目录
架构原理总图

一、Hadoop的历史
-> 1.0版本
· 2003年、2004年,google的两篇论文奠定了hadoop的基础思想;
Hadoop起源以及Google三篇论文介绍(三篇论文其中一篇讲分布式文件系统,诞生了HDFS,另一篇讲分布式计算模型,诞生了MapReduce,最后一篇是BigTable)
· 2006年Apache基金会将Hadoop作为一个项目开始研发;
· 2011年Hadoop1.0版本发布,由分布式存储系统HDFS(NameNode、DateNode)和分布式计算框架MapReduce(JobTracker、TaskTracker)组成;
· 2012年3月,Hadoop稳定版发布
-> 缺点
(1)NameNode是单点操作,容易出现单点故障,不支持高可用HA,制约了HDFS的发展,因为一旦单点的NameNode不可用导致整个HDFS直接不可用;
(2)NameNode的内存限制影响了HDFS的发展;
(3)MapReduce的初衷是进行单一数据计算,仅有一个Mapper-Reduce过程,拿到数据后打散,然后计算后再聚合;如果reducer的结果需要继续进行MR操作,不支持;如果迭代计算就需要再一次进行Mapper-Reduce过程;
Mapper从HDFS获取数据IO一次,Mapper到Reducer中间Shuffle会IO一次,Reducer数据存储到HDFS又IO一次,也就是说进行一次Mapper-Reduce需要IO三次,性能非常慢,所以1.0版本Hadoop一般只进行单一数据计算,而不支持迭代计算。

(4)MR框架中资源调度存在很大的问题,JobTracker也是单点不支持HA,它同时做资源调度和任务调度,任务量非常大;这样在MR框架中资源调度和任务调度耦合在一起,无法扩展。

-> 2.0版本
由于Hadoop1.X版本存在HDFS单点式NameNode和MapReduce的双重缺陷,发布了新的版本来改善这种情况
· 2013年10月,Hadoop2.X版本发布,版本最大的变化是加入了Yarn(ResourceManager、NodeManager)
(1)首先2.X通过zookeeper实现了NameNode的高可用,1.X版本只有一个NameNode,2.X版本可以支持多个NameNode了;
(2)然后2.X版本支持Yarn资源调度框架,只做资源调度,不做任务调度;
(3)2.X版本中MR框架只做任务调度,这样1.X版本MR又做资源调度又做任务调度的耦合性就解决了;
(4)2.X版本中,MR可插拔,所以扩展性非常强。
ps:因为资源调度被Yarn管理,所以Hadoop生态中可以不使用MR框架进行任务调度,实现了计算框架的可插拔性,像现在引入Spark到Hadoop中作为任务计算框架就是得益于此。
-> MapReduce架构组成:
(1)MRAppMaster:负责整个程序的过程调度和状态协调,即任务调度;
(2)Map Task:负责Map阶段的整个数据处理流程;
(3)Reduce Task:负责Reduce阶段的整个数据处理流程。
-> Yarn架构组成和运行原理:
(1)ResourceManager(RM),这个实体控制整个集群并管理应用程序向基础计算资源的分配,承担了1.X版本Job Tracker的角色;
处理客户端请求,启动和监控ApplicationMaster,监控NodeManager,资源的分配与调度
(2) ApplicationMaster(AM),负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配),承担了1.X版本Task Tracker的部分角色;
负责数据的切分,为应用程序申请资源并分配给内部的任务,任务的监控与容错
(3)NodeManager(NM),管理Yarn集群中每个节点的资源,处理来自RM和AM的命令;
(4)Container,容器,它封装了某个节点上的多维度资源,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的;YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
ps:由于NodeManager是资源框架,Container中是计算框架,所以两者分开避免了耦合性,实现了计算框架的可插拔性,在NodeManager资源框架环境下,Container中的计算框架可以是MR也可以是Spark等
ps:RM控制整个集群的资源分配与调度,
AM为任务向RM申请资源,RM返回的资源以Container封装表示,
AM再将Container分配给NM,
NM对Container中资源的使用和执行进行监控和管理,
具体的计算框架在Container中实现,调用Container的资源环境。
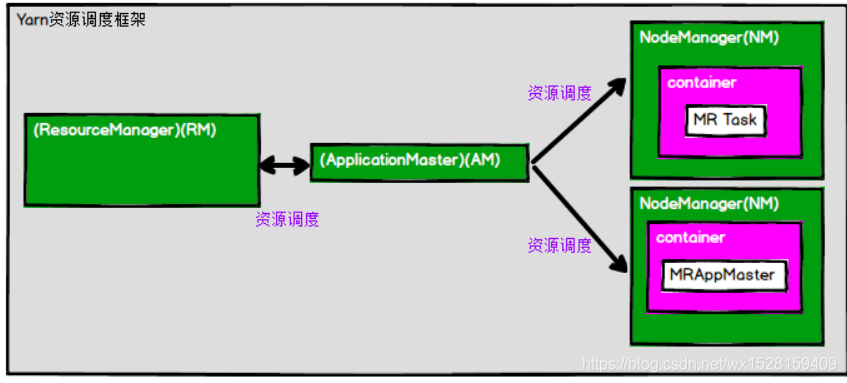
绿色部分是Yarn,表示资源调度,
Container里紫色部分表示资源环境,白色部分是任务调度,由MR框架组成,
任务调度由MRAppMaster实现,MR Task与其共同构成计算框架;
由于资源调度与任务调度耦合性解除,Container的计算框架也可以用Spark等,实现了计算框架的可插拔性。
这一版本2.X也是目前最通用的Hadoop版本,但是由于2013年6月份Spark发布,2013年10月Hadoop2.X版本发布,所以Spark在计算框架领域已经占得先机了。
二、Spark的历史
正是因为Hadoop1.X版本MR的缺点,诞生了Spark这个效率更高更强大的分布式计算框架;
· 2009年Spark诞生于加州大学伯克利分校AMPLab,项目采用Scala语言编写;
· 2010年开源;
· 2013年6月,由于Hadoop1.X版本中MR的缺点,Spark成为Apache孵化项目;
· 2014年2月,Spark成为Apache的顶级项目
-> Spark架构组成
(1)Master是资源调度管理器,
(2)ApplicationMaster类似Yarn中Application,应用管理器,为节点向Master申请资源并分配给Worker,
(3)Worker是工作节点,具备工作的资源环境,
(4)Executor实现计算任务。

Spark中数据操作走向,与Hadoop中MR框架的区别是,每一个MR过程是连接在一起的,数据并没有存储到HDFS中,在mapper和reducer中间是shuffle阶段,这一阶段数据处理完毕后可能会落盘;Spark的数据既可以保存在内存中也可以保存在磁盘中;
Spark使用Scala语言支持迭代计算和图形计算,并且由于Spark基于内存计算,避免了MR中的IO,所以Spark的执行效率非常高;
(1)落盘的情况下,Spark数据处理比Hadoop快近10倍,
(2)不落盘基于内存运算的情况下,Spark数据处理比Hadoop快近100倍。
ps:RDD是直接缓存在Executor进程中的,所以任务在运行时可以充分利用缓存数据加速运算,这也是Spark在内存中计算的原理。
-> Driver和Executor
在API开发中,Spark的驱动器Driver,就是执行开发程序中的main方法的进程,也就是声明SparkContext的那个方法;它负责开发人员编写的用来创建SparkContext、创建RDD,以及进行RDD的转化操作和行动操作代码的执行,它对标ApplicationMaster。
Executor执行器,是一个工作进程,负责在 Spark 作业中运行任务,任务间相互独立。如果Executor节点出现故障,Spark会将出错节点上的任务调度到其他Executor节点继续运行,实现了高可用和负载均衡;它对标Spark架构图中的Executor。