注的文本框包含一些背景像素,这会造成学习困难。
2.多任务学习困难:像经典的EAST方法从共享的网络进行位置回归和分割任务,然而回归信息作为一个距离测量不能很好的从共享网络提取,这一点比起两阶段方法的效果要差。
我们引进GAN网络,来改善上述问题。文本检测任务转换成语义图像生成任务。判别器来调整训练损失和生成文本分数图。同时我们设计soft-text-score map来加强文本框的中央位置,弱化边缘像素的影响。为了消除背景像素的影响避免学习过程中的学习困惑。最终的检测结果通过结合不同缩小比例的soft-text-score图来获得。我们在不同的数据集上评估了我们的方法,在ICDAR2015上达到了87%,在ICDAR2017上达到了74.3%。本篇论文的贡献主要有三点:
1.引入了GAN网络
2.改善了文本和非文本区域的表示
3.大量的实验证实了本方法的高性能。
Related Works
近几年已经有大量的工作在场景文本检测上面。这些方法被分为两个分支,一个分支是基于物体检测如SSD、YOLO以及FasterRCNN 等。这些方法将文本看作一个特殊的物体,最后需要NMS来获得最终的结果。另一个分支是基于语义分割,用FCN来预测文本区域。EAST利用FCN的思想用一个模型来检测文本的位置、大小和方向。PSENET可以检测弯曲文本。这种方法的缺点上面已经描述。
一些基于语义分割的任务改善了先前的文本分数标签方法。PixelLink首先将文本检测转换成一个纯语义分割任务。PSEnet用渐进链接算法来精确的分割连接紧密相连的实例。Textfield用方向字段编码二进制文本mask以及方向信息。
随着深度学习的发展,无监督GAN网络有着突飞猛进的进展。受GAN以及CycleGAN的影响,本篇论文我们用更加合理 的soft-text-score图来获得更加精确的语义分割结果而且用连接组件分析替换传统的NMS。这不仅避免了学习训练中的困惑而且使得整个网络成为一个单任务学习过程,更加的简洁直观。
METHODOLOGY
图2展示了整个网络的流程:
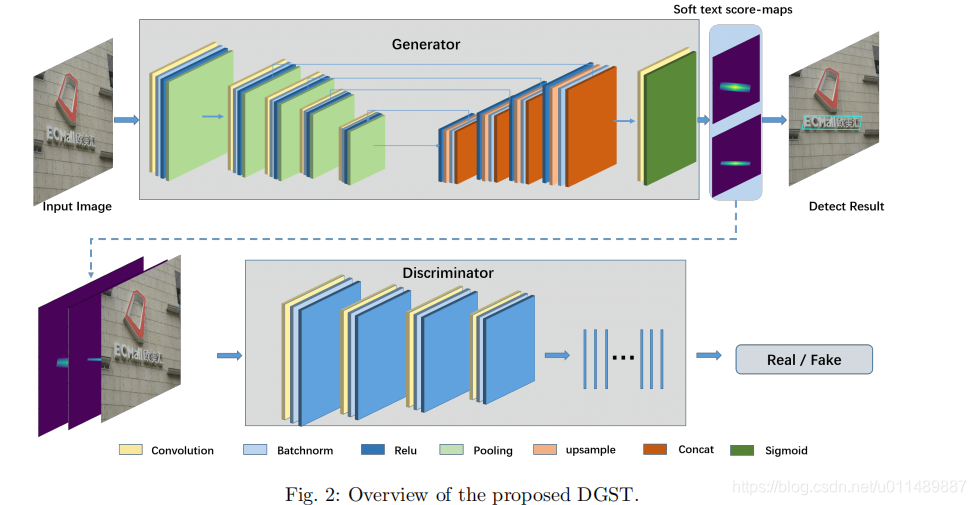
该网络是一个一阶段的检测器。在训练过程中,生成器与判别器交替的进行学习,最终生成器将输入图像转换成相应的soft-text-score图。这消除了中间步骤,像候选框生成以及NMS。后处理阶段只包含了文本分数图的连接组件分析。
Label Generation
经典的一阶段检测方法像EAST,PSENET等都是生成二值文本分数图。然而这种方法有缺陷。背景像素会影响文本特征的学习。这些方法试图缩小文本标注区域以减少背景像素。如下图
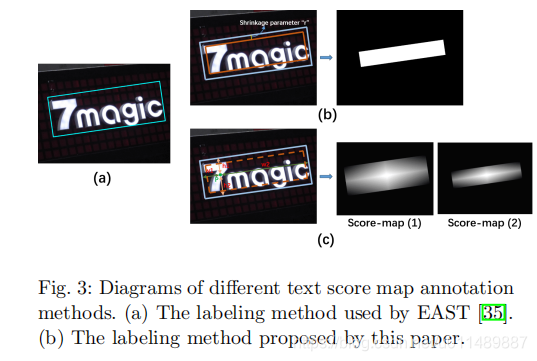
然而这种死板的方法不能精确的调整每一个框,而且文本边缘和背景像素不能很好的区分。CRAFT虽然分离每一个字符但减弱了单词的整体的关联。
这篇论文,受以上方法的影响,我们提出一个方法来生成文本分数图基于标注框里的像素与对应边框的距离。突出中央像素,弱化边缘像素。对于输入图像的一个点(x,y),soft-text-score中的P按照以下公式计算:
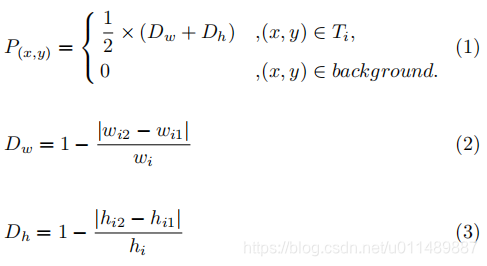
其中T表示所有的标注框,wi和hi表示文本框的宽和高。wi1,wi2, hi1, hi2表示该点距离每一个边的距离。Dw 和 Dh计算灰度值,该值从中央到边缘逐渐减少,如图3b所示。
所有的像素值是在0和1之间。为了解决紧密链接的文本区域,我们生成两个不同水平的分数图。分数图2进行缩小以便两个不同的文本框有更大的间距,在实验中缩小因子是0.2。
Network Design
Generator and discriminator
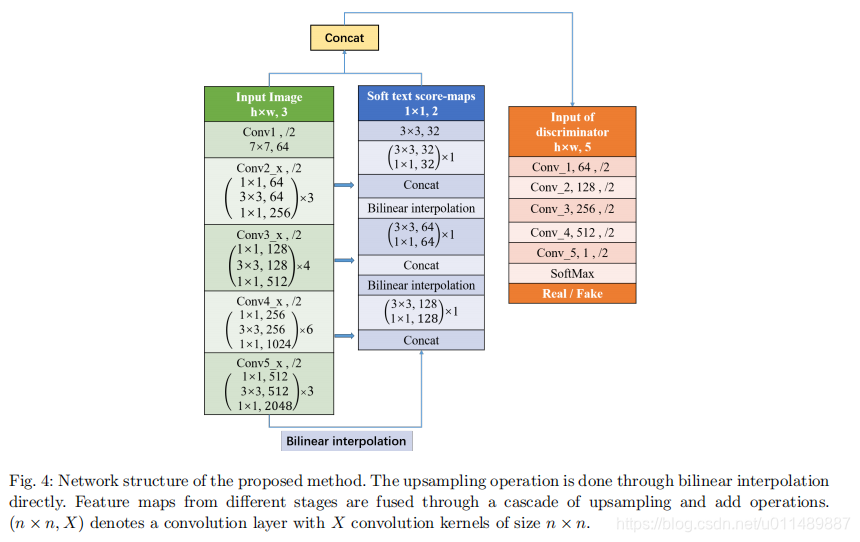
 我们使用U型结构,resnet50作为基本骨架,Conv2 x, Conv3 x, Conv4 x, Conv5 x特征图通过上采样进行结合。从一个输入图像,5种不同水平的特征图生成最终的特征图。在判别器的帮助下,生成器输出两通道的与原图大小相同的特征图对应不同尺度的文本分数图。因此文本检测任务转换成一个图像生成任务。输入一个图像和文本分数图,判别器来判别输入的文本分数图是真实的,还是生成的。一个更加详细的结构如图4所示。我们用双线性插值来代替反卷积以避免棋盘效应。绿蓝是生成器,橘黄色是判别器。
Loss function
传统的GAN是由判别器和生成器进行博弈学习,他们的损失函数如下:
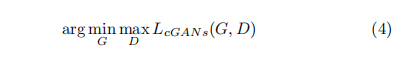
为了更加精确的获得分数图,我们用下列两种方法在GAN的基础上加强生成器。
1.cGAN被引用,添加输入图片作为限制,以便生成的输出被限制,更加合理的图片可以获得。损失函数如下:
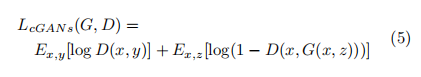
2.在GAN损失的基础上,L2损失被引入以优化预测的文本分数图,这种策略不仅能欺骗判别器也能使传统的损失表现的更好。

最终的损失函数如下:
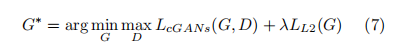
Text boxes extraction
图6展示了整个后处理流程。

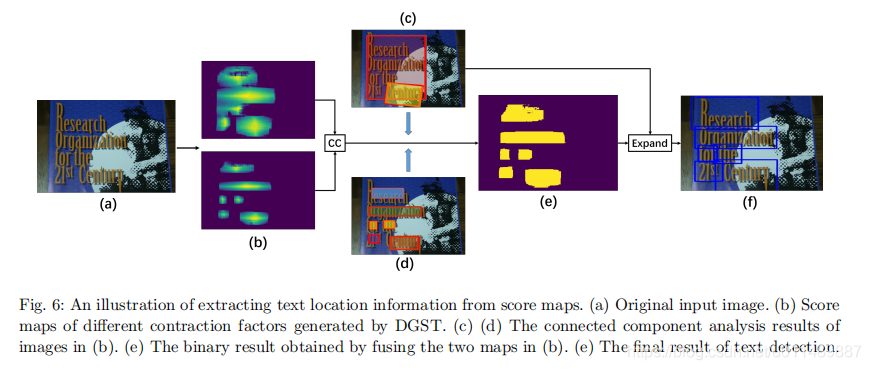
生成器获得两个不同缩减尺寸的文本分数图以及对应的文本框。可以看出没有缩减的文本分数图存在粘连问题,缩减的文本分数图可以更好的提取空间位置信息,但失去了一些文本信息。因此我们结合两个文本分数图得到一个更加完整的图形如图6e,在6c的限制下扩展6e这样能更加完整的包围整个文本区域。更加详细的流程如算法1所示:

Mscore1 和 Mscore2 分别代表不同缩减尺寸的分数图。Bs1 和 Bs2分别代表对应的二值图片。我们对分数图引进了阈值参数t,实验中t设置为0.25。相关的操作如阈值和连接组件分析可以调用opencv的方法。
EXPERIMENT
为了验证提出方法的有效性,我们在ICDAR13、15、17和MSRA-TD500进行了实验,并获得了state-of-the-art的性能。
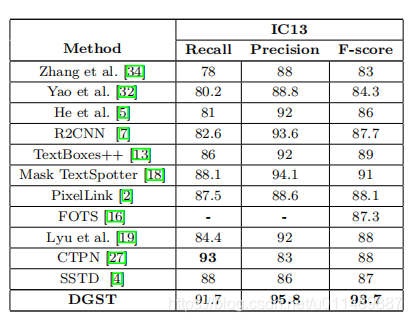

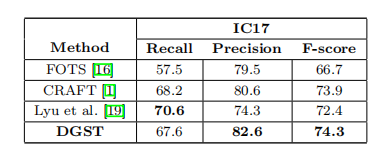

在IC17上训练200个epoch获得最终的检测器,测试时固定图像的长边到2560,获得了74.8%的F分数。ICDAR15是在IC17的基础上进行微调,训练80个epoch,固定图像的长边为2240获得了87.1%的F分数。IC13也是微调,测试时固定长边为960获得了87.1%的F分数。MSRA-TD500是单独训练,固定长边1600。