Hadoopd分布式计算框架——MapReduce
一、MapReduce简介
1. 概念
MapReduce是基于Hadoop的分布式计算框架。
起源于Google,它将大型数据操作作业分解为可以跨服务器集群并行执行的单个任务,适用于大规模数据处理场景,每个节点处理存储在该节点的数据,每个job包含Map和Reduce两部分。
2.设计思想
构建抽象模型:Map和Reduce,简化并行计算的编程模型,使开发人员专注于业务逻辑实现,专注于实现Mapper和Reducer函数。
3.MapReduce优缺点
优点:易于编程、可扩展性、高容错性、高吞吐量
缺点:难以实时计算、不适合流式计算
4.MapReduce任务执行涉及进程
一个完整的mapreduce程序在分布式运行时有三类实例进程:
- MapReduceApplicationMaster:负责整个程序的过程调度及状态协调。
- MapTask:负责map阶段的整个数据处理流程。
- ReduceTask:负责reduce阶段的整个数据处理流程。
二、MapReduce框架原理
①:MapReduce工作流程
MapReduce执行流程图:
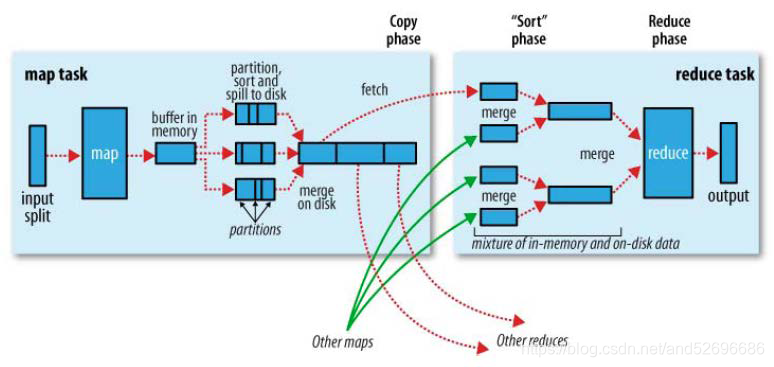
流程详解:
1)split阶段
首先mapreduce会根据要运行的大文件来进行split,每个输入分片(input split)针对一个map任务,输入分片(InputSplit)存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组。输入分片(InputSplit)通常和HDFS的block(块)关系很密切,假如我们设定HDFS的块的大小是128MB,我们运行的大文件是128x10MB,MapReduce会分为10个MapTask,每个MapTask都尽可能运行在block(块)所在的DataNode上,体现了移动计算不移动数据的思想。
2)map阶段
map阶段就是执行自己编写的Mapper类中的map函数,Map过程开始处理,MapTask会接受输入分片,通过不断的调用map()方法对数据进行处理。处理完毕后,转换为新的<KEY,VALUE>键值对输出。
3)Shuffle阶段
shuffle阶段主要负责将map端生成的数据传递给reduce端,因此shuffle分为在map端的过程和在reduce端的执行过程。具体过程如下:
(1)MapTask收集map()方法的输出<KEY,VALUE>对,放到内存缓冲区(称为环形缓冲区)中,其中环形缓冲区的大小默认是100MB。
(2)环形缓冲区到达一定阈值(环形缓冲区大小的80%)时,会将缓冲区中的数据溢出本地磁盘文件,这个过程中可能会溢出多个文件。
(3)多个溢出文件会被合并成大的溢出文件。
(4)在溢出过程中,及合并的过程中,都要调用Partitioner进行分区和针对key进行排序sort。
(5)合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程。
4)Reduce阶段
Reduce对Shffule阶段传来的数据进行最后的整理合并。Reduce根据自己的分区号,去各个maptask机器上取相应的结果分区数据。ReduceTask会取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序),从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法,生成最终的输出文件。
5)注意
Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
缓冲区的大小可以通过参数调整,参数:io.sort.mb 默认100M。