Feature Pyramid Based Scene Text Detector
刊物:ICDAR 2017
作者:MengYi En,Beijing University of Technology
内容:OCR,多尺度场景下的文本检测
Abstract
问题:CNN网络在文本检测时,高层特征图丢失低层细节,导致小目标检测效果差。
本文方案:提出一种基于特征金字塔的文本检测器(Feature Pyramid based Text Detector,FPTD)。该框架基于SSD(Single Shot Detector)目标检测算法,但同时结合特征金字塔思想,采用一种自上向下的特征融合策略,获取新的特征,既包含高层分辨能力强的语义信息特征又包含低层高分辨率且细节完整的特征。
大致流程:文本检测会在多个融合的特征上独立发生,结果再汇集之后进行非最大值抑制(Non-maximum Suppression,NMS),由于特征图来自不同层,它们都包含了高层的语义信息,且尺度不同,所以该框架能够处理不同尺度场景下的文字检测。
实验结论:本文框架在增加微弱额外开销的情况下,在ICDAR2013文本标定数据集上取得很好的效果。
ps:其实本文就是FPN网络在OCR领域的应用。本文的框架思想是完全借鉴于特征金字塔网络的。
Feature Pyramid Networks for Object Detection,CVPR2017
Introduction
相比传统的OCR(optical character recognition),复杂场景下的文本定位和识别存在很多困难,如文字失真扭曲
、图像模糊、光线不均、背景复杂、字符交错、颜色尺寸及文字方向多变等问题。
CNN具有强大的特征学习能力,但是在多尺度检测问题上存在不足。本文提出一种融合高低各层特征图的特征金字塔方法用于不同尺度的场景文本的检测。
本文主要贡献:
- 提出了新的端到端的多尺度场景文本的检测框架
- 首次将特征金字塔引入到场景文本检测领域
Related Work
主要介绍介绍三个方面的相关研究进展——基于深度网络的物体检测算法、场景文本检测算法和多尺度特征问题。
深度网络的目标检测算法
- R-CNN。CNN用于Object detection的开山之作,获得巨大的准确率提升,但时间开销巨大。
- Fast R-CNN。每张图只提取一次特征图,从而提升了检测算法的速度。
- Faster R-CNN,引入区域推荐网络(Region Proposal Network,RPN),速度再次提升基本达到实时。
- YOLO。将目标检测看作回归问题,输入整幅原图直接预测物体边界框(Bounding Boxes),并在最上层的特征图(Feature Map)上进行类别可能性的预测。虽然牺牲部分精度,但达到实时速度。
- SSD。不同层采用针对多尺度特征设计好的不同锚点框(anchor boxes)进行区域推荐。极大的提高了检测准确率同时保持算法的高效。
得益于近年来物体检测算法的发展,基于深度网络的场景文本检测算法逐渐流行。
- 《Serge Belongie. Detecting Oriented Text in Natural Images by Linking Segments》。全卷积网络(Fully convolutional network,FCN)被引入用于文本的特征提取。且提出一种将文本分解为局部的两个可检测的元素,segments(碎片)和links(连接),同时在CNN中进行预测,之后再联合得到最终的检测结果。
- 《Deeptext: A unified framework for text proposal generation and text detection in natural images》提出了基于Faster R-CNN的文本检测框架,该文设计了一种inception-RPN,用多尺度卷积核进行文本区域的提议。
- 《Arbitrary-Oriented Scene Text Detection via Rotation Proposals》提出了基于Faster R-CNN检测多方向文本的框架。
- 《A Fast Text Detector with a Single Deep Neural Network》、《Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection》 基于SSD进行多方向文本检测。
目标检测中的多尺度问题
传统方式是将图像金字塔作为输入,但是深度网络中多尺度图片同时输入对内存消耗太高。GoogLeNet采用在单尺度图像上进行多尺度滤波来解决多尺度问题。Faster R-CNN通过引入多尺度和不同aspect ratio的anchor boxes来处理不同尺度问题,但由于其特征图来自最后的卷积层,导致分辨率粗糙,影响小目标的检测性能。
FCN、HyperNet、ParseNet、RCF及FPN等方法被提出以解决目标识别中的尺度问题。
Methodology
1. CNN体系
本文提出的FPTD如下图所示。其基于SSD框架,采用VGG-16网络,但是fc6和fc7由全连接层变成卷积层,然后增加额外的层(从conv6_1到pool6)
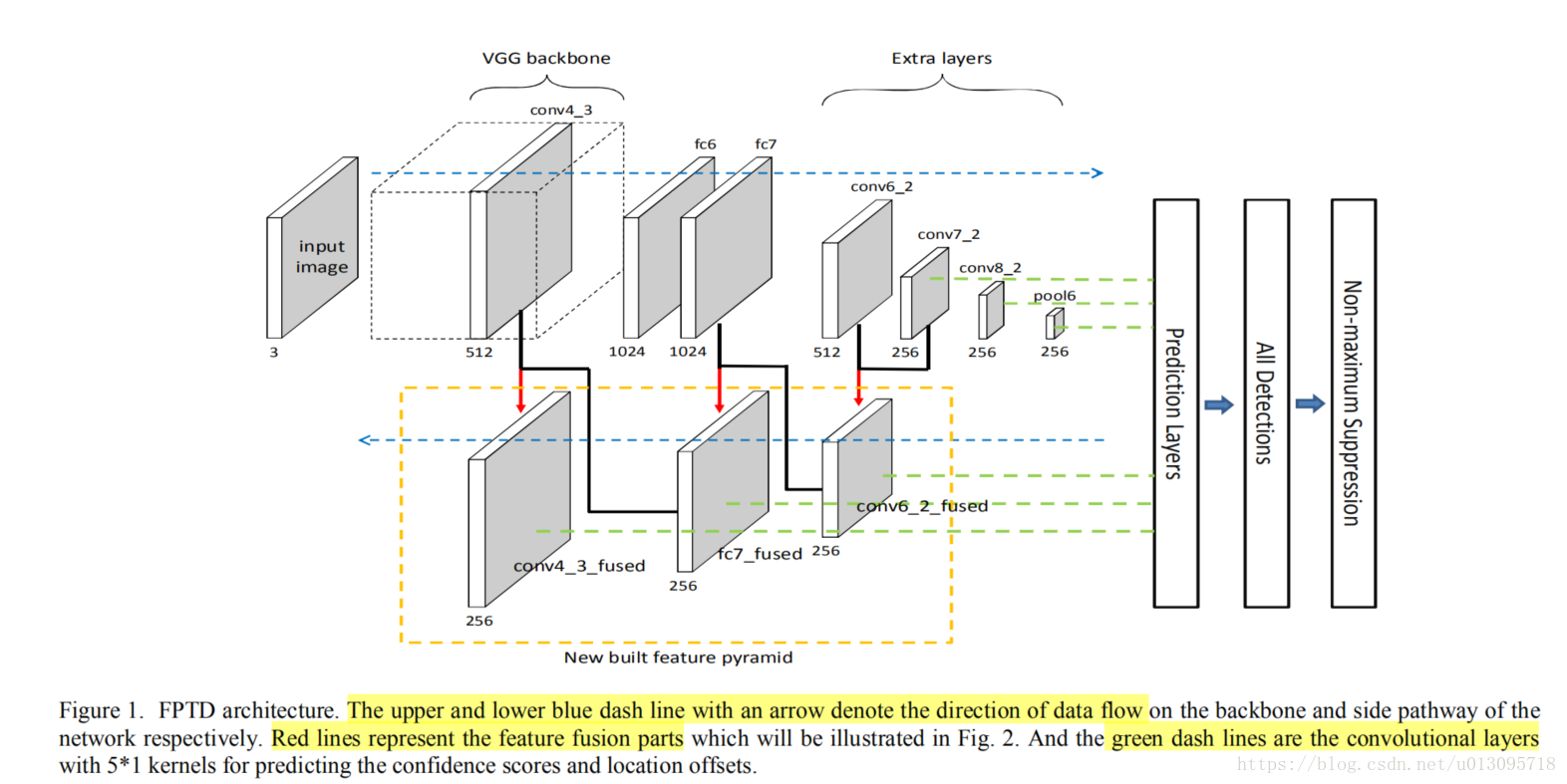
网络主体的旁边添加了数个新的层,形成一条旁路。包括反卷积层,元素累加层及构建新特征的层。图片进入网络会经过网络的两个路径。网络的主框架(backbone)完成特征的提取,而旁路层构建新的特征。
随着网络加深,主架上提取的特征分辨率降低,底层细节逐渐丢失,但语义加强。从不同的网络层对应的旁路上的构建新特征形成了一个特征金字塔。
2. 构建新的特征金字塔的策略
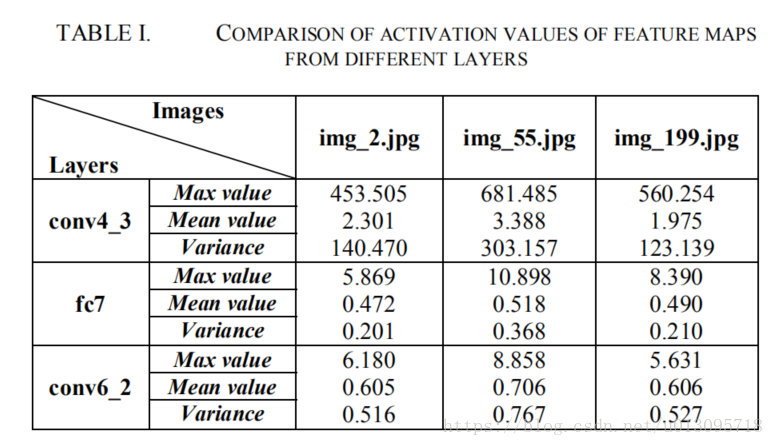
采用高层和低层融合的方式得到空间细节饱满同时语义信息丰富的特征。但是,融合不同层特征图面对一个问题:不同层的特征图通常在尺度和规模上差异明显(统计各层的activation可得,见下图Table1)。比如直接融合高层和低层得特征图,则得到得结果特征图由“大值”主导(即值小的那层的信息作用甚微)。
下图说明了特征融合的过程。首先将高层低分辨率的特征图反卷积,这样两部分尺寸(分辨率)契合。再对高分辨率的低层特征图做 的卷积。最后两部分按元素相加。再对结果做一个 的卷积得到最终融合的特征图。
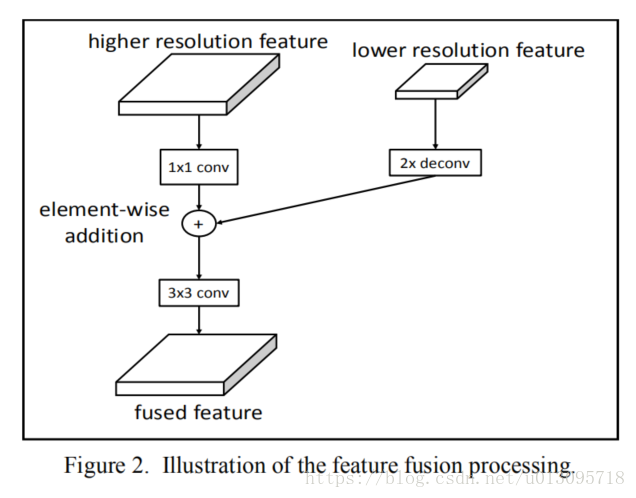
此处 的卷积作用如下:
- 统一不同层的通道数。(3维上的卷积?得到一个单通道的特征图?)
- 将不同层的特征图的值调整到合适的范围内。
下图可见经过 的卷积,不同层的activation的统计量基本达到相似范围。
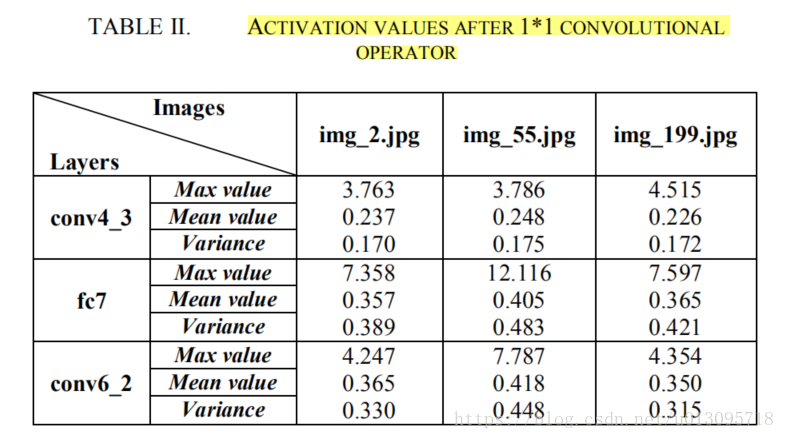
之后再通过一个 的卷积抽取更多语义信息,同时减小上采样带来的不利影响。
3. 文本检测
- 选用主架网络上的pool6,conv8_2,conv7_2层,以及旁路网络上的new built conv6_2,new built fc7 和new built conv7_2层的特征图进行文本检测。
- 特征图上的每个位置(pixel)都关联着一系列prior boxes。每个prior boxes都覆盖着输入图像的一部分区域。
- 每一个被用作检测的特征图都连接着两个 的卷积层,一个用做预测每个prior box的自信度得分。一个用作预测坐标的补偿(调节prior box大小)。
4. 学习过程
loss function由分类loss和定位loss组成:
N是正prior boxes样本数, 采用L1 loss, 采用2分类的softmax loss。a是权重项,这里设为1。
Experiments
对ICDAR 2013的文本定位任务进行了一系列实验,采用场景文本数据库。评估协议是ICDAR2013的评估尺度。
1. Dataset
使用两个数据集进行整个实验。
- SynthText:人工合成的数据集。包含80万张图片,8百万合成的文本语句实例。该数据集用来预训练模型。
- ICDAR 2013:该数据集包含229张图用于训练,223张图用于测试。在预训练的模型上进行fine-tune,然后用ICDAR 2013数据集的测试集评估模型。
2. Implementation Details
- FPTD采用在ILSVRC CLS-LOC数据集上预训练好的VGG-16模型,训练采用 的单尺度图片。
- 采用小批次随机梯度下降优化算法(Mini-batch stochastic gradient descent,MSGD)。
- Momentum设为0.9,weight decay设置为 .
- 训练第一阶段:用预训练好的VGG-16模型初始化网络,然后再SynthText数据集上进行55000次迭代训练,前35000次迭代学习率为0.001,接下来5000次迭代学习率为0.0005,最后的15000次迭代采用0.0001的学习率。
- 训练第二阶段:在ICDAR 2013数据集上进行1000次fine-tune
- 由于特征图融合的过程采用元素相加操作,所以FPTD的输入图像尺寸必须是2的幂次方(防止上下采样丢失尺寸,从而无法进行融合)。
3.Experiments for verifying the effectiveness of the new build features
使用TextBox作为基准模型。测试结果如下
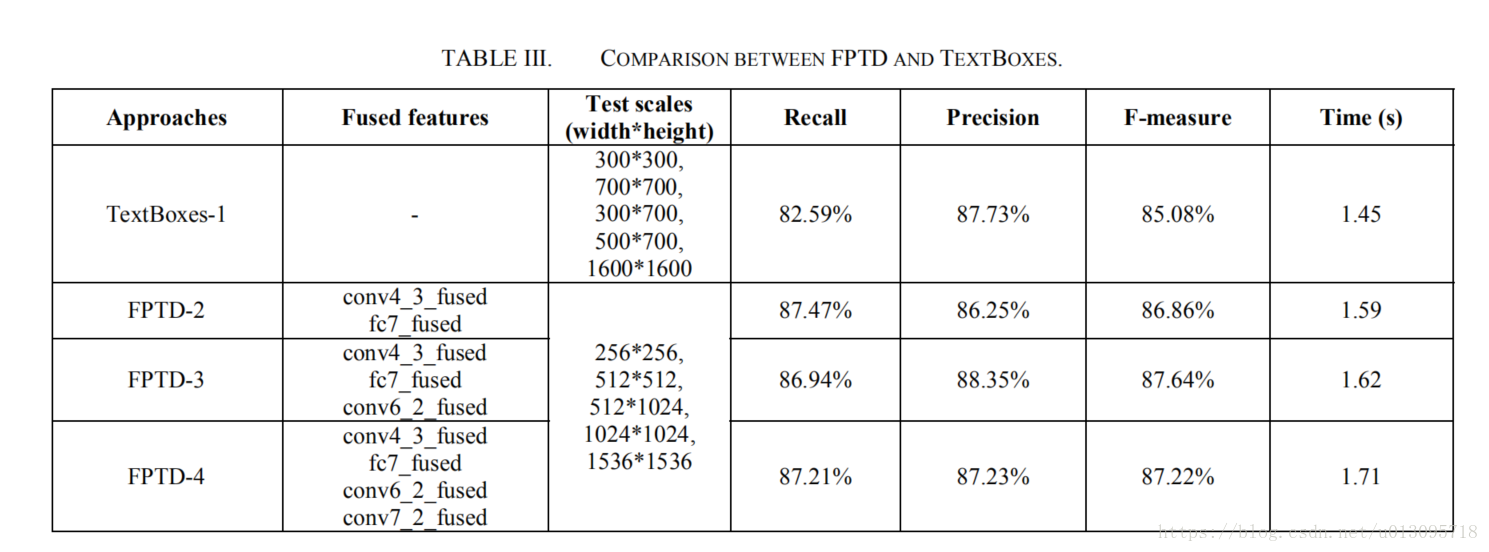
4. Experiments for detecting small text
- 为了检测小目标,我们构建了FPTD-5,在旁路上增加了conv3_3层。
- 测试的时候,为了增加小目标,我们将测试图片缩小到
- 同样,TextBox模型也用256的图片作为输入(TextBox-2)。

5.Comparisions with other state-of-the-art methods
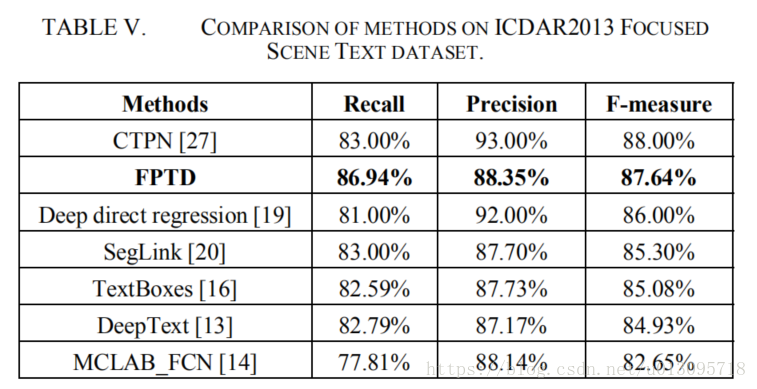
此处FPTD采用的是实验中FPTD-3,本文的方法获得更高的召回率,同时F-measure指标也很不错。
ps:本文偏重于工程实现,创新新并不强,这种情况下,实验的充分与否就很重要了。