Spark简介
Spark 是一个用来实现快速而通用的集群计算的平台。
在速度方面,Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。在处理大规模数据集时,速度是非常重要的。速度快就意味着我们可以进行交互式的数据操作,否则我们每次操作就需要等待数分钟甚至数小时。Spark 的一个主要特点就是能够在内存中进行计算,因而更快。不过即使是必须在磁盘上进行的复杂计算,Spark 依然比 MapReduce 更加高效。
总的来说,Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark使我们可以简单而低耗地把各种处理流程整合在一起。而这样的组合,在实际的数据分析过程中是很有意义的。不仅如此,Spark 的这种特性还大大减轻了原先需要对各种平台别管理的负担。Spark 所提供的接口非常丰富。除了提供基于 Python、Java、Scala 和 SQL 的简单易用的API 以及内建的丰富的程序库以外,Spark 还能和其他大数据工具密切配合使用。例如,Spark 可以运行在 Hadoop 集群上,访问包括 Cassandra 在内的任意 Hadoop 数据源。
- 总结
Spark是一个快如闪电的统一分析引擎(计算框架)用于大规模数据集的处理。Spark在做数据的批处理计算,计算性能大约是Hadoop MapReduce的10~100倍,因为Spark使用比较先进的基于DAG 任务调度,可以将一个任务拆分成若干个阶段,然后将这些阶段分批次交给集群计算节点处理。
- MapReduce VS Spark
MapReduce作为第一代大数据处理框架,在设计初期只是为了满足基于海量数据级的海量数据计算的迫切需求。自2006年剥离自Nutch(Java搜索引擎)工程,主要解决的是早期人们对大数据的初级认知所面临的问题。

整个MapReduce的计算实现的是基于磁盘的IO计算,随着大数据技术的不断普及,人们开始重新定义大数据的处理方式,不仅仅满足于能在合理的时间范围内完成对大数据的计算,还对计算的实效性提出了更苛刻的要求,因为人们开始探索使用Map Reduce计算框架完成一些复杂的高阶算法,往往这些算法通常不能通过1次性的Map Reduce迭代计算完成。由于Map Reduce计算模型总是把结果存储到磁盘中,每次迭代都需要将数据磁盘加载到内存,这就为后续的迭代带来了更多延长。
2009年Spark在加州伯克利AMP实验室诞生,2010首次开源后该项目就受到很多开发人员的喜爱,2013年6月份开始在Apache孵化,2014年2月份正式成为Apache的顶级项目。Spark发展如此之快是因为Spark在计算层方面明显优于Hadoop的Map Reduce这磁盘迭代计算,因为Spark可以使用内存对数据做计算,而且计算的中间结果也可以缓存在内存中,这就为后续的迭代计算节省了时间,大幅度的提升了针对于海量数据的计算效率。

Spark也给出了在使用MapReduce和Spark做线性回归计算(算法实现需要n次迭代)上,Spark的速率几乎是MapReduce计算10~100倍这种计算速度。

不仅如此Spark在设计理念中也提出了One stack ruled them all战略,并且提供了基于Spark批处理至上的计算服务分支例如:实现基于Spark的交互查询、近实时流处理、机器学习、Grahx 图形关系存储等。

从图中不难看出Apache Spark处于计算层,Spark项目在战略上启到了承上启下的作用,并没有废弃原有以hadoop为主体的大数据解决方案。因为Spark向下可以计算来自于HDFS、HBase、Cassandra和亚马逊S3文件服务器的数据,也就意味着使用Spark作为计算层,用户原有的存储层架构无需改动。
计算流程
因为Spark计算是在MapReduce计算之后诞生,吸取了MapReduce设计经验,极大地规避了MapReduce计算过程中的诟病,先来回顾一下MapReduce计算的流程。
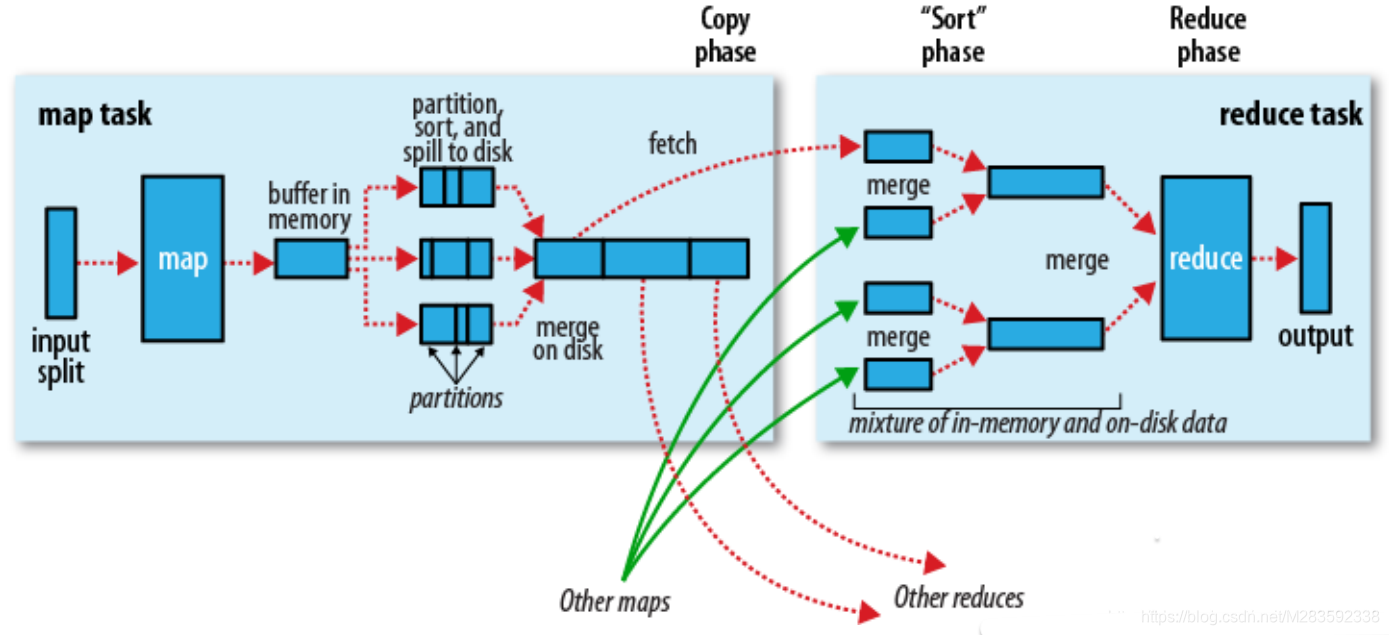
总结一下几点缺点:
1)MapReduce虽然基于矢量编程思想,但是计算状态过于简单,只是简单的将任务分为Map state和Reduce State,没有考虑到迭代计算场景。
2)在Map任务计算的中间结果存储到本地磁盘,IO调用过多,数据读写效率差。
3)MapReduce是先提交任务,然后在计算过程中申请资源。并且计算方式过于笨重。每个并行度都是由一个JVM进程来实现计算。
通过简单的罗列不难发现MapReduce计算的诟病和问题,因此Spark在计算层面上借鉴了MapReduce计算设计的经验,提出了DGASchedule和TaskSchedual概念,打破了在MapReduce任务中一个job只用Map State和Reduce State的两个阶段,并不适合一些迭代计算次数比较多的场景。因此Spark 提出了一个比较先进的设计理念,任务状态拆分,Spark在任务计算初期首先通过DGASchedule计算任务的State,将每个阶段的Sate封装成一个TaskSet,然后由TaskSchedual将TaskSet提交集群进行计算。可以尝试将Spark计算的流程使用一下的流程图描述如下:

相比较于MapReduce计算,Spark计算有以下优点:
1)智能DAG任务拆分,将一个复杂计算拆分成若干个State,满足迭代计算场景
2)Spark提供了计算的缓存和容错策略,将计算结果存储在内存或者磁盘,加速每个state的运行,提升运行效率
3)Spark在计算初期,就已经申请好计算资源。任务并行度是通过在Executor进程中启动线程实现,相比较于MapReduce计算更加轻快。
目前Spark提供了Cluster Manager的实现由Yarn、Standalone、Messso、kubernates等实现。其中企业常用的有Yarn和Standalone方式的管理。
- Application就是你写的代码。
- Driver节点上的Driver程序运行的是main函数
- Worker节点就是工作节点,上面运行Executor进程。
- Executor进程负责运行Task。