-
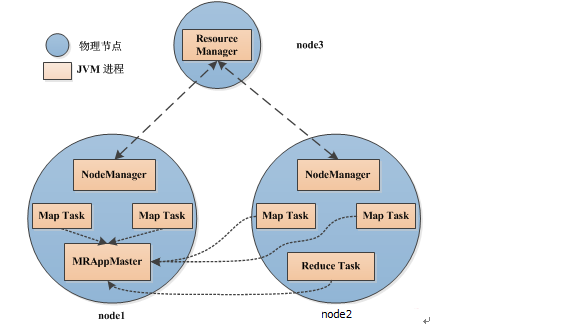
MapReduce 多进程模型:MapReduce 应用程序是让每个Task 动态申请资源,且运行完后马上释放资源
-
- 每个Task 运行在一个独立的JVM 进程中
-
- 可单独为不同类型的Task 设置不同的资源量,目前支持内存和CPU 两种资源
-
- 每个Task 运行完后,将释放所占用的资源,这些资源不能被其他Task 复用,即使是同一个作业相同类型的Task。也就是说,每个Task 都要经历“申请资源—> 运行Task –> 释放资源”的过程
-
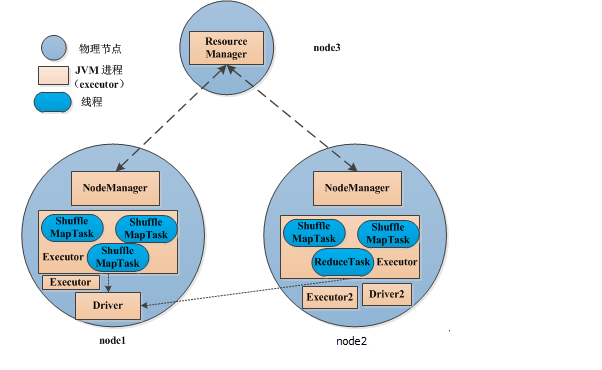
Spark 多线程模型:第一步是构建一个可重用的资源池,然后在这个资源池里运行所有的ShuffleMapTask 和ReduceTask
-
-
每个节点上可以运行一个或多个Executor 服务
-
每个Executor 配有一定数量的slot,表示该Executor 中可以同时运行多少个ShuffleMapTask 或者ReduceTask
-
每个Executor 单独运行在一个JVM 进程中,每个Task 则是运行在Executor中的一个线程
-
同一个 Executor 内部的 Task 可共享内存, 广播的文件或者数据结构只会在每个Executor 中加载一次,而不会像MapReduce 那样,每个Task 加载一次
-
-