一、grep,egrep命令
1、 Grep定义
grep 命令是一种强大的文本搜索工具,根据用户指定的“模式”对目标文本进行匹配检- 查,打印匹配到的行
由正则表达式或者字符及基本文本字符所编写的过滤条件
Global search regular expression and print out the line
全面搜索研究正则表达式并显示出来
2、grep使用
grep
-i ##忽略字母大小写
-v ##条件取反
-c ##统计匹配行数
-q ##静默,无任何输出
-n ##显示匹配结果所在的行号
-q:
[root@localhost mm]# grep '172.25.254.33' /etc/hosts && echo 'YES' || echo 'NO'
NO
[root@localhost mm]# grep '172.25.254.250' /etc/hosts && echo 'YES' || echo 'NO'
NO
[root@localhost mm]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@localhost mm]# grep '127.0.0.1' /etc/hosts && echo 'YES' || echo 'NO'127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
YES
[root@localhost mm]# grep -q '127.0.0.1' /etc/hosts && echo 'YES' || echo 'NO'
YES
-c
[root@localhost mm]# egrep -c '/sbin/nologin' /etc/passwd
36
基本元字符:^ $
[root@localhost mm]# touch file
[root@localhost mm]# vim file
[root@localhost mm]# cat file
westos root
westos qw root
westos er root
wes daw root 1
ewdw dewevc root
dfs dsfsdf frew r=westod
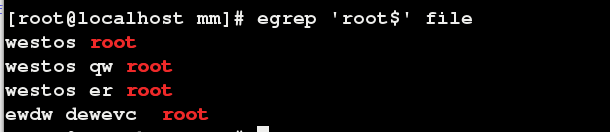
. 过滤非空行
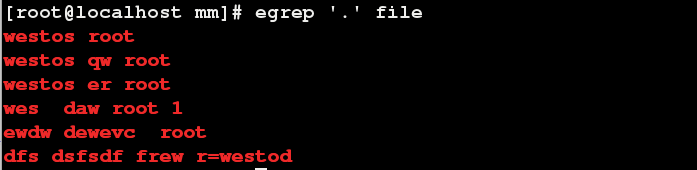
过滤空行
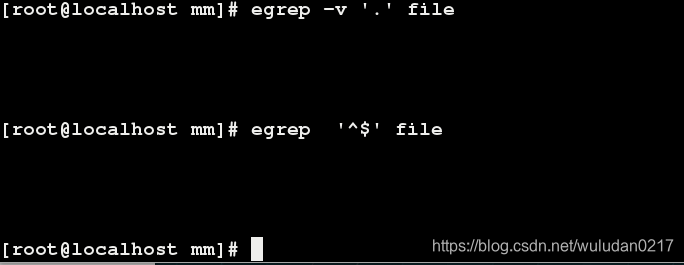
**基本元字符: + ? ***
[root@localhost mm]# cat file
wessssstos root
westoss qw rsssoot
westsoss er root
wes daw rootss 1
ewdw dewevc root
dfs dsfsdf frew r=westod
[root@localhost mm]#
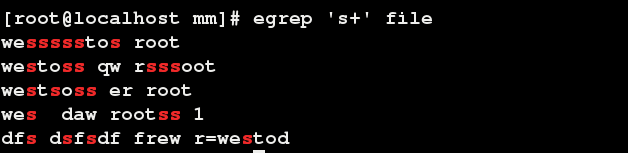
egrep ‘s+’ file 输出包括s,ss,ss…,即至少出现一次
egrep ‘color(root)?’ 1.sh 末尾的root最多出现一次,也可以没有

元字符:{}
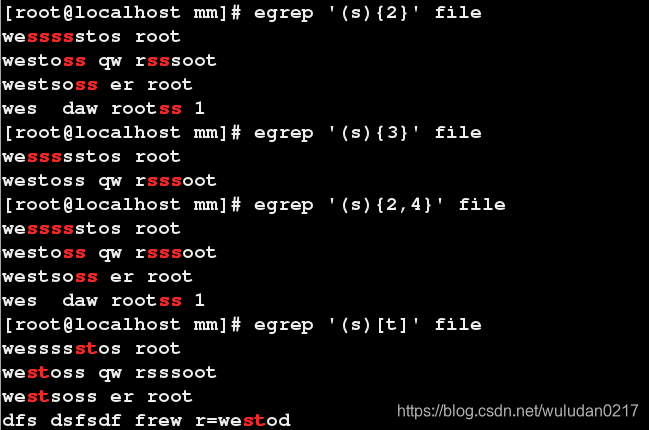
二、cut命令
cut -d ##指定分隔符
cut -d : -f 1-3 /etc/passwd ##指定分隔符为:,显示第1到3列
cut -c 1,4 /etc/passwd ##显示第一和第四个字符
练习:获取主机IP
[root@localhost mm]# ifconfig eth0 | grep "inet " | awk '{print $2}'
172.25.254.33
[root@localhost mm]# ifconfig eth0 | grep "inet " | cut -d " " -f 10
172.25.254.33
练习:检测网络
[root@localhost mm]# vim westos2.sh

[root@localhost mm]# sh westos2.sh 33
172.25.254.33 is up
[root@localhost mm]# sh westos2.sh 68
172.25.254.68 is up
[root@localhost mm]# sh westos2.sh 9
172.25.254.9 is down
三、sort命令:排序
sort=
-n ##纯数字排序
-r ##倒序
-u##去掉重复数字
-o##输出到指定文件中
-t ##指定分隔符
-k ##指定要排序的列
[root@localhost mm]# cat file
21314132
11
13432
13242
324
242534
232
54654
34242
2425446
4556765
9765756
12
156
[root@localhost mm]# sort file
11
12
13242
13432
156
21314132
232
242534
2425446
324
34242
4556765
54654
9765756
[root@localhost mm]# sort -n file
11
12
156
232
324
13242
13432
34242
54654
242534
2425446
4556765
9765756
21314132
[root@localhost mm]# sort -u file
11
12
13242
13432
156
21314132
232
242534
2425446
324
34242
4556765
54654
9765756
[root@localhost mm]# cat file
2:3
23:12
34:1122
4:90
1:3
1:98
56:345
34:234
[root@localhost mm]# sort -t : -k 2 file
34:1122
23:12
34:234
1:3
2:3
56:345
4:90
1:98
[root@localhost mm]# sort -nt : -k 2 file
1:3
2:3
23:12
4:90
1:98
34:234
56:345
34:1122
四、uniq命令:对重复字符处理
uniq
-u ##显示唯一的行
-d ##显示重复的行
-c ##每行显示一次并统计重复次数
[root@localhost mm]# cat file
11
23
11
23
45
34
34
34
45
111
1
1
3
3
3
3
3
2
2
2
2
7
7
7
[root@localhost mm]# sort -n file | uniq -c
2 1
4 2
5 3
3 7
2 11
2 23
3 34
2 45
1 111
[root@localhost mm]# sort -n file | uniq -d
1
2
3
7
11
23
34
45
[root@localhost mm]# sort -n file | uniq -u
111
练习:将/tmp目录中的文件取出最大的
[root@localhost mm]# ls -l /tmp/ | head -2 | cut -d " " -f 9
ssh-aiE1xQ1RPl40