高级文本处理命令
wc:功能: 统计文件行数、字节、字符数
sort:功能:排序文本,默认对整列有效
uniq:功能:去除重复行,只会统计相邻的
cut:cut命令可以从一个文本文件或者文本流中提取文本列
find:功能: 搜索文件目录层次结构
grep:是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来
sed:sed 是一种在线编辑器,它一次处理一行内容
awk:相较于sed 常常作用于一整个行的处理,awk 则比较倾向于一行当中分成数个『字段』来处理。 因此,awk 相当的适合处理小型的数据数据处理
1、wc
功能: 统计文件行数、字节、字符数
常用选项:
-l:统计多少行
-w:统计字数
-c:统计文件字节数,一个英文字母1字节,一个汉字占2-4字节(根据编码)
-m:统计文件字符数,一个英文字母1字符,一个汉字占1个字符
-L:统计最长行的长度, 也可以统计字符串长度
-help:显示帮助信息
--version:显示版本信息
一个汉字到底几个字节?
占2个字节的:〇
占3个字节的:基本等同于GBK,含21000多个汉字
占4个字节的:中日韩超大字符集里面的汉字,有5万多个
一个utf8数字占1个字节
一个utf8英文字母占1个字节
示例:
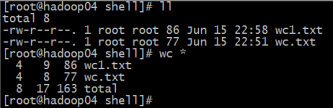
统计文件信息

[linux@linux ~]$ wc wc.txt
4 8 77 mingxing.txt
行数 单词数 字节数 文件名
统计字符串长度
[linux@linux ~]$ echo "hello" | wc -L
5
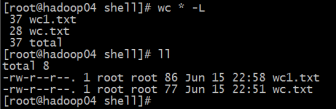
统计文件行数:
[linux@linux ~]$ wc -l mingxing.txt
6 mingxing.txt

统计文件字数:
[linux@linux ~]$ wc -w mingxing.txt
7 mingxing.txt
2、sort
功能:排序文本,默认对整列有效
常用可选项:
-f:忽略字母大小写,就是将小写字母视为大写字母排序
-M:根据月份比较,比如 JAN、DEC
-h:根据易读的单位大小比较,比如 2K、1G
-g:按照常规数值排序
-n:根据字符串数值比较
-r:倒序排序
-k:位置1,位置2根据关键字排序,在从第位置1开始,位置2结束
-t:指定分隔符
-u:去重重复行
-o:将结果写入文件
准备数据:
aaa:10:1.1
ccc:20:3.3
bbb:40:4.4
eee:40:5.5
ddd:30:3.3
bbb:40:4.4
fff:30:2.2
示例:
准备排序文件,查看该内容
[linux@linux ~]$ cat sort.txt ## 准备排序文件,查看该内容
aaa:10:1.1
ccc:20:3.3
bbb:40:4.4
eee:40:5.5
ddd:30:3.3
bbb:40:4.4
fff:30:2.2
直接排序,把整行当做一列字符串,字典顺序
[linux@linux ~]$ sort sort.txt ## 直接排序,把整行当做一列字符串,字典顺序
aaa:10:1.1
bbb:40:4.4
bbb:40:4.4
ccc:20:3.3
ddd:30:3.3
eee:40:5.5
fff:30:2.2
以:作为分隔符,取第二个字段按照数值进行排序
[linux@linux ~]$ sort -nk 2 -t : sort.txt ## 以:作为分隔符,取第二个字段按照数值进行排序
aaa:10:1.1
ccc:20:3.3
fff:30:2.2
ddd:30:3.3
bbb:40:4.4
bbb:40:4.4
eee:40:5.5
和上一个不一样的是-u为了去重
[linux@linux ~]$ sort -nk 2 -u -t : sort.txt ## 和上一个不一样的是-u为了去重
aaa:10:1.1
ccc:20:3.3
ddd:30:3.3
bbb:40:4.4
多列排序:以:分隔,按第二列数值排倒序,第三列正序
[linux@linux ~]$ sort -n -t: -k2,2r -k3 sort.txt
bbb:40:4.4
bbb:40:4.4
eee:40:5.5
fff:30:2.2
ddd:30:3.3
ccc:20:3.3
aaa:10:1.1
3、uniq
功能:去除重复行,只会统计相邻的
常用选项:
-c:打印出现的次数
-d:只打印重复行
-u:只打印不重复行
-D:只打印重复行,并且把所有重复行打印出来
-f N:比较时跳过前N列
-i:忽略大小写
-s N:比较时跳过前N个字符
-w N:对每行第N个字符以后内容不做比较
准备数据:
abc
xyz
cde
cde
xyz
abd
示例1:
[linux@linux ~]$ uniq uniq.txt ## 直接去重,只能在相邻行去重
abc
xyz
cde
xyz
abd
[linux@linux ~]$ sort uniq.txt | uniq ## 先给文件排序,然后去重
abc
abd
cde
xyz
[linux@linux ~]$ sort uniq.txt | uniq -c ## 打印每行重复次数
1 abc
1 abd
2 cde
2 xyz
[linux@linux ~]$ sort uniq.txt | uniq -u -c ## 打印不重复行,并给出次数
1 abc
1 abd
[linux@linux ~]$ sort uniq.txt | uniq -d -c ## 打印重复行,并给出次数
2 cde
2 xyz
[linux@linux ~]$ sort uniq.txt | uniq -w 2 ## 以开头前两个字符为判断标准去重
abc
cde
xyz
示例2:
先准备两个文件:a.txt 和 b.txt
文件内容分别为:
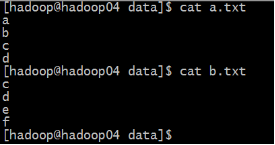
需求:
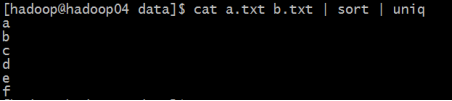
1、求两个文件的交集:
[hadoop@hadoop04 data]$ cat a.txt b.txt | sort | uniq -d

2、求两个文件的并集:
[hadoop@hadoop04 data]$ cat a.txt b.txt | sort | uniq
3、求a.txt和b.txt的差集
[hadoop@hadoop04 data]$ cat a.txt b.txt b.txt | sort | uniq -u

4、求b.txt和a.txt的差集
[hadoop@hadoop04 data]$ cat b.txt a.txt a.txt | sort | uniq -u

4、cut
cut命令可以从一个文本文件或者文本流中提取文本列
cut语法
cut -d’分隔字符’ -f fields ## 用于有特定分隔字符
cut -c 字符区间 ## 用于排列整齐的信息
选项与参数:
-d:后面接分隔字符。与 -f 一起使用
-f:依据 -d的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思
-c:按照字符截取
-b:按照字节截取
例子1:
首先看PATH变量:
[root@localhost ~]# echo $PATH
/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
将PATH变量取出,找出第五个路径
[root@localhost ~]# echo $PATH | cut -d ':' -f 5
/usr/sbin
将PATH变量取出,找出第三和第五个路径,以下三种方式都OK
[root@localhost ~]# echo $PATH | cut -d ':' -f 3,5
[root@localhost ~]# echo $PATH | cut -d : -f 3,5
[root@localhost ~]# echo $PATH | cut -d: -f3,5
/sbin:/usr/sbin
将PATH变量取出,找出第三到最后一个路径
[root@localhost ~]# echo $PATH | cut -d ':' -f 3-
/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
将PATH变量取出,找出第一到第三,还有第五个路径
[root@localhost ~]# echo $PATH | cut -d ':' -f 1-3,5
/usr/local/sbin:/usr/local/bin:/sbin:/usr/sbin
例子2:
先准备已空格分开的这么段数据:
黄渤 huangbo 18 jiangxi
徐峥 xuzheng 22 hunan
王宝强 wangbaoqiang 44 liujiayao
获取中间的年龄:
[root@localhost ~]# cut -f 3 -d ' ' cut.txt
18
22
44
获取第二个字符到第五个字符之间的字符:
[root@localhost ~]# cut -c 2-5 cut.txt
渤 hu
峥 xu
宝强 w
获取第四个字节到第六个字节中的字符:
[root@hadoop ~]# cut -b 4-6 cut.txt
渤
峥
宝
5、find
功能: 搜索文件目录层次结构
格式: find path -option actions
find <路径> <选项> [表达式]
常用可选项:
-name 根据文件名查找,支持('* ' , '? ')
-type 根据文件类型查找(f-普通文件,c-字符设备文件,b-块设备文件,l-链接文件,d-目录)
-perm 根据文件的权限查找,比如 755
-user 根据文件拥有者查找
-group 根据文件所属组寻找文件
-size 根据文件小大寻找文件
-o 表达式 或
-a 表达式 与
-not 表达式 非
示例:
[linux@linux txt]$ ll ## 准备的测试文件
total 248
-rw-rw-r--. 1 linux linux 235373 Apr 18 00:10 hw.txt
-rw-rw-r--. 1 linux linux 0 Apr 22 05:43 LINUX.pdf
-rw-rw-r--. 1 linux linux 3 Apr 22 05:50 liujialing.jpg
-rw-rw-r--. 1 linux linux 0 Apr 22 05:43 mingxing.pdf
-rw-rw-r--. 1 linux linux 57 Apr 22 04:40 mingxing.txt
-rw-rw-r--. 1 linux linux 66 Apr 22 05:15 sort.txt
-rw-rw-r--. 1 linux linux 214 Apr 18 10:08 test.txt
-rw-rw-r--. 1 linux linux 24 Apr 22 05:27 uniq.txt
[linux@linux txt]$ find /home/linux/txt/ -name "*.txt" ## 查找文件名txt结尾的文件
/home/linux/txt/uniq.txt
/home/linux/txt/mingxing.txt
/home/linux/txt/test.txt
/home/linux/txt/hw.txt
/home/linux/txt/sort.txt
## 忽略大小写查找文件名包含linux
[linux@linux txt]$ find /home/linux/txt -iname "*linux*"
/home/linux/txt/LINUX.pdf
## 查找文件名结尾是.txt或者.jpg的文件
[linux@linux txt]$ find /home/linux/txt/ \( -name "*.txt" -o -name "*.jpg" \)
/home/linux/txt/liujialing.jpg
/home/linux/txt/uniq.txt
/home/linux/txt/mingxing.txt
/home/linux/txt/test.txt
/home/linux/txt/hw.txt
/home/linux/txt/sort.txt
另一种写法:find /home/linux/txt/ -name "*.txt" -o -name "*.jpg"
使用正则表达式的方式去查找上面条件的文件:
[linux@linux txt]$ find /home/linux/txt/ -regex ".*\(\.txt\|\.jpg\)$"
/home/linux/txt/liujialing.jpg
/home/linux/txt/uniq.txt
/home/linux/txt/mingxing.txt
/home/linux/txt/test.txt
/home/linux/txt/hw.txt
/home/linux/txt/sort.txt
## 查找.jpg结尾的文件,然后删掉
[linux@linux txt]$ find /home/linux/txt -type f -name "*.jpg" -delete
[linux@linux txt]$ ll
total 248
-rw-rw-r--. 1 linux linux 235373 Apr 18 00:10 hw.txt
-rw-rw-r--. 1 linux linux 0 Apr 22 05:43 LINUX.pdf
-rw-rw-r--. 1 linux linux 0 Apr 22 05:43 mingxing.pdf
-rw-rw-r--. 1 linux linux 57 Apr 22 04:40 mingxing.txt
-rw-rw-r--. 1 linux linux 66 Apr 22 05:15 sort.txt
-rw-rw-r--. 1 linux linux 214 Apr 18 10:08 test.txt
-rw-rw-r--. 1 linux linux 24 Apr 22 05:27 uniq.txt