************************grep*************************
1 .grep 文本过滤命令
Global search regular expression and print out the line全面搜索研究正则表达式并显示出来
grep 命令是一种强大的文本搜索工具,根据用户指定的"模式"对目标文本进行匹配检查,打印匹配到的行
由正则表达式或者字符及基本文本字符所编写的过滤条件
2.grep的格式
grep ^root passwd #root 开头的行
grep root$ passwd #root 结尾的行
grep -i root passwd #不区分大小写
grep -v root passwd #反向过滤
grep -E "root|ROOT" passwd #过滤含有root或者ROOT的行
grep -E "^root|ROOT" passwd #过滤以root开头或者含有ROOT 的行
3.grep中的正则表达式
^root #匹配以root开头的行
root$ #匹配以root结尾的行
'r...t' #匹配r和t之间有3个字符的行(有几个点就代表匹配几个字符)
'r....' #匹配r后有四个字符的行
'....t' #匹配t之前有四个字符的行

4.grep中字符的匹配位置设定
^关键字 #关键字开头
关键字$ #关键字结尾
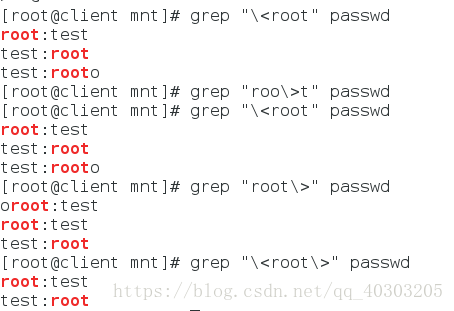
\<关键字 #关键字开头不扩展
关键字\> #关键字结尾不扩展
\<关键字\> #关键字开头结尾不扩展
5.grep中字符的匹配次数设定
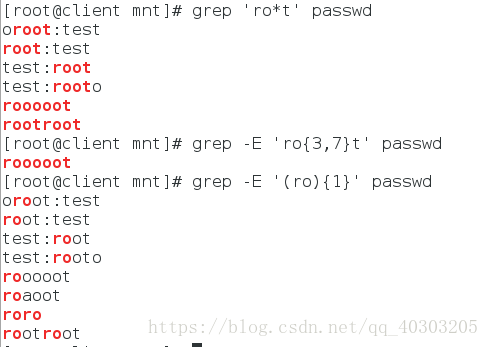
* 字符出现[0-任意次]
\? 字符出现[0-1次]
\+ 字符出现[1-任意次]
\{n\} 字符出现[n次]
\{m,n\} 字符出现[最少出现m次,最多出现n次]
\{0,n\} 字符出现[0-n次]
\{m,\} 字符出现[至少m次]
\(xy\)\{n\} xy字符出现[n次]
.* 关键字之间匹配任意字符
************************sed*************************
1.sed 行编辑器
stream editor
用来操作纯 ASCII 码的文本
处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space)可以指定仅仅处理哪些行
sed 符合模式条件的处理不符合条件的不予处理,处理完成之后把缓冲区的内容送往屏幕,接着处理下一行,这样不断重复,直到文件末尾.
2.Sed 命令格式
调用sed 命令有两种格式sed [opinions参数] 'command'命令 file(s)
sed [opinions] -f scriptfile file(s)
3.sed对字符的处理
p 显示
d 删除
a 添加
c 替换
w 写入
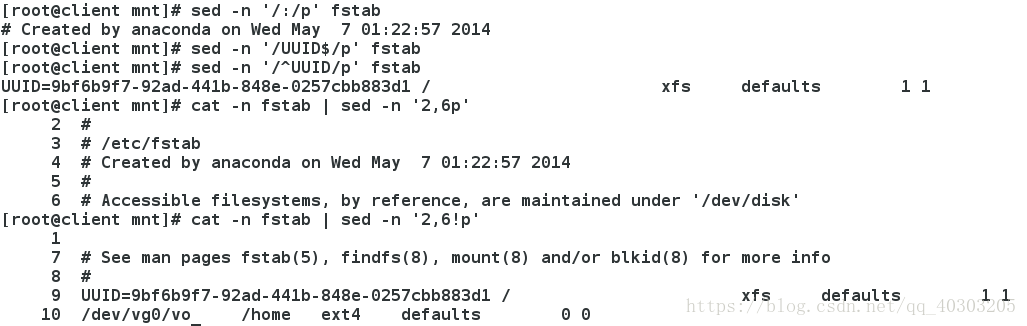
i 插入sed -n '/\:/p' fstab #显示包含:的行
sed -n '/UUID$/p' fstab #显示以UUID结尾的行
sed -n '/^UUID/p' fstab #显示以UUID开头的行
sed -n '2,6p' fstab #显示第2行到第6行
sed -n '2,6!p' fstab #不显示第2到6
sed -n -e '2!p;6!p' | uniq -d fstab #不显示第二行和第六行

练习:
编写脚本,执行时其后跟usename password两个文件 则可以批量创建username文件中的用户,并设置其密码为password文件中的对应密码
vim user_create.sh
#!/bin/bash
MAX_LINE=`wc -l $1|cut -d " " -f 1`
for LINE_NUM in `seq 1 $MAX_LINE`
do
USERNAME=`sed -n "${LINE_NUM}p" $1`
PASSWORD=`sed -n "${LINE_NUM}p" $2`
useradd $USERNAME
echo $PASSWORD | passwd --stdin $USERNAME
done


5.d模式操作
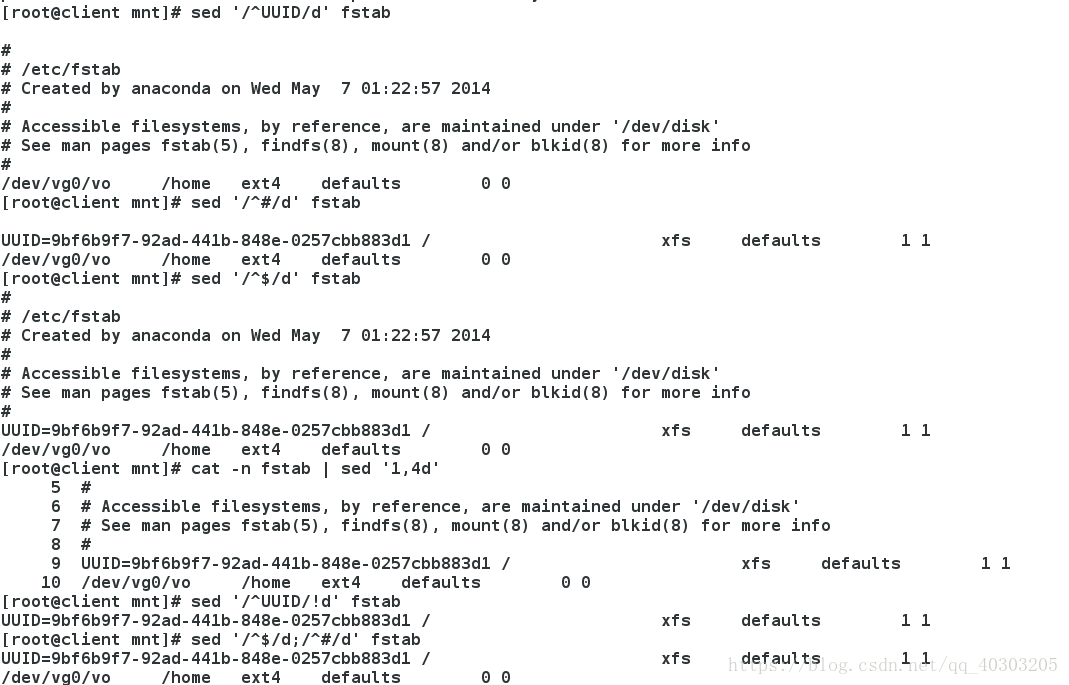
sed '/^UUID/d' fstab #删除UUID开头的行
sed '/^#/d' fstab #删除#开头的行
sed '/^$/d' fstab #删除空行
sed '1,4d' fatab #删除1到4行
sed '/^UUID/!d' fstab #不删除UUID开头的行
sed '/^$/d;/^#/d' fstab #删除空行以及以#开头的行
6.a模式操作
sed '/linux/ahello' westos #在westos文件中给linux后添加hello
sed '/linux/ahello\nworld' westos #在westos文件中给linux后添加hello 换行添加world
sed '/linux/a hello world' westos #在westos文件中给linux后添加hello world

7.c模式操作
sed '/^UUID/c hello' fstab #将以UUID开头的那一行替换成hello行
8.w模式操作
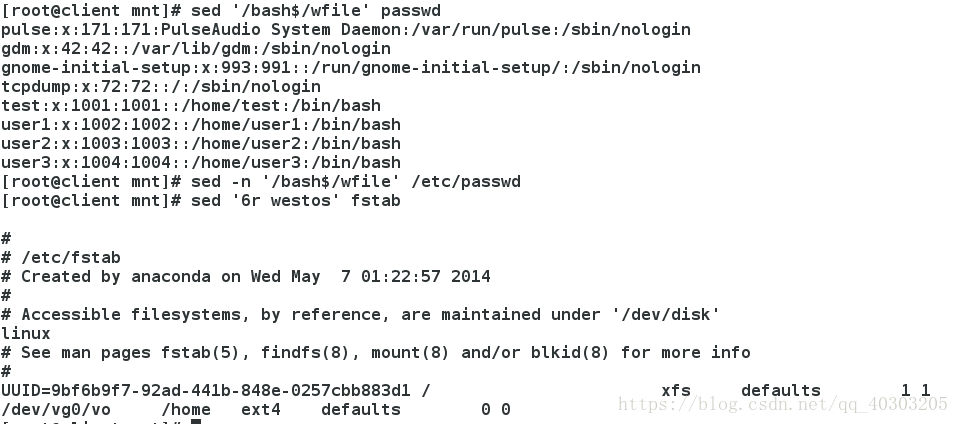
sed '/bash$/wfile' passwd #把/etc/passwd中以bash结尾的行写入file中
sed -n '/bash$/wfile' /etc/passwd #同上,但不显示
sed '6r westos' fstab #把westos里的内容写入fatab第六行中
9.i模式操作
sed '/^UUID/i hello' fstab #在以UUID开头的那一行前插入hello行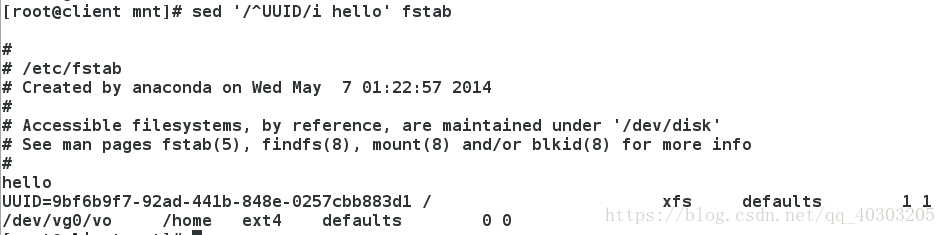
10.sed的其他用法
sed 'G' fstab #每行之间添加一个空行显示
sed '$!G' fstab #除了最后一行每行之间添加一个空行显示
sed -n '$p' fstab #显示最后一行

#!/bin/bash
SHELL=$(echo `grep -v nologin /etc/shells` | sed 's/ /|/g') 将nologin行反向过滤掉,并将结果输出为以行赋给SHEEL
grep -E "$SHELL" /etc/passwd | cut -d : -f 1 指定分隔符,显示第一列过滤用户
运行结果

************************awk*************************
1.awk报告生成器
awk处理机制:awk会逐行处理文本,支持在处理第一行之前做一些准备工作,以及在处理完最后一行做一些总结性质的工作,在命令格式上分别体现如下:
BEGIN{ } :读入第一行文本之前执行,一般用来初始化操作
{ } :逐行处理,逐行读入文本执行相应的处理,是最常见的编辑指令块
END{ } :处理完最后一行文本之后执行,一般用来输出处理结果2.awk基本用法
awk -F ":" '{print 'NR==3'}' passwd #以:为分隔符,打印第三列
awk -F ":" 'BEGIN {print NAME}{print $1}' passwd #以:为分隔符,处理前打印NAME,打印第一列
awk '/bash$/ ' passwd #以:为分隔符,打印以bash结尾的行
awk -F ":" '/bash$/{print $1}' passwd #以:为分隔符,打印以bash结尾的行的第一列
awk -F ":" 'BEGIN{N=0}/bash$/{N++}END{print N}' passwd #打印以bash结尾的行有多少行

练习:抓取eth0网卡的ip
ifconfig eth0 | awk -F " " '/inet\>/{print $2}'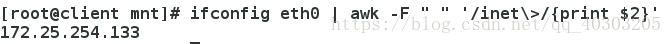
统记在系统中可以登陆系统的用户
awk -F ":" 'BEGIN{N=0}//&&/bash$/{N++}END{print N}' /etc/passwd