一.文本处理:
grep简介:
1.grep (缩写来自Globally search a Regular Expression and Print)是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本,并默认输出匹配行
2.grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到屏幕,不影响原文件内容。
3.grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
egrep简介:
1.egrep命令是一个搜索文件获得模式,使用该命令可以任意搜索文件中的字符串和符号,也可以为你搜索一个多个文件的字符串,一个提示符可以是单个字符、一个字符串、一个字、一个句子
两者区别:
1.egrep是grep的扩展和grep -e 是一样的…
2.grep中的匹配字符,全部当作字符串来处理,但是不支持正则表达式的特殊元字符…
3.egrep可以支持元字符…
1. grep与egrep
-i ##忽略字母大小写
-v ##条件取反
-c ##统计匹配行数
-q ##静默,无任何输出
-n ##显示匹配结果所在的行号
(1).egrep -c ‘/sbin/nologin’ /etc/passwd ##获取/etc/passwd文件中以/sbin/nologin结尾的行数
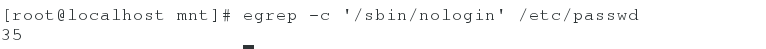
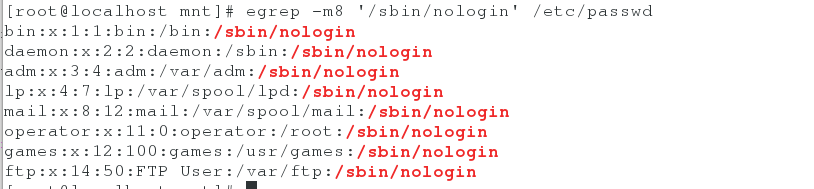
(2). egrep -m8 ‘/sbin/nologin’ /etc/passwd ##获取/etc/passwd文件中以/sbin/nologin结尾的前8行
(3) egrep -q ‘172.25.254.254’ /etc/hosts && echo ‘YES’ || echo ‘NO’ ##获取指定ip号,只输出YES

2. 基本元字符:
(1) ^ 与 $ ##意思分别是匹配以特定字符开头和结尾

(2) . ##过滤非空行

(3) ^$ 或 -v ‘.’ ##获取空行

(4) + ?
egrep ‘f+’ wsp ##输出包括f,ff,fff…,即f至少出现一次

egrep ‘color(ful)?’ wsp ##末尾的ful最多出现一次,也可以没有

3.元字符:{} 与 []
(1).egrep ‘(we){2,4}’ wsp ##we出现2到4次
egrep ‘(we){3,}’ wsp ##we出现3次和3次以上

(2).egrep ‘(we)[ab]’ wsp ##获取weab,wea或web
egrep ‘[A-Z]’ wsp ##获取A到Z

4.cut命令:
cut -d ##指定分隔符
(1).cut -d : -f 1-3 /etc/passwd ##指定分隔符为:,显示第1到3列

(2).cut -c 1,4 /etc/passwd ##显示第一和第四个字符

<练习:只获取主机的ip>
方式1:ifconfig eth0 | grep 'inet ’ | cut -d " " -f 10
方式2:ifconfig eth0 | grep 'inet ’ | awk ‘{print $2}’

<练习:编写脚本用来检测网络(是否能拼通)>
1.编写脚本,内容如下图

2.执行脚本,测试23主机能否ping通

5. sort命令:此类命令用来排序
-n ##纯数字排序
-r ##倒序
-u ##去掉重复数字
-o ##输出到指定文件中
-t ##指定分隔符
-k ##指定要排序的列
(1).sort -n westos ##纯数字排序westos文件中数

(2).sort -u westos ##去掉重复数字

(3).sort -t : -k 2 westos ##以:号为分隔符,对第二列进行排序(默认以第一个数来排序)

(4).sort -nt : -k 2 westos ##以:号为分隔符,对第二列进行纯数字排序

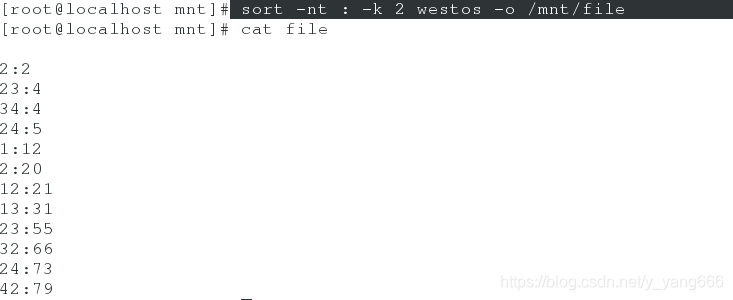
(5).sort -nt : -k 2 westos -o /mnt/file ##特定排序后导入指定文件中
6.uniq命令:对重复字符处理
-u ##显示唯一的行
-d ##显示重复的行
-c ##每行显示一次并统计重复次数
(1).sort -n westos | uniq -d ##显示重复的行

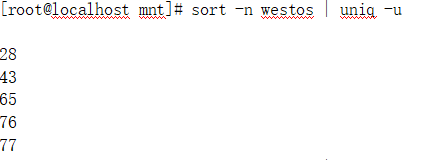
(2).sort -n westos | uniq -u ##显示唯一的行
(3).sort -n westos | uniq -c ##每行显示一次并统计重复次数

<练习:将/tmp目录中的文件取出最大的>
方法1:ll /tmp | awk ‘{print $5,$9}’ | sort -nr | head -1 | awk ‘{print $2}’
方法2:ls -Sl /tmp/ | head -2 | cut -d " " -f 9


二.test命令:

<练习1:判断输入的数字是否在10以内>
1.编写脚本,内容如图

2.执行脚本,进行测试

<练习2:判断文件类型:>
1.脚本内容如下图

2.执行脚本,进行测试
