目录
本篇汇总了Linux中的文本处理工具,也是shell脚本编程中经常要用到的工具,有些工具例如grep绝对是要重点掌握的,而有些工具例如paste个人觉得很鸡肋
一、grep 行过滤
grep是行过滤工具,根据关键字进行行过滤,这个命令可以结合正则表达式使用
常见选项:
OPTIONS:
-i: 不区分大小写
-v: 查找不包含指定内容的行,反向选择
-w: 按单词搜索
-o: 打印匹配关键字
-c: 统计匹配到的行数
-n: 显示行号
-r: 逐层遍历目录查找
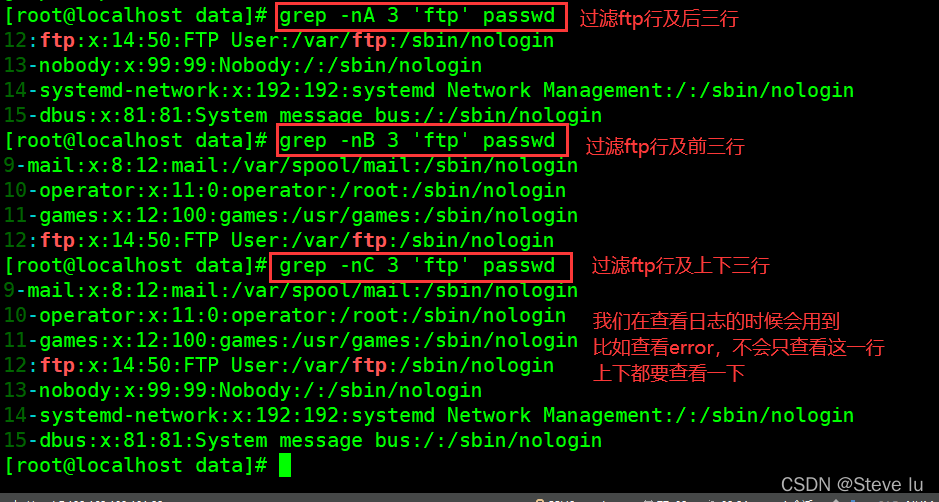
-A: 显示匹配行及后面多少行
-B: 显示匹配行及前面多少行
-C: 显示匹配行前后多少行
-l:只列出匹配的文件名
-L:列出不匹配的文件名
-e: 使用正则匹配
-E:使用扩展正则匹配
^key:以关键字开头
key$:以关键字结尾
^$:匹配空行
--color=auto :可以将找到的关键词部分加上颜色的显示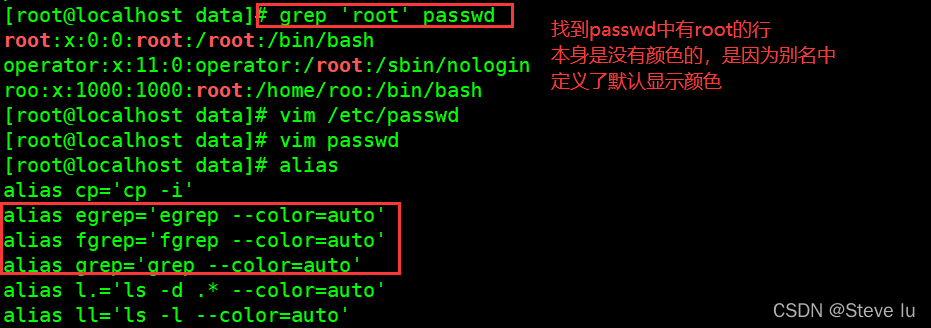




二、cut 列截取
cut命令有两个主要的功能,第一是显示文件内容,第二是连接多个文件
若不指定file参数,该命令将读取标准输入。 必须指定 -b、-c 或 -f 标志之一
常用参数:
| -b | 以字节为单位进行分割 ,仅显示行中指定直接范围的内容 |
| -c | 以字符为单位进行分割 , 仅显示行中指定范围的字符 |
| -d | 自定义分隔符,默认为制表符”TAB” |
| -f | 显示指定字段的内容 , 与-d一起使用 |
| -n | 取消分割多字节字符 |
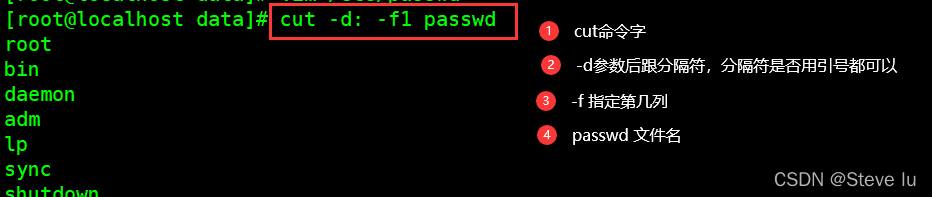
#截取用户名passwd文件中的用户名
[root@localhost data]# cut -d: -f1 passwd
root
bin
daemon
adm
lp
sync
#仅显示部分
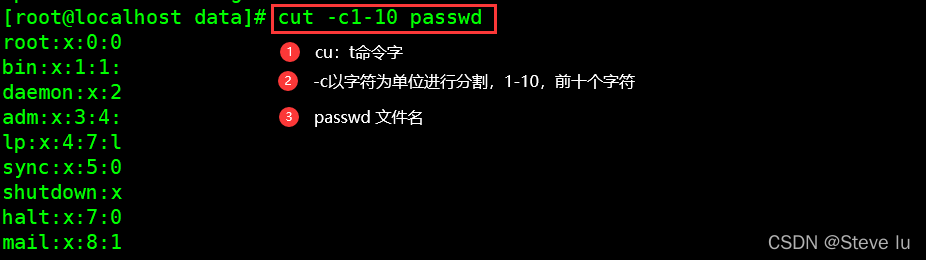
#显示passwd前十个字符
[root@localhost data]# cut -c1-10 passwd
root:x:0:0
bin:x:1:1:
daemon:x:2
adm:x:3:4:
lp:x:4:7:l
sync:x:5:0
shutdown:x
halt:x:7:0
mail:x:8:1
operator:x
#仅显示部分
#截取passwd文件第十个到最后的字符
[root@localhost data]# cut -c10- passwd
0:root:/root:/bin/bash
:bin:/bin:/sbin/nologin
2:2:daemon:/sbin:/sbin/nologin
:adm:/var/adm:/sbin/nologin
lp:/var/spool/lpd:/sbin/nologin
0:sync:/sbin:/bin/sync
x:6:0:shutdown:/sbin:/sbin/shutdown
0:halt:/sbin:/sbin/halt
#仅显示部分
#列出当前系统的运行级别
***********************
如何查看系统运行级别
命令:runlevel
文件:/etc/inittab
***********************
[root@localhost data]# runlevel
N 5
[root@localhost data]# runlevel |cut -c3
5
[root@localhost data]# runlevel |cut -d ' ' -f2
5三、sort 排序
sort命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出
sort命令既可以从特定的文件,也可以从stdin中获取输入
sort命令将文件的每一行作为一个单位,从首字符向后,依次按ASCll码值进行比较,最后升序输出
常用参数:
-u :去除重复行
-r :降序排列,默认是升序
-o : 将排序结果输出到文件中,类似重定向符号>
-n :以数字排序,默认是按字符排序
-t :分隔符
-k :第N列
-b :忽略前导空格。
-R :随机排序,每次运行的结果均不同#将passwd文件的前十行导出,安装第三列数字的升序排序
[root@localhost data]# head passwd > 1.txt
[root@localhost data]# cat -n 1.txt
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost data]# sort -n -t: -k3 1.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost data]# 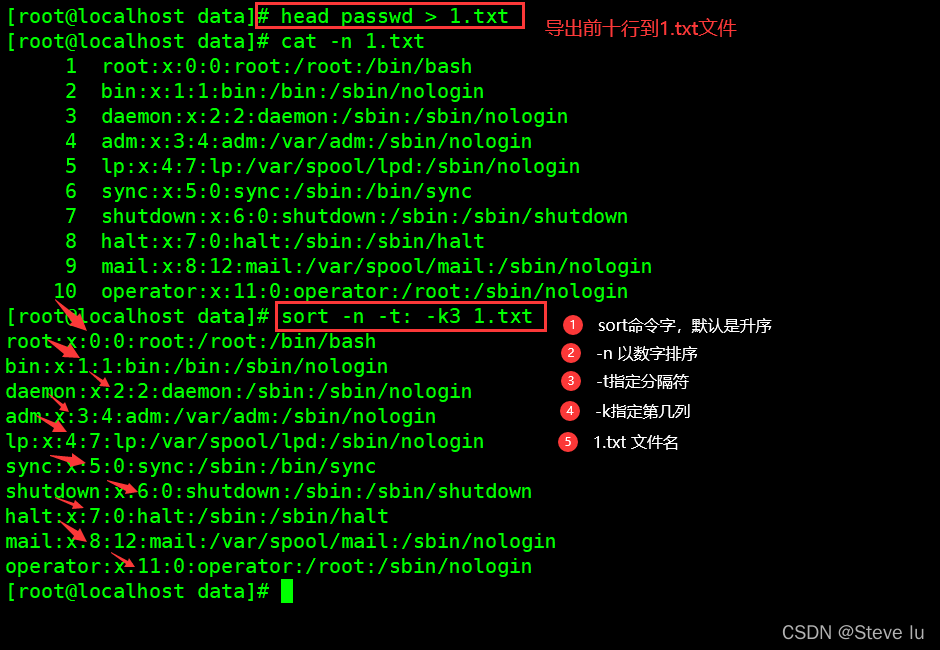

四、uniq 去重
该命令的作用是用来去除文本文件中连续的重复行,中间不能夹杂其他文本行。去除了重复的,保留的都是唯一的
sort只要有重复行,它就去除,而uniq重复行必须要连续,也可以用它忽略文件中的重复行
常用参数:
| -i | 忽略大小写 |
| -c | 打印每行在文本中重复出现的次数 |
| -d | 只显示有重复的纪录,每个重复纪录只出现一次 |
| -u | 只显示没有重复的纪录 |
[root@localhost data]# cat 3.txt
test 30
test 30
test 30
Hello 95
Hello 95
Hello 95
Hello 95
Linux 85
Linux 85
#查看时删除文件中连续重复的行
[root@localhost data]# uniq 3.txt
test 30
Hello 95
Linux 85
#打印重复的次数
[root@localhost data]# uniq -c 3.txt
3 test 30
4 Hello 95
2 Linux 85
#只显示没有重复的记录
[root@localhost data]# uniq -u 3.txt
[root@localhost data]# 五、tee 读取标准输入
tee指令会从标准输入设备读取数据,将其内容输出到标准输出设备,同时保存成文件
双向覆盖重定向
常用参数:
| -a | 附加到既有文件的后面,而非覆盖它 |
| -i | 忽略中断信号 |

#导出文件中的非注释信息,并且去掉空行,导入bak文件中
[root@localhost data]# grep -v '^#' vsftpd.conf |grep -v '^$' |tee bak
anonymous_enable=YES
local_enable=YES
write_enable=YES
local_umask=022
dirmessage_enable=YES
xferlog_enable=YES
connect_from_port_20=YES
xferlog_std_format=YES
listen=NO
listen_ipv6=YES
pam_service_name=vsftpd
userlist_enable=YES
tcp_wrappers=YES
[root@localhost data]# cat bak
anonymous_enable=YES
local_enable=YES
write_enable=YES
local_umask=022
dirmessage_enable=YES
xferlog_enable=YES
connect_from_port_20=YES
xferlog_std_format=YES
listen=NO
listen_ipv6=YES
pam_service_name=vsftpd
userlist_enable=YES
tcp_wrappers=YES
[root@localhost data]# 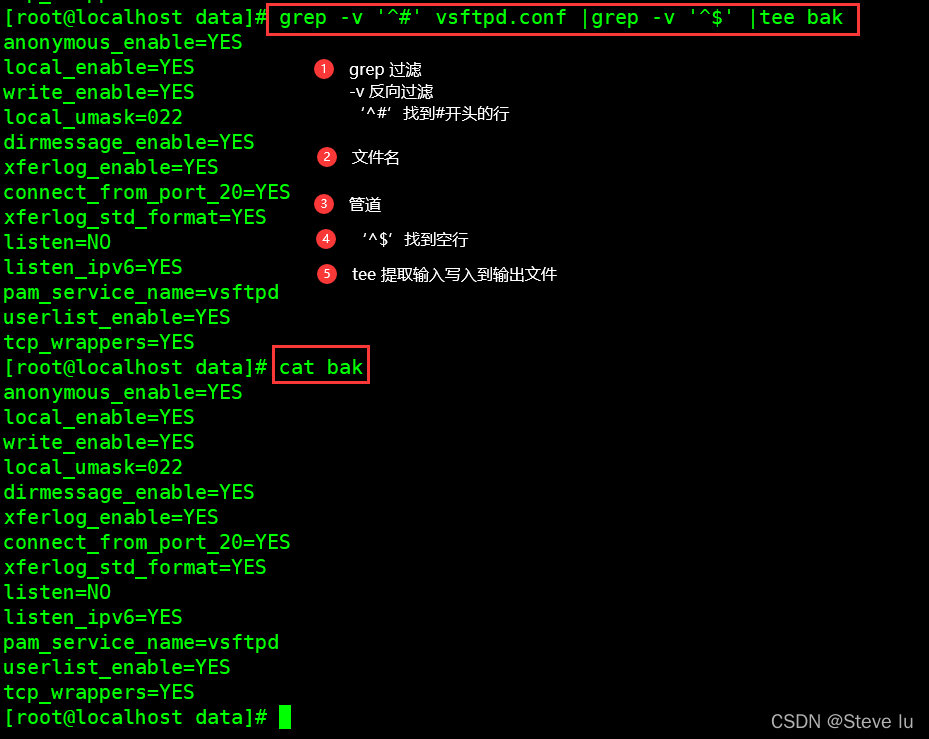
六、diff 比较文件差异
diff以逐行的方式,比较文本文件的异同处
如果指定要比较目录,则diff会比较目录中相同文件名的文件,但不会比较其中子目录
| 选项 | 含义 |
|---|---|
| -b | 不检查空格 |
| -B | 不检查空白行 |
| -i | 不检查大小写 |
| -w | 忽略所有的空格 |
| --normal | 正常格式显示(默认) |
| -c | 上下文格式显示 |
| -u | 合并格式显示 |
#文件准备
[root@localhost data]# cat -n file1
1 aaaa
2 111
3 hello world
4 222
5 333
6 bbb
[root@localhost data]# cat -n file2
1 aa
2 hello
3 111
4 222
5 bbb
6 333
7 world
[root@localhost data]#
#diff目的:显示file1如何改变才能和file2匹配
[root@localhost data]# diff file1 file2
1c1,2 第一个文件的第1行需要改变(c=change)才能和第二个文件的第1到2行匹配
< aaaa 小于号"<"表示左边文件(file1)文件内容
--- ---表示分隔符
> aaa 大于号">"表示右边文件(file2)文件内容
> hello
3d3 第一个文件的第3行删除(d=delete)后才能和第二个文件的第3行匹配
< hello world
5d4 第一个文件的第5行删除后才能和第二个文件的第4行匹配
< 333
6a6,7 第一个文件的第6行增加(a=add)内容后才能和第二个文件的第6到7行匹配
> 333 需要增加的内容在第二个文件里是333和world
> world七、paste 合并
paste命令会把每个文件以列对列的方式,一列列地加以合并 ,他就是相当于把两个不同的文件内容粘贴在一起,形成新的文件。
注意:paste默认粘贴方式以列的方式粘贴,但是并不是不能以行的方式粘贴,加上-s选项就可以行方式粘贴。
常用参数:
| -d | 自定义间隔符,默认是tab键 |
| -s | 将每个文件粘贴成一行 |
| -- | 从标准输入中读取数据 |
#准备文件
[root@localhost data]# cat file1
hello word
stevelu
[root@localhost data]# cat file2
CSDN
8888
9999yyds
#合并查看,以冒号分隔
[root@localhost data]# paste -d: file1 file2
hello word:CSDN
stevelu:8888
:9999yyds
[root@localhost data]#
#横向显示,默认tab键隔开
[root@localhost data]# paste -s file1 file2
hello word stevelu
CSDN 8888 9999yydspaste和cat都不改变原文件,也不生成新文件,个人感觉合并查看用cat就行,paste有点鸡肋
八、tr 字符转换
将字符进行替换、压缩、删除,他可以将一组字符转换成另一组字符。tr他只能从标准输入中读取数据,因此,tr要么将输入文件重定向到标准输入,要么从管道读入数据
注意:tr类似于sed命令,但是比sed简单,所以tr能实现的功能,sed都能实现
语法:
- 用法1:命令的执行结果交给tr处理,其中string1用于查询,string2用于转换处理
commands|tr 'string1' 'string2'
- 用法2:tr处理的内容来自文件,记住要使用"<"标准输入
tr 'string1' 'string2' < filename
- 用法3:匹配string1进行相应操作,如删除操作
tr [options] 'string1' < filename
常用参数:
| -c | 选定字符串1中字符集的补集,即反选字符串1的补集 |
| -d | 删除字符串1中出现的所有字符 |
| -s | 删除所有重复出现的字符序列,只保留一个 |
| 字符串 | 含义 |
|---|---|
| a-z或[:lower:] | 匹配所有小写字母 |
| A-Z或[:upper:] | 匹配所有大写字母 |
| 0-9或[:digit:] | 匹配所有数字 |
| [:alnum:] | 匹配所有字母和数字 |
| [:alpha:] | 匹配所有字母 |
| [:blank:] | 所有水平空白 |
| [:punct:] | 匹配所有标点符号 |
| [:space:] | 所有水平或垂直的空格 |
所有大小写和数字[a-zA-Z0-9]
8.1 替换
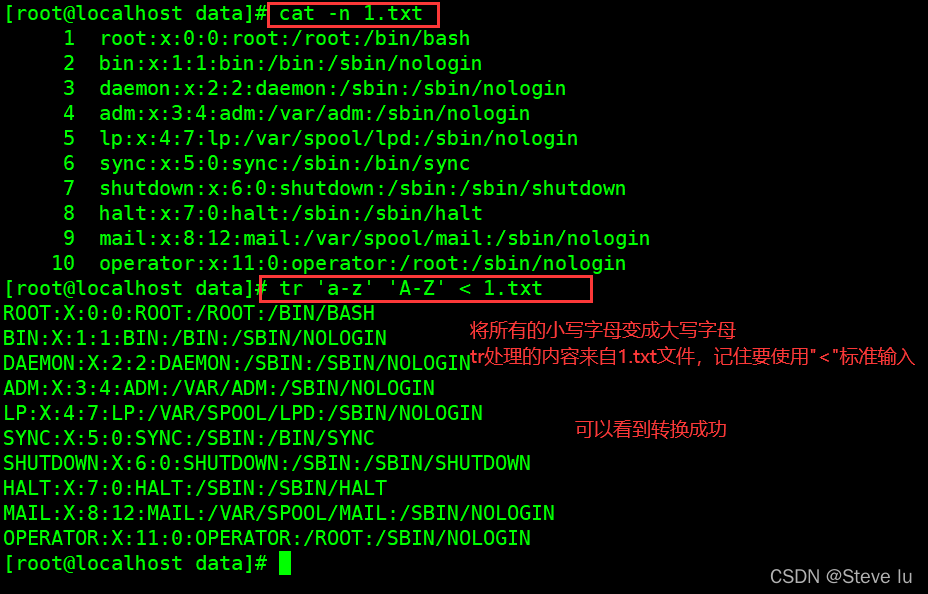
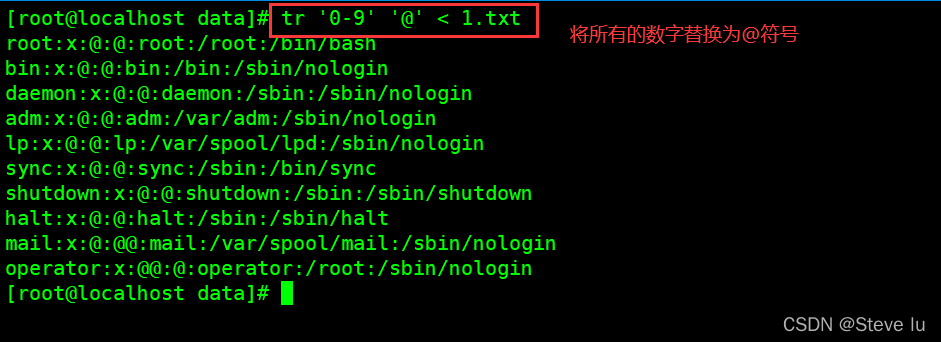
注:tr只能一对一替换,不能将一堆替换为一个
8.2 删除

8.3 压缩
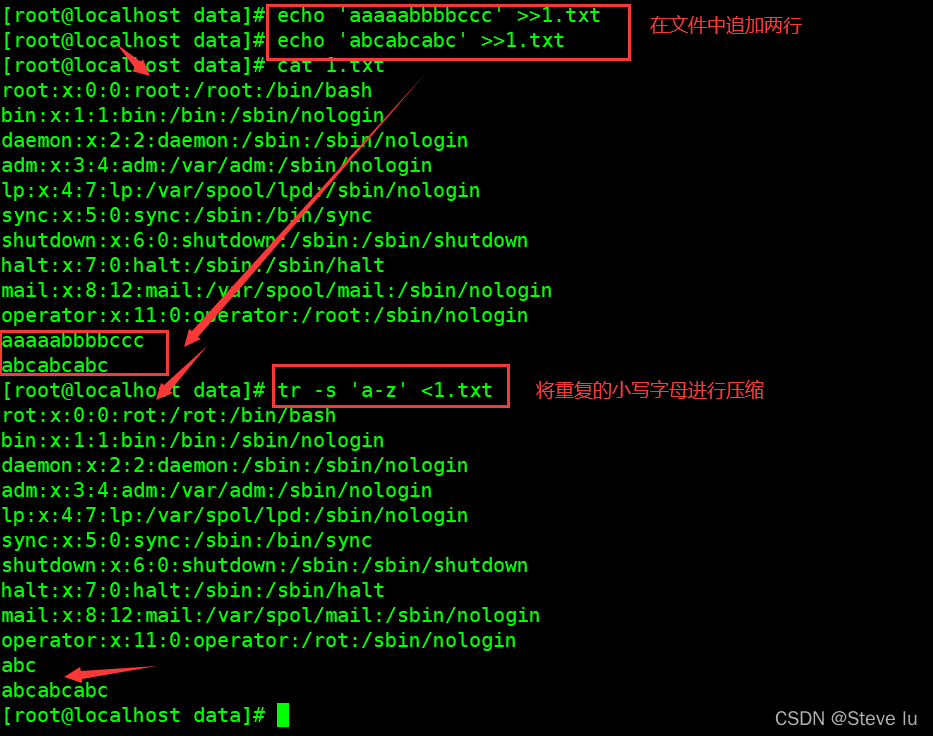
九、总结
这里列举的所有工具都不修改原文件
我们在写shell脚本的时候会经常用到这些文本工具,要熟悉一下