版权声明:该版权归博主个人所有,在非商用的前提下可自由使用,转载请注明出处. https://blog.csdn.net/qq_24696571/article/details/85844991
介绍:
- Google发布的三个产品:Google File System / MapReduc / BigTable的详细设计论文 , 奠定了风靡全球的大数据算法的基础.
- MapReduce分布式离线计算框架用于大规模数据(入门级是1TB)的并行计算. 将程序云星宇hadoop等分布式系统上
- MapReduce的概念是Map(映射)和Reduce(归约)
- Map(映射)将数据切片,把一组数据映射成键值对.(分)
- Reduce(归约)保证所有映射的切片都共享相同的键组.(合)
- 分布式计算,就是将数据分解成多个部分,让多台计算机进行处理,提高计算效率,缩短计算时间.
MapReduce计算框架的组成
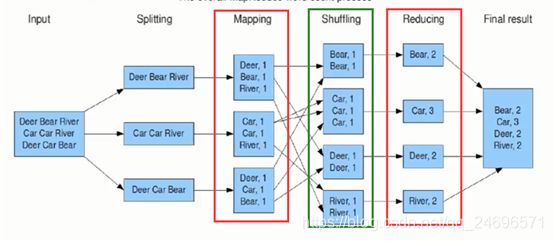
- Input:数据文件
- Splitting:数据切分成小文件
- Mapping:将小文件映射成一条条Key和Value数据
- Shuffling:按照需求进行数据清洗
- Reducing:统计结果
- Final result:汇总数据结果
- Sguffling属于Reducing阶段,被包含于Reducing阶段
Mapper
- Mapper负责把海量的数据进行分解
- 工作的计算机变多,每台计算机工作量减少,效率变高
- 就近计算 , 会被分配到存放所需数据的节点进行计算
- 各计算机并行计算,彼此之间几乎没有依赖.
- 工作流程图:
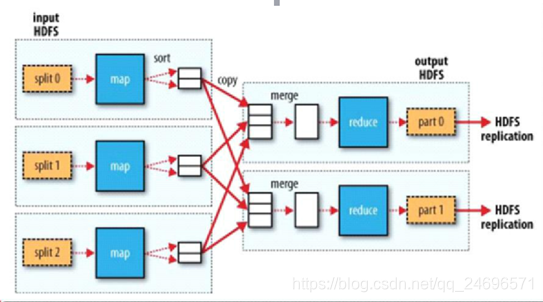
- 从切割到不同服务器上的小文件里将数据映射成一条条键值对的信息(Map集合)
- 进行排序
- 将数据从不同的服务器拉取之后进行合并
- 落地到磁盘
- reduce统计成结果
- Map在具有数据的节点服务器上运行,对数据进行处理
- Map处理数据的结果就放在这些节点服务器(DateNode)上,落地到本地磁盘 .
- Reduce运行会从这些服务器(DateNode)本地磁盘拉取结果 , Reduce处理完之后清空DateNode本地磁盘上的数据
Reduce
- Reduce负责汇总数据,处理Mapper阶段之后的结果
- MR源码中提到了了Shuffle属于Reduce阶段
- Reducer的数量可以在mapred-site.xml中的mapred.reduce.tasks中配置.默认是1.
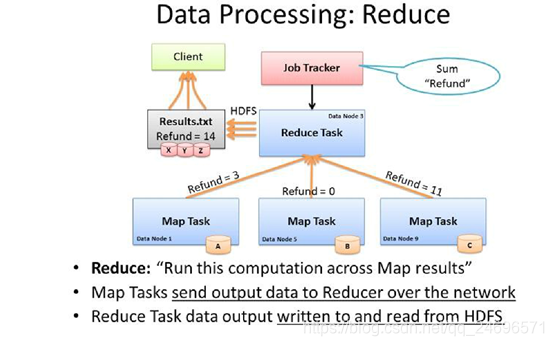
- reduce运行在具有需要计算的数据的服务器节点上(DateNode),不论DateNode和Reducer的数量数量多少,Reduce都是在DateNode节点上并行运行的
- reduce运行的结果储存在HDFS上
- 官方建议reduce运行数量的建议:0.95或1.75
- 0.95: 其实是设置为1,电脑资源性能也会产生消耗,0.05. map只要已完成,reduce就立刻启动.
- 1.75: 就是2,相比于1起到了负载均衡的效果.但reduce是并行的,两台reduce一起运行会产生争抢资源的问题,耗性能.
Shuffle
- shuffle是Mapper和Reduce中间的步骤,它属于Reduce.只是因为比较重要,所以单拿出来说明.
- shuffle把mapper阶段的输出通过hashcode进行取模(hash(key)% R),分成N份文件,然后根据key值输出到指定的reduce进行处理
MapReduce执行过程详解
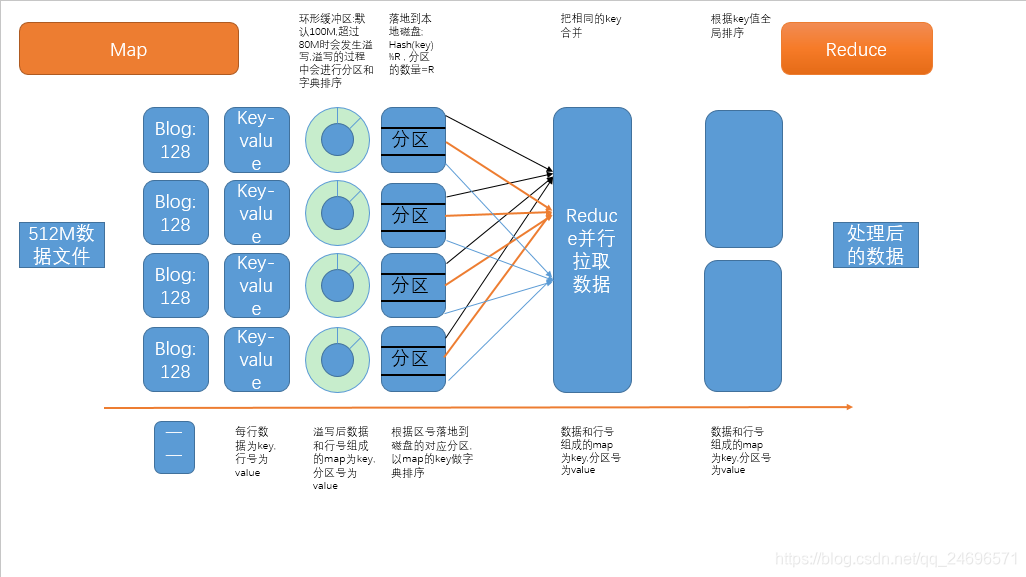
MapReduce架构
- MapReduce是主多从架构
- 主 JobTracker: task运行于TaskTracker之上,负责调度分配任务,如果有失败的task就重新分配给它任务到其他的节点.
JobTracker负责总的任务调度,TaskTracker负责具体的任务调度.
一个hadoop集群中只有一个JobTracker,它运行在NameNode节点上.- 从 TaskTracker
TaskTracker负责执行每个MapTask和ReduceTask任务,TskTracker主动和JobTracker通信,接收作业.
为了减少网络带宽,TaskTracker最好运行在HDFS的DateNode上.