输入:{(x1,y1),(x2,y2),..(xN,yN),},其中yi={c1,c2...ck},i=1,2...N,需要预测的特征向量x
输出:x对应的类别
算法:
- 在训练集中找到与x最近邻的k个点
- 对这个k个点的类别统计判断,多数表决
k近邻当k为1时,即退化为最近邻,k近邻没有显式的学习过程。
三要素:k值选择,距离度量,分类决策规则。
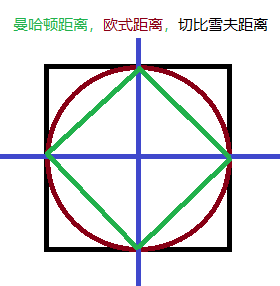
三种距离,曼哈顿,欧式距离,切比雪夫距离
输入:{(x1,y1),(x2,y2),..(xN,yN),},其中yi={c1,c2...ck},i=1,2...N,需要预测的特征向量x
输出:x对应的类别
算法:
k近邻当k为1时,即退化为最近邻,k近邻没有显式的学习过程。
三要素:k值选择,距离度量,分类决策规则。
三种距离,曼哈顿,欧式距离,切比雪夫距离