大数据的实时计算与离线统计 整理学习
1. 实时计算 Apache Storm
流程 :业务数据、消息队列、Storm实时编程、Redis、数据展示(秒级计算)
应用场景:对数据处理的时效性要求较高,及时响应,秒级甚至毫秒级延迟。
example

数据处理:对于数据的处理,主要分为3大阶段:数据采集、数据处理、数据的可视化
-
数据采集:
1)Magpie实时采集:自主研发,对线上生产数据库压力非常小,负责实时的监听、采集数据库binlog日志,再将数据解析、转换统一格式、压缩、写入到JDQ-实时数据总线;
2)SDK实时上报:开放接口,用户自定义格式,通过SDK主动实时上报数据到JDQ-实时数据总线; -
数据总线
JDQ实时数据总线:基于Kafka实现的高吞吐率分布式消息队列,以Topic为单位存储实时数据对象,是实时数据采集与下游数据使用者之间的桥梁;
1)平台提供SDK,通过鉴权认证,保障数据安全可靠
2)限速处理,保障网络负载均衡;
3)集群读写分离,跨数据中心灾备,保障集群稳定;
4)产品化Client管理,通过web端查看客户端运行情况,对消费积压进行监控报警配置,提升用户体验 -
数据处理
1)JRC实时计算平台:基于storm实现,使用JRC平台的SDK,开发实时计算程序,将计算后的数据写到存储或落地到离线数据仓库、集市;
2)其他实时消费程序:用户基于平台提供的SDK自主开发消费程序,将计算后的数据写入到相关数据应用产品存储;
3)准实时数据仓库:为提高对业务的响应时效性,弥补T+1离线仓库无法查询当天数据的不足,大数据平台推出准实时数据仓库,目前可将线上生产数据还原成小时级别的Hive表或将用户上报的数据按分钟级别写入HDFS文件; -
数据可视化
实时数据的可视化按照不同的业务需求,酌情采用实时、离线的数据应用产品进行数据可视化、分析。

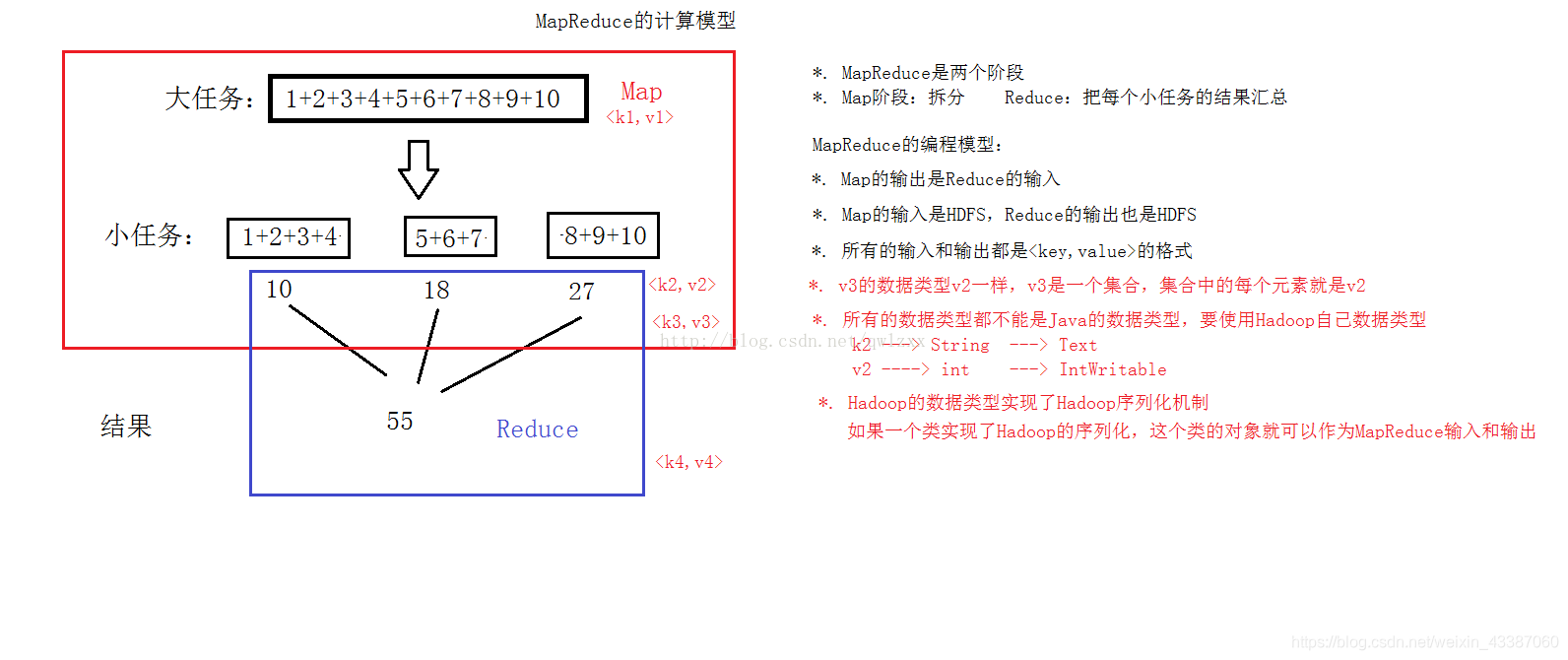
2. 离线统计 MapReduce
流程 :不同数据源获取数据、Hadoop集群数据、计算(Hive、Spark、MapReduce)、数据展示(T+1计算)
1)MapReduce是处理HDFS上的数据
2)MapReduce的思想来源是PageRank(搜索排名),原理是进行分布式计算