开篇词
我们可以借助 Linux 提供的 uniq、comm 命令来去重或比较文件的内容。
非重复结果
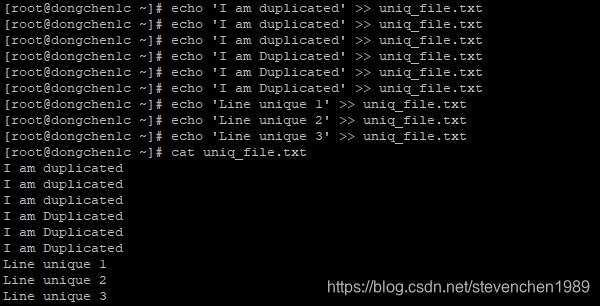
我们为 uniq 命令准备一些重复的以及非重复的内容:
echo 'I am duplicated' >> uniq_file.txt
echo 'I am duplicated' >> uniq_file.txt
echo 'I am duplicated' >> uniq_file.txt
echo 'I am Duplicated' >> uniq_file.txt
echo 'I am Duplicated' >> uniq_file.txt
echo 'I am Duplicated' >> uniq_file.txt
echo 'Line unique 1' >> uniq_file.txt
echo 'Line unique 2' >> uniq_file.txt
echo 'Line unique 3' >> uniq_file.txt
默认情况下,uniq 命令输出不包含其后的重复内容:
uniq uniq_file.txt

重复内容
我们可以加入 -d 或 --repeated 参数来输出文件的重复内容:
uniq -d uniq_file.txt
uniq --repeated uniq_file.txt

非重复内容
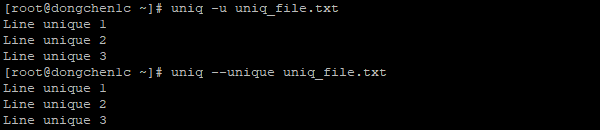
我们可以加入 -u 或 --unique 参数来输出文件的非重复内容:
uniq -u uniq_file.txt
uniq --unique uniq_file.txt
不区分大小写的重复内容
我们可以加入 -d 或 --repeated 加 -i 或 --ignore-case 参数来不区分大小写输出文件的重复内容:
uniq -d -i uniq_file.txt
uniq --repeated --ignore-case uniq_file.txt

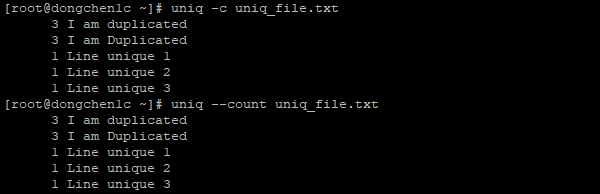
输出内容以及其出现次数
我们可以加入 -c 或 --count 参数来输出文件的重复内容及其出现次数:
uniq -c uniq_file.txt
uniq --count uniq_file.txt
对比结果
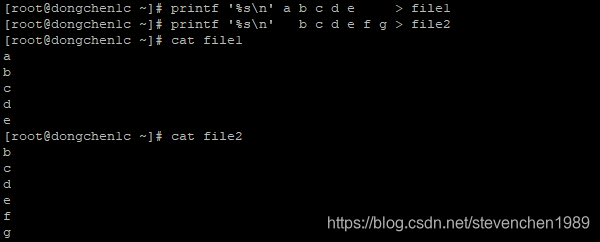
我们需要创建两个文件用以演示 comm 命令:
printf '%s\n' a b c d e > file1
printf '%s\n' b c d e f g > file2
cat file1
cat file2
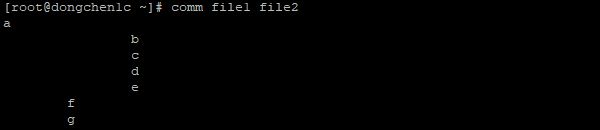
默认情况下,comm 输出三列数据,第一列是两个文件对比之后第一个文件里的非重复数据,第二列是对比之后第二个文件里的非重复数据,第三列是两个文件对比之后重叠的数据:
comm file1 file2
隐藏第一列
我们可以借助 -1 参数来隐藏第一列:
comm -1 file1 file2

隐藏第二列
我们可以借助 -2 参数来隐藏第二列:
comm -2 file1 file2

隐藏第三列
我们可以借助 -3 参数来隐藏第三列:
comm -3 file1 file2

显示第一列
我们可以借助 -23 参数来显示第一列:
comm -23 file1 file2

显示第二列
我们可以借助 -13 参数来显示第二列:
comm -13 file1 file2

显示第三列
我们可以借助 -12 参数来显示第三列:
comm -12 file1 file2

我所撰写的英文版本
25. Bash Shell - Text Processing: uniq, comm
引用
参见
想看手册的其他内容?请访问该手册的所属专栏:《Linux 管理员手册:既简单又深刻》
