ICLR-2018
概述
这篇文章的主要工作是使用知识蒸馏的方法压缩模型,主要的trick在损失函数的设计,对于不同类别的任务,使用soft-target设计损失函数,并且使用分类任务来初始化教师和学生网络的参数。
摘要
知识蒸馏是模型压缩的潜在解决方案。这个想法是让一个小型学生网络模仿大型教师网络的目标,然后学生网络可以与教师网络竞争。以前的大多数研究都集中在分类任务中的模型蒸馏,他们为学生网络提出了不同的体系结构和初始化。但是,只有分类任务是不够的,并且几乎不考虑其他相关任务,例如回归和检索。为了解决这个问题,本文以人脸识别为切入点,提出了从人脸分类到对齐和验证的知识转移模型。通过在知识转移中选择合适的初始化和目标,在非分类任务中蒸馏可以更容易。 CelebA和CASIA-WebFace数据集上的实验表明,学生网络在校准和验证方面可以与教师竞争,甚至在特定压缩率下超过教师网络。此外,为了实现更强的知识转移,我们还使用常见的初始化技巧来提高分类的蒸馏性能。对CASIA-Webface和大型MS-Celeb-1M数据集的评估显示了这个简单技巧的有效性。
1 介绍
自Alexnet(Krizhevsky等人,2012)出现以来,更大更深的网络已经显示出更强大的功能(Simonyan&Zisserman,2015; Szegedy等,2015; He等,2016)。然而,随着网络越来越大,在移动设备中使用它变得困难。因此,在将大型网络压缩成小型网络时,模型压缩变得必不可少。近年来,已经提出了许多压缩方法,包括知识蒸馏(Ba&Caruana,2014; Hinton等,2014; Romero等,2015),权重量化(Gong等,2015; Rastegari等。 ,2016),权重修剪(Han等人,2016; Szegedy等人,2016)和权重分解(Canziani等人,2017; Novikov等人,2015)。在本文中,我们关注知识蒸馏,这是一种模型压缩的潜在方法。
在知识蒸馏中,通常有一个庞大的教师网络和一个小的学生网络,目的是通过学习教师网络的特定目标,使学生网络与教师网络竞争。以前的研究主要考虑分类任务中目标的选择,例如隐藏层(Luo等,2016),logits(Ba&Caruana,2014; Urban等,2017; Sau&Balasubramanian,2017)或软预测(Hinton等,2014; Romero等,2015)。但是,只有分类任务的升级是不够的,还应考虑一些常见的任务,如回归和检索。在本文中,我们将面部识别作为一个突破点,我们从面部分类中的知识蒸馏开始,并考虑在两个领域相似的任务,包括面部对齐和验证的蒸馏。面部对齐的目的是定位每个图像中的关键点位置;在面部验证中,我们必须确定两个图像是否属于同一身份。
对于非分类任务的蒸馏,一个直观的想法是采用与面部分类类似的方法,从头开始训练教师和学生网络。通过这种方式,所有任务的蒸馏将是独立的,这是一种可能的解决方案。但是,这种独立性无法给出最佳的蒸馏性能。有强有力的证据表明,在物体检测(Ren et al。,2015),物体分割(Chen et al。,2015)和图像检索(Zhao et al。,2015)中,他们都使用了预训练分类模型(在ImageNet上) )作为初始化以提高性能。这种成功来自于他们的领域相似,这使得他们从低级到高级别的代表转移很多(Yosinski等,2014)。类似地,面部分类,对齐和验证也共享相似的域,因此我们建议通过使其教师和学生网络在对齐和验证中初始化相应的网络来传递分类的蒸馏知识。
知识转移的另一个问题是应该将哪些目标用于蒸馏?在面部分类中,通过学习软预测来从教师网络中提取知识,这已被证明效果很好(Hinton等,2014; Romero等,2015)。然而,在面对齐(Wu et al。,2015)和验证(Wu et al。,2015)中,他们有额外的任务特定目标。因此,选择用于蒸馏的分类或任务特定目标仍然是一个问题。一个直观的想法是衡量非分类和分类任务之间目标的相关性。例如,看到面部分类和对齐之间的关系并不明显,但分类可以帮助验证很多。因此,如果任务高度相关,则首选分类目标,或者特定于任务的目标更好,这似乎是合理的。
在上述思想的启发下,本文提出了通过面部分类转换蒸馏知识进行面部对齐和验证的模型蒸馏。通过适当选择初始化和目标,我们证明了CelebA(Liu et al。,2015)和CASIA-WebFace(Yi et al。,2016)数据集的对齐和验证的蒸馏性能可以在很大程度上得到改善,并且学生网络甚至可以在特定的压缩率下超过教师网络。
这种知识转移是我们的主要贡献。此外,我们认识到,在所提出的方法中,知识转移依赖于分类的蒸馏,因此我们使用共同的初始化技巧来进一步提高分类的蒸馏性能。对CASIA-WebFace和大型MS-Celeb-1M(Guo等,2016)数据集的评估表明,这种简单的技巧可以在分类任务中提供最佳的蒸馏结果。
2 相关工作
在这一部分,我们介绍了一些以前关于知识蒸馏的研究。特别是,以下所有研究都集中在分类任务上。 Bucilua等人。 (2006)建议由教师网络生成合成数据,然后用数据训练学生网络以模仿身份标签。然而,Ba&Caruana(2014)观察到这些标签已经失去了教师网络的不确定性,因此他们建议回归logits(pre-softmax激活)(Hinton等,2014)。此外,他们更喜欢学生网络深入,这有利于模仿复杂的功能。为了更好地学习这个功能,Urban等人。 (2017)观察学生网络不仅要深刻,而且要卷积,并且他们在CIFAR的教师网络中获得竞争性表现(Krizhevsky&Hinton,2009)。大多数方法需要多个教师网络才能更好地进行蒸馏,但这需要很长的培训和推理时间(Sau&Balasubramanian,2017)。为了解决这个问题,Sau&Balasubramanian(2017)提出了基于噪声的正则化,可以模拟多个教师网络的logits。但是,罗等人。 (2016)观察这些logits的值是不受约束的,而高维度将导致过拟合问题。因此,他们使用隐藏层,因为它们捕获与logits一样多的信息,但更紧凑。
所有这些方法只使用教师网络的目标进行蒸馏,而如果目标不鲁棒,则训练将很困难。为了解决这个问题,Hinton等人。 (2014)提出了一种多任务方法,它共同使用身份标签和教师网络的目标。特别地,它们使用具有温度平滑的后softmax激活作为目标,这可以更好地表示标签分布。一个问题是学生网络大多是从头开始训练的。鉴于初始化很重要,Romero等人。 (2015)建议通过回归教师网络的中级目标来初始化学生网络的浅层。然而,这些研究仅考虑分类中的知识蒸馏,这在很大程度上限制了其在模型压缩中的应用。在本文中,我们将面部识别视为一个突破点,并将知识蒸馏扩展到非分类任务。
3 分类任务上的蒸馏
由于提出的知识转移取决于分类的蒸馏,改进分类本身是必要的。 在这一部分中,我们首先回顾蒸馏的分类思想,然后介绍如何通过简单的初始化技巧来提升它。

3.1 回顾
我们采用Hinton等人的蒸馏框架。 (2014),总结如下。设T和S为教师和学生网络,其后softmax预测为PT = softmax(aT)和PS = softmax(aS),其中aT和aS是pre-softmax预测,也称为logits(Ba) &Caruana,2014)。然而,后softmax预测已经失去了一些更具信息性的相对不确定性,因此温度参数τ用于平滑预测PT和PS为PτT和PτS,其表示为软预测:
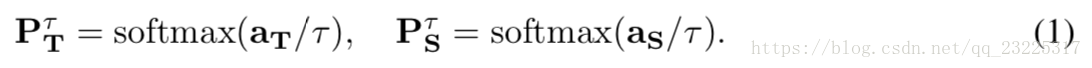
然后,考虑PτT作为目标,知识蒸馏优化以下损失函数
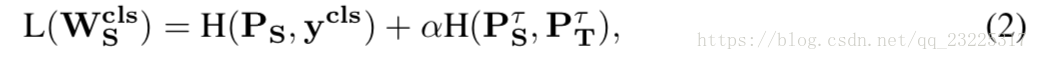
其中Wcls是学生网络的参数,ycls是身份标签。为简单起见,省略min和样本数N,并将右上角符号cls表示为分类任务。另外,H(,)是交叉熵,因此第一项是softmax损失,而第二项是教师和学生网络的软预测之间的交叉熵,在两个术语之间具有α平衡。这种多任务训练是有利的,因为不能保证目标PτT总是正确的,并且如果目标不鲁棒,则身份标签ycls将接管学生作业的训练。
3.2 初始化技巧
值得注意的是,在方程(2)中,学生网络是从头开始训练的。正如Ba&Caruana(2014)所证明的那样,更深层次的学生网络更适合蒸馏,因此初始化变得非常重要(Hinton等,2006; Ioffe&Szegedy,2015)。基于证据,Fitnet(Romero等,2015)首先通过回归教师网络的中级目标来初始化学生网络的浅层,然后按照等式(2)进行蒸馏。然而,仅初始化浅层仍然难以学习由深层生成的高级表示。此外,Yosinski等人。 (2014)表明,随着任务变得更加相似,网络可转移性也会增加。在我们的例子中,初始化和蒸馏都是具有完全相同的数据和身份标签的分类任务,因此应该初始化更深的层以获得更高的可转移性,并且我们使用一个简单的技巧来实现这一点。
为了获得初始学生网络,我们使用softmax损失进行训练:

其中右下角符号S0表示学生网络S的初始化。这样,学生网络已完全初始化。然后,我们将方程(2)修改为
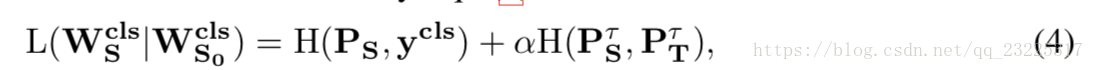
其中Wcls | Wcls表示Wcls通过Wcls的初始化进行训练,并且两者熵项保持不变。该过程如图1(a)所示。可以看出是唯一的与方程(2)的不同之处在于学生网络是在完全初始化的情况下训练的,并且这种简单的技巧已被普遍使用,例如,基于完全预训练的模型初始化VGG-16模型(Simonyan&Zisserman,2015)。我们后来表明,这个技巧可以在Eqn。(2)和Fitnet(Romero等,2015)上获得有希望的改进。
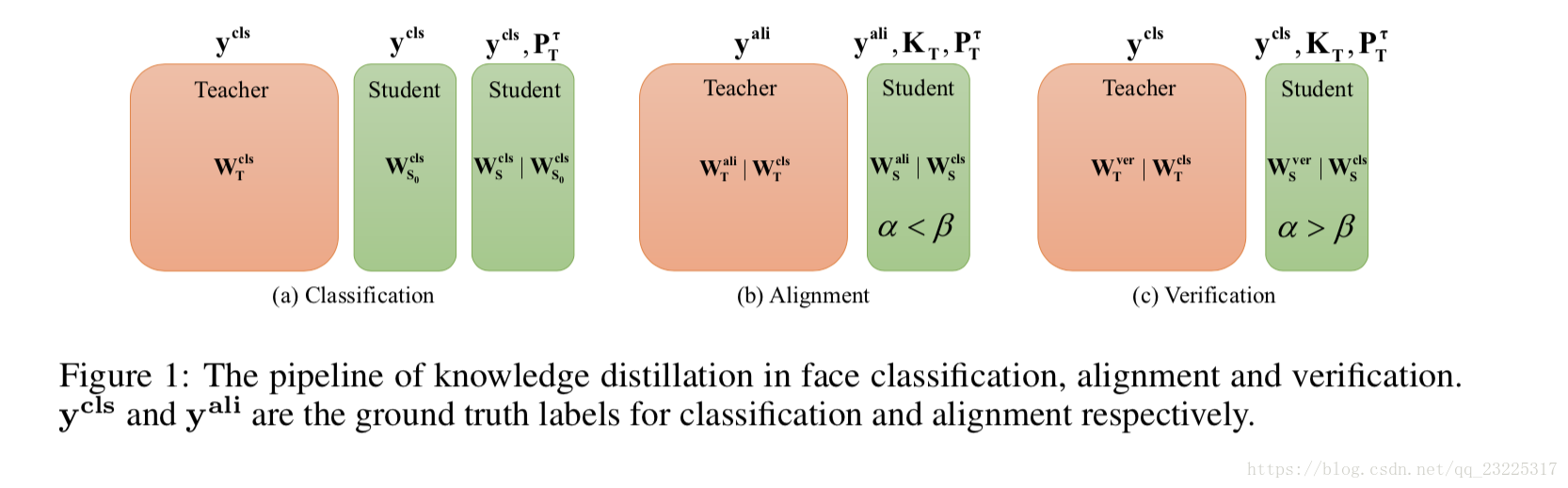
4 蒸馏迁移
在这一部分中,我们将展示如何将蒸馏知识从面部分类转移到面部对齐和验证。 知识转移包括两个步骤:转移初始化和目标选择,详述如下。
4.1 初始化
传输的第一步是传输初始化。动机是基于以下证据:在检测,分割和检索中,他们使用预训练分类模型(在ImageNet上)作为初始化以提高性能(Ren等人,2015; Chen等人,2015; Zhao等人。 ,2015)。这种想法的可用性来自于它们共享相似的领域,这使得它们很容易从低级别转移到高级别的代表(Yosinski等,2014)。同样,面部分类,对齐和验证的领域也相似,因此我们可以以相同的方式转移蒸馏知识。
为简单起见,我们将面部分类中的师生网络参数表示为WTcls和WScls。类似地,人脸对齐是WTali和WSali的对齐,而WTver和WSver则是验证。如上所述,在对齐和验证的升级中,教师和学生网络将分别由WTcls和WScls初始化。
4.2 Target选择
基于初始化,第二步是在教师网络中选择适当的目标进行蒸馏。一个问题是非分类任务有自己的任务特定目标,但考虑到额外的软预测PτT,我们应该使用哪一个?需要说明的是,我们首先提出非分类任务的一般蒸馏方法如下:
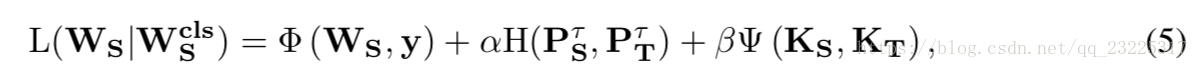
其中WS和y分别表示任务特定的网络参数和标签。 Φ(WS,y)是任务特定的损失函数,Ψ(KS,KT)是任务特定的蒸馏项,目标在教师和学生网络中被选为KT和KS。此外,α和β是分类和非分类任务之间的平衡条件。在方程(5)中,上述问题已成为如何为给定的非分类任务设置α和β。在以下两部分中,我们将讨论两个任务:面部对齐和验证。
4.3 对齐
面部对齐的任务是定位每个图像的关键点位置。不失一般性,没有任何身份标签,只有每个图像的关键点位置。面部对齐通常被认为是回归问题(Wu et al。,2015),因此我们通过优化欧几里德损失来训练教师网络:
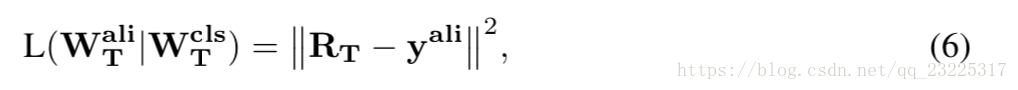
其中RT是教师网络的回归预测,yali是回归标签。在蒸馏中,除了可用的软预测PτT(分类目标)之外,另一个是可以作为隐藏层KT的任务特定目标(Luo等,2016),并且它满足具有fc的RT = fc(KT)是一个完全连接的映射。
在人脸分类中,区分不同身份的关键是关键点周围的外观,如形状和颜色,但不同身份的关键点位置的差异很小。因此,面部身份不是这些地点的主要影响因素,但它仍然是相关的,因为不同的身份可能具有略微不同的位置。相反,姿势和视点变化具有更大的影响。因此,在面对齐中,隐藏层优选用于蒸馏,其通过设定α<β得到方程(7),如图1(b)所示。
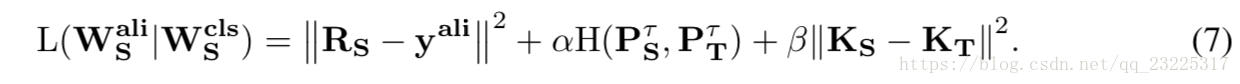
4.4 人脸识别
面部验证的任务是确定两个图像是否属于同一身份。 在验证中,triplet loss(Schroff等,2015)是一种广泛使用的度量学习方法(Schroff等,2015),我们将其用于模型蒸馏。 不失一般性,我们拥有与分类相同的身份标签,然后教师网络可以被训练为
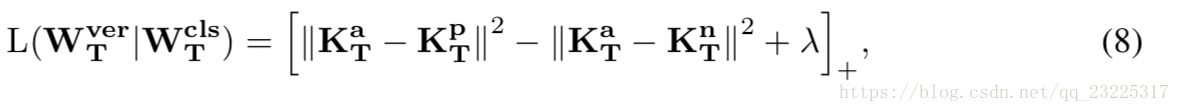
其中KaT,KpT和KnT分别是anchor,正和负样本的隐藏层,即a和p具有相同的身份,而a和n来自不同的身份。此外,λ控制正负对之间的边距。
与面部对齐类似,我们将隐藏层KT和软预测PτT视为蒸馏中的两个可能目标。事实上,分类侧重于身份的差异,即阶级间的关系,这种关系可以帮助说明两个图像是否具有相同的身份。因此,分类可以有助于提高验证性能。因此,在面部验证中,软预测对于蒸馏是优选的,其通过设定α>β来给出以下损失函数,如图1(c)所示。
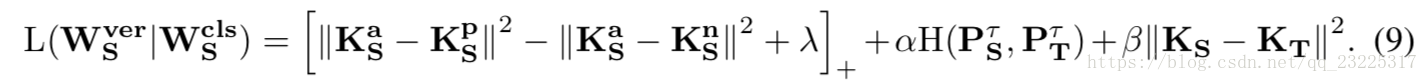
特别是,一些研究(Wang et al。,2017)通过在方程(8)中使用额外的softmax损失显示了其益处。 为了比较,我们还分别在方程(8)和方程(9)中加入softmax损失H(PT,ycls)和H(PS,ycls)以进一步增强。
如上所述,α和β应在不同任务的蒸馏中设置不同。 关键是衡量分类和非分类任务之间目标的相关性。 对于给定的任务,如果它与分类任务高度相关,则α>β是必要的。 尽管这个规则在理论上无法得到保证,但它提供了一些指导,以便在更多非分类任务中使用知识蒸馏。
5 实验评估
在本节中,我们给出了所提方法的实验评估。 我们首先详细介绍了实验装置,然后在面部分类,对齐和验证任务中展示了知识蒸馏的结果。
5.1 实验设置
数据:我们使用三个流行的数据集进行评估,包括CASIA-WebFace(Yi et al。,2016),CelebA(Liu et al。,2015)和MS-Celeb-1M(Guo et al。,2016)。 CASIA-WebFace包含10575个人和494414个图像,而CelebA有10177个人,202599个图像和5个关键点位置的标签。与前两个相比,MS-Celeb-1M是一个大型数据集,包含10万人,拥有840万张图像。在实验中,我们使用CASIA-WebFace和MS-Celeb-1M进行分类,使用CelebA进行校准,使用CASIA-WebFace进行验证。
评估:在所有数据集中,我们将它们随机分为80%培训和20%测试样本。在分类中,我们根据最大预测的身份是否与正确的身份标签匹配来评估top1准确度(Krizhevsky等,2012),以及LFW(Learned-Miller等,2016)数据库的结果(6000)通过计算正确验证的对的百分比来报告对)。在人脸矫正中,归一化均方根平方误差(NRMSE)用于评估比对(Wu等,2015);在验证时,我们计算测试样本中每对之间的欧几里德距离,并根据测试样本及其最近样本是否属于同一身份来报告top1准确度。特别是,LFW不用于验证,因为6000对不足以明显地看到不同方法的差异。
老师和学生:为了学习大量的身份,我们使用ResNet-50(He et al。,2016)作为教师网络,这足以解决我们的问题。对于学生网络,鉴于深度学生网络更适合知识蒸馏(Ba&Caruana,2014; Urban等,2017; Romero等,2015),我们保持相同的深度,但除了卷积核的数量在每层中分别为2,4和8,分别给出ResNet-50/2,ResNet-50/4和ResNet-50/8。
预处理和训练:给定图像,我们将其大小调整为256×256,其中随机裁剪并翻转具有224×224的子图像。特别是,我们不使用平均减法或图像白化,因为我们在输入数据之后立即使用批量标准化。在训练中,批量大小分别设置为256,64和128用于分类,对齐和验证,并且采用Nesterov加速梯度(NAG)以实现更快的收敛。对于学习率,如果从头开始训练网络,则使用0.1;如果网络初始化,则使用0.01继续,并且在每个速率中使用30个epochs。此外,在蒸馏中,学生网络用在线生成的教师网络的目标进行训练,并且通过交叉验证将温度τ和边缘λ设置为3和0.4。最后,平衡项α和β有许多可能的组合,我们稍后会说明如何通过实验技巧来设置它们。
实验中的符号:(1)Scratch:学生网络未初始化; (2)Pretrain:学生网络通过任务特定的初始化进行训练; (3)Distill:学生网络用Wcls初始化 (4)soft:软预测Pτ; (5)Hidden:隐藏层KT。
5.2 与以前的研究比较
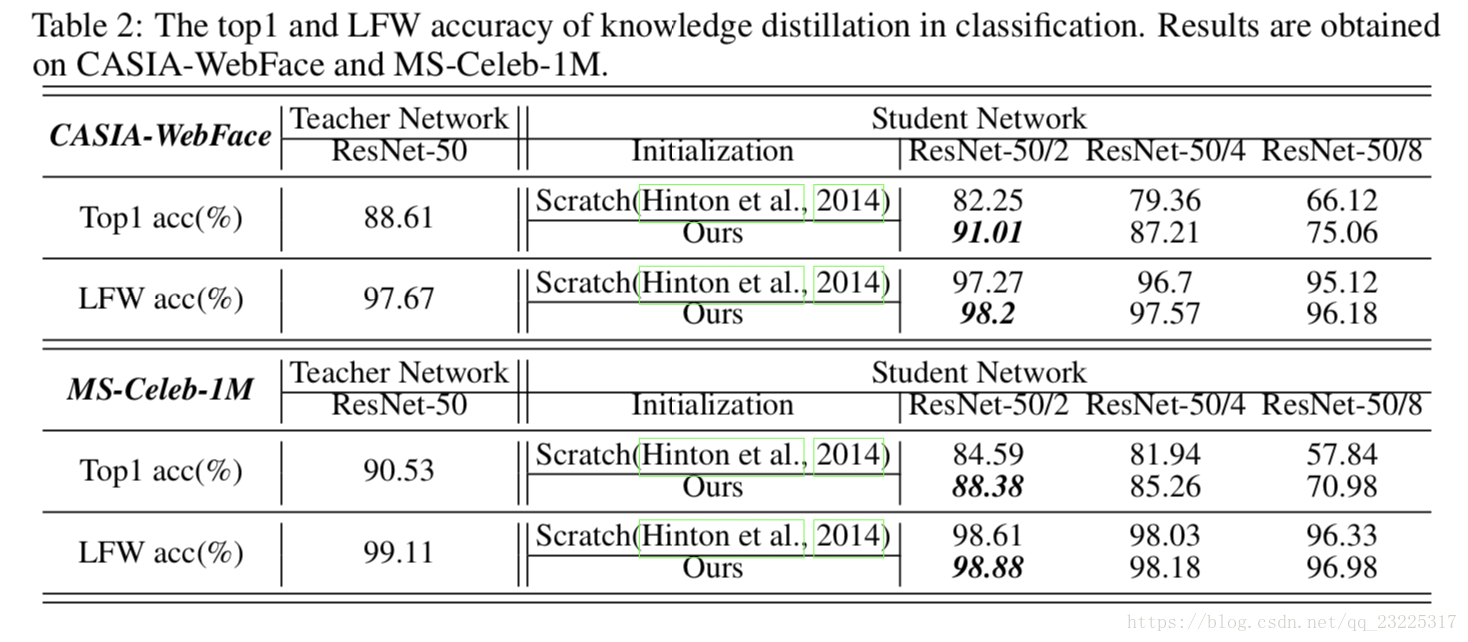
在这一部分中,我们将初始化技巧与之前的分类研究进行了比较。 表1显示了不同目标和初始化的比较。 从第一张表中可以观察到,没有任何初始化,软预测达到最佳蒸馏性能,即61.27%。 基于最佳目标,第二个表格给出了蒸馏中不同初始化的结果。 我们看到我们的完全初始化获得了75.06%的最佳准确度,这比其他方法高得多,即比Scratch和Fitnet高10%和5%(Romero等,2015)。 这些结果表明,学生网络的完全初始化可以在分类中提供最高的可转移性,并且还证明了这种简单技巧的有效性。

基于最佳初始化和目标,表2显示了CASIA-WebFace和MS-Celeb-1M的面部分类的蒸馏结果,我们有三个主要观察结果。 首先,通过完全初始化训练的学生网络可以获得比从头开始训练的学生网络的大的改进,这进一步证明了在大规模情况下初始化技巧的有效性。 其次,一些学生网络可以与教师网络竞争,甚至可以大大超过教师网络,例如: 在CASIA-WebFace数据库中,ResNet-50/4可以与教师网络竞争,而ResNet-50/2比排名前1的教师高约3%。 最后,在大型MS-Celeb-1M中,学生网络不能超过教师网络,只能具有竞争力,这表明知识蒸馏对于大量身份仍然具有挑战性。
5.3 人脸对齐
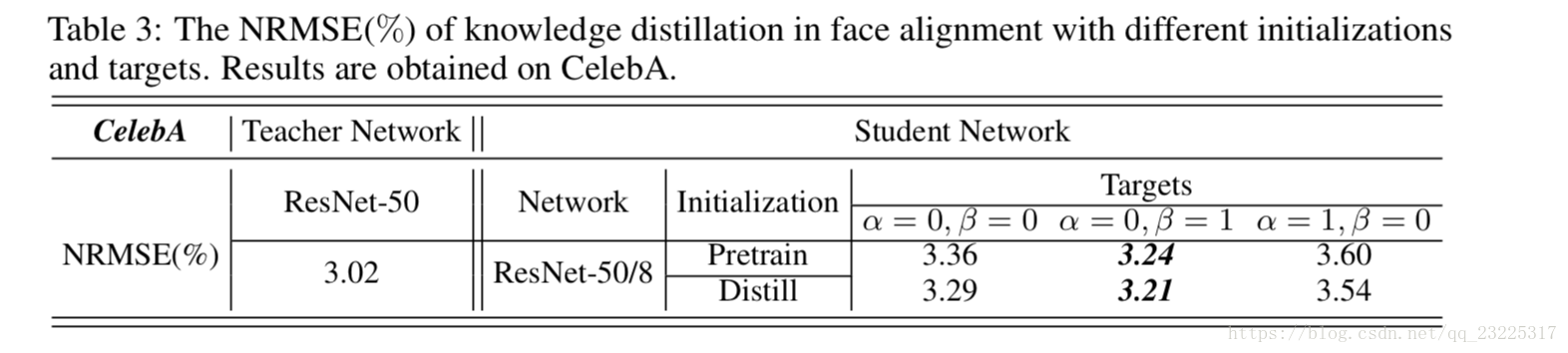
在这一部分,我们给出了人脸对齐蒸馏的评价。表3显示了在CelebA上具有不同初始化和目标的ResNet-50/8的蒸馏结果。我们仅考虑ResNet-50/8的原因是面部对齐是一个相对容易的问题,并且大多数研究使用浅层和小型网络,因此深度ResNet-50需要大的压缩率。一个重要的是如何在方程(7)中设置α和β。由于存在许多可能的组合,我们通过测量它们各自的影响来使用一个简单的技巧,并通过设置α= 0或β= 0来消除负面影响的目标;如果它们都具有正面影响,则应设置α> 0,β> 0以使两个目标保持蒸馏。
如表3所示,当使用P retrain和Distill的初始化时,α= 1,β= 0(软预测)总是降低性能,而α= 0,β= 1(隐藏层)得到一致的改进,其中意味着隐藏层在面部排列的蒸馏中是优选的。在表3中可以观察到Distill具有比P retrain更低的错误率,这表明Wcls S在高级表示上具有比特定于任务的初始化更高的可转移性。此外,Distill和α= 0,β= 1可获得最高的蒸馏性能3.21%,并且可以与教师网络(3.02%)竞争。
5.4 人脸验证
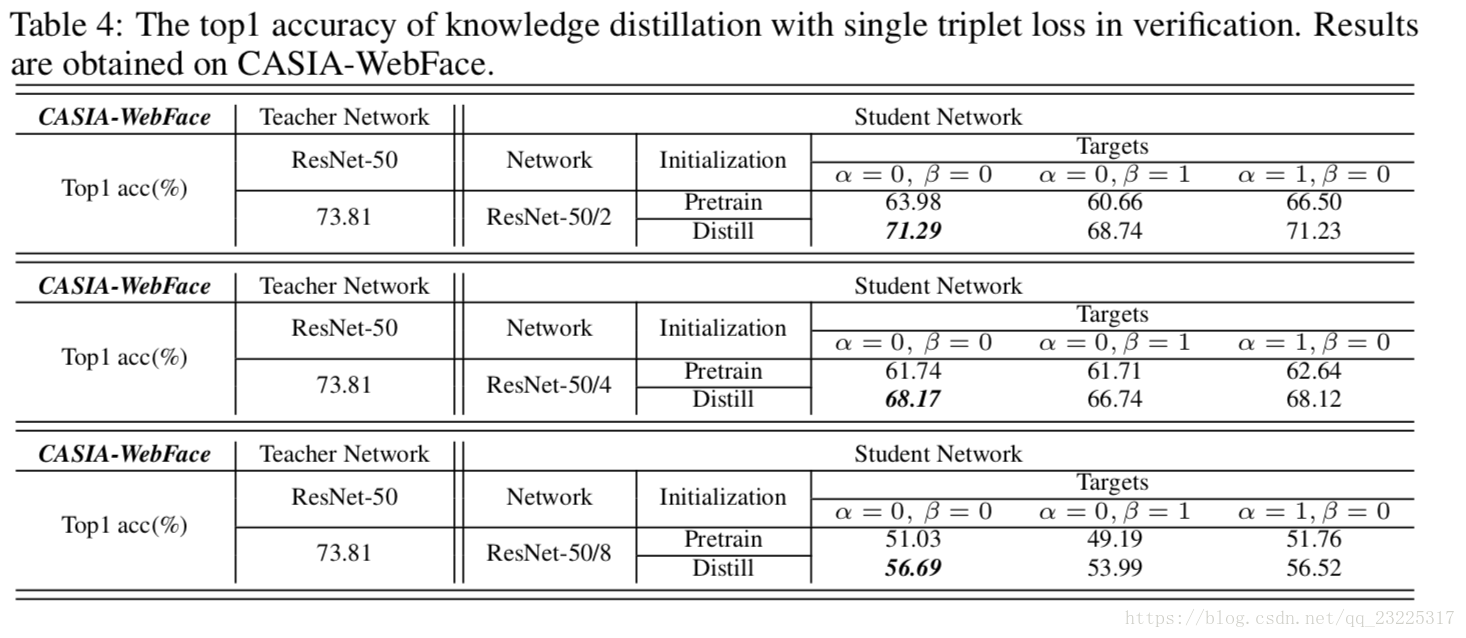
在这一部分,我们在面部验证中给出了蒸馏的评价。 与对齐类似,我们以相同的方式选择α和β。 表4显示了CASIA-WebFace上不同初始化和目标的验证结果,结果由方程(9)给出。 可以观察到,无论使用哪个学生网络或初始化,α= 0,β= 1(隐藏层)总是降低基线性能,而α= 1,β= 0(软预测)保持几乎相同。 因此,我们丢弃隐藏层并仅使用软预测。
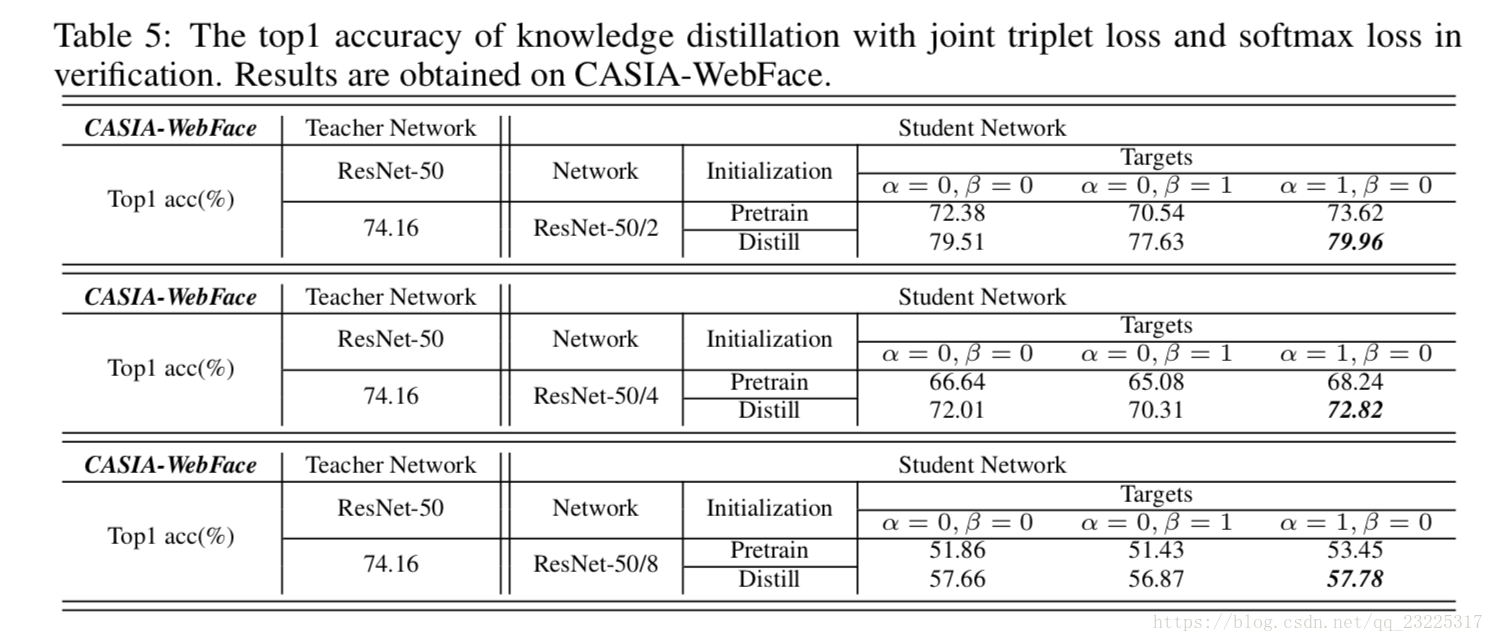
表4中一个有趣的观察结果是α= 0,β= 0总是获得最佳性能,而目标根本不起作用。 一个可能的原因是分类目标不自信,即ResNet-50在分类中的最高准确度仅为88.61%。 为了提高分类能力,我们在方程(8)和方程(9)中增加了额外的softmax损失,结果如表5所示。 我们看到ResNet-50/2和ResNet-50/4的准确性已经获得了显着的改进,这意味着不够自信的分类目标无助于蒸馏。 但是,随着额外的softmax损失,学生的工作可以通过身份标签调整学习。 结果,α= 1,β= 0可以获得最佳性能,甚至远高于教师网络,例如,具有Distill的ResNet-50/2的79.96%并且α= 1,β= 0。
6 总结
在本文中,我们将面部识别作为一个突破点,并提出了两个非分类任务的知识蒸馏,包括面部对齐和验证。我们通过将蒸馏知识从面部分类转移到面部对齐和验证来扩展先前的蒸馏框架。通过选择适当的初始化和目标,非分类任务的蒸馏可以更容易。此外,我们还为非分类任务的目标选择提供了一些指导,我们希望这些指南可以帮助完成更多任务。对CASIA-WebFace,CelebA和大型MS-Celeb-1M数据集的实验证明了该方法的有效性,该方法为学生提供了在适当的压缩率下具有竞争力或超过教师网络的网络。此外,我们使用常见的初始化技巧来进一步提高分类的蒸馏性能,这可以促进非分类任务的蒸馏。 CASIA-WebFace上的实验证明了这个简单技巧的有效性。