MapReduce
分布式计算思想
思想引入
首先, 来看三个问题:
-
假设有1T的文件, 文件中的每一行都是一个数字; 如何在一台48core, 64G内存的服务器上处理这个大文件, 将这个大文件排序呢?
-
假设有两个很大的文件(内存只能读入一小部分), 文件中的每一行都是一个url字符串, 共有10亿行. 如何在一台48core, 64G内存的服务器上处理这两个大文件, 将这两个大文件中相同的url找出呢?
-
在一座山上有三个山头, 每个山头都有红木, 橡木和樟木, 有三个工人分别负责在一个山头砍树, 砍好的树木由三辆分别运送红木, 橡木和樟木的运输车运送到位于其他地方的三家加工厂, 这三家加工厂分别加工红木, 橡木和樟木. 整个处理流程应该是怎样的?
1. 对于第一个问题, 这个1T的文件是无法完全读入内存中, 那么我们应该怎么做呢? 可以想到的是, 将这个大文件按行从上而下分割成一个个小文件分别读入服务器内存中处理, 服务器对每一个小文件进行排序, 最后再将每个内部有序的小文件进行归并排序, 从而产生一个有序文件.
整个过程的流程图如下:
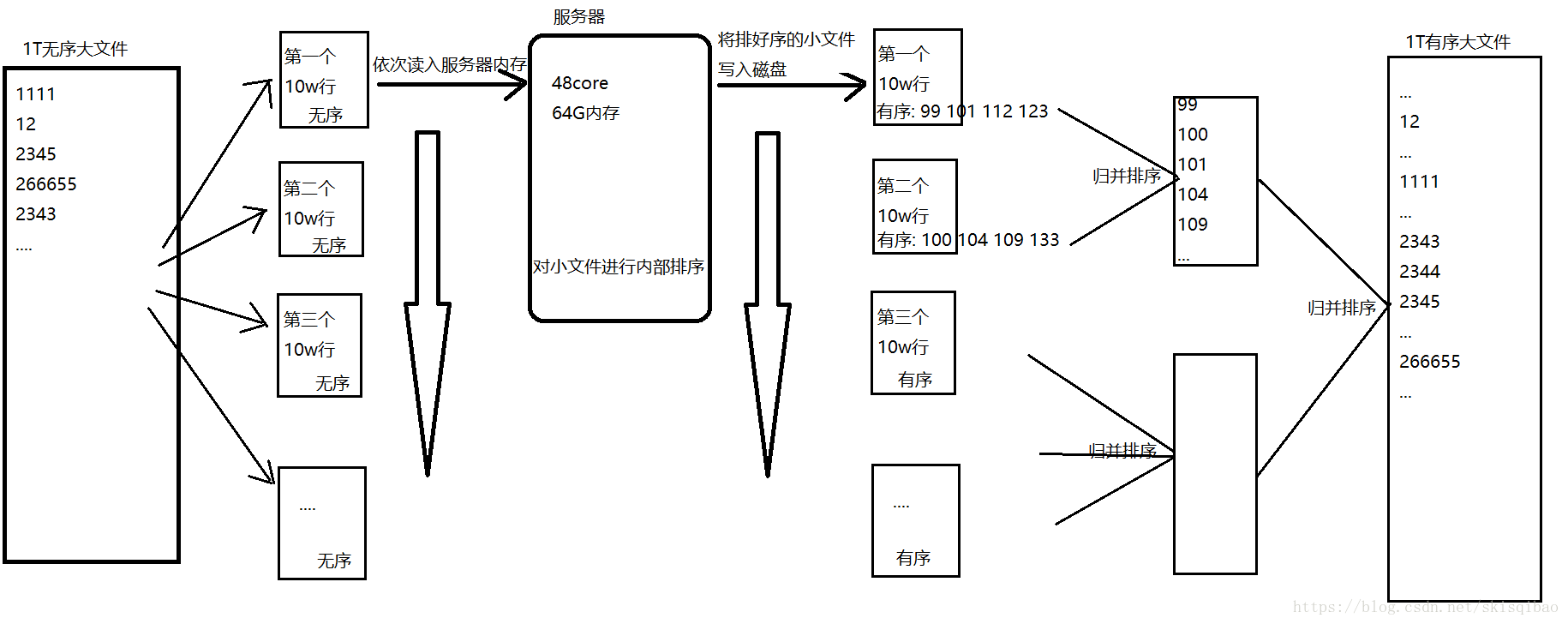
虽然上述流程能够完成需求, 但是它存在一个问题----三次磁盘IO(第一次是切割文件时需要读写一次, 第二次是服务器排序时读写一下, 第三次是在归并排序时读写一次). 像这种磁盘IO是非常耗时的, 从而使得处理效率降低. 有什么地方可以改善吗?
答案是有的. 关键就在于第一次怎么切割, 第一次切割时, 去限定每个小文件的数值范围, 比如说第一个小文件的数值范围是0~100, 第二个是101~200, 以此类推. 这样当服务器对每个小文件内部排好序时, 只需将这些小文件拼接即可.
整个过程的流程图如下:
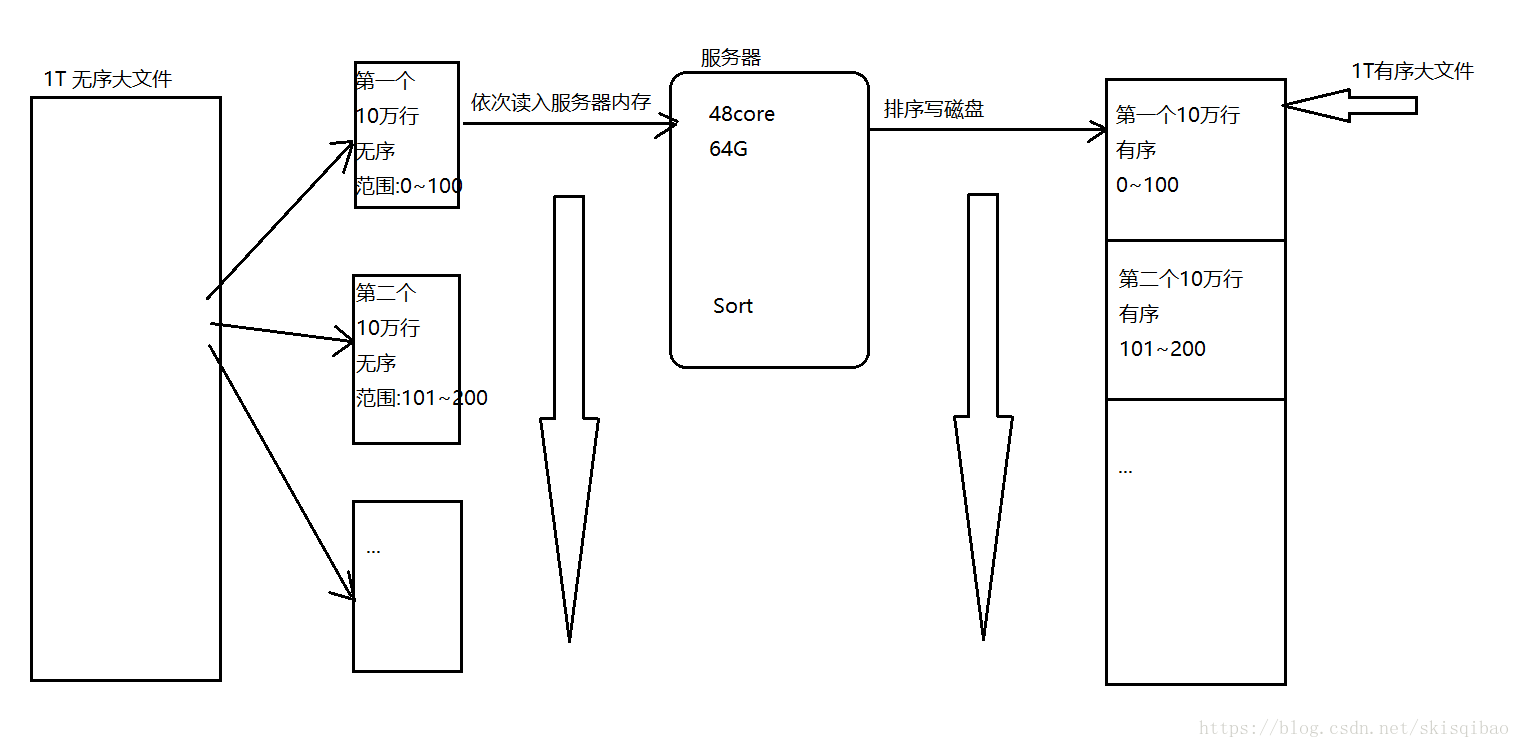
上述流程相较于第一种减少一次IO(归并排序的IO), 从而提高处理的效率.
2. 对于第二个问题, 还是要让整个过程只有两次磁盘IO. 首先要知道每一个字符串对应一个HashCode编码. 假设这两个文件都要拆成1000个小文件. 那么切割策略就有了: 先将每一个url的HashCode编码计算出来, 然后将这个值与1000取模, 每个" 模值 " 作为一个小文件的标识. 那么, 两个大文件中相同的url一定在模值相等的切割后的小文件中.
整个过程的流程图如下:
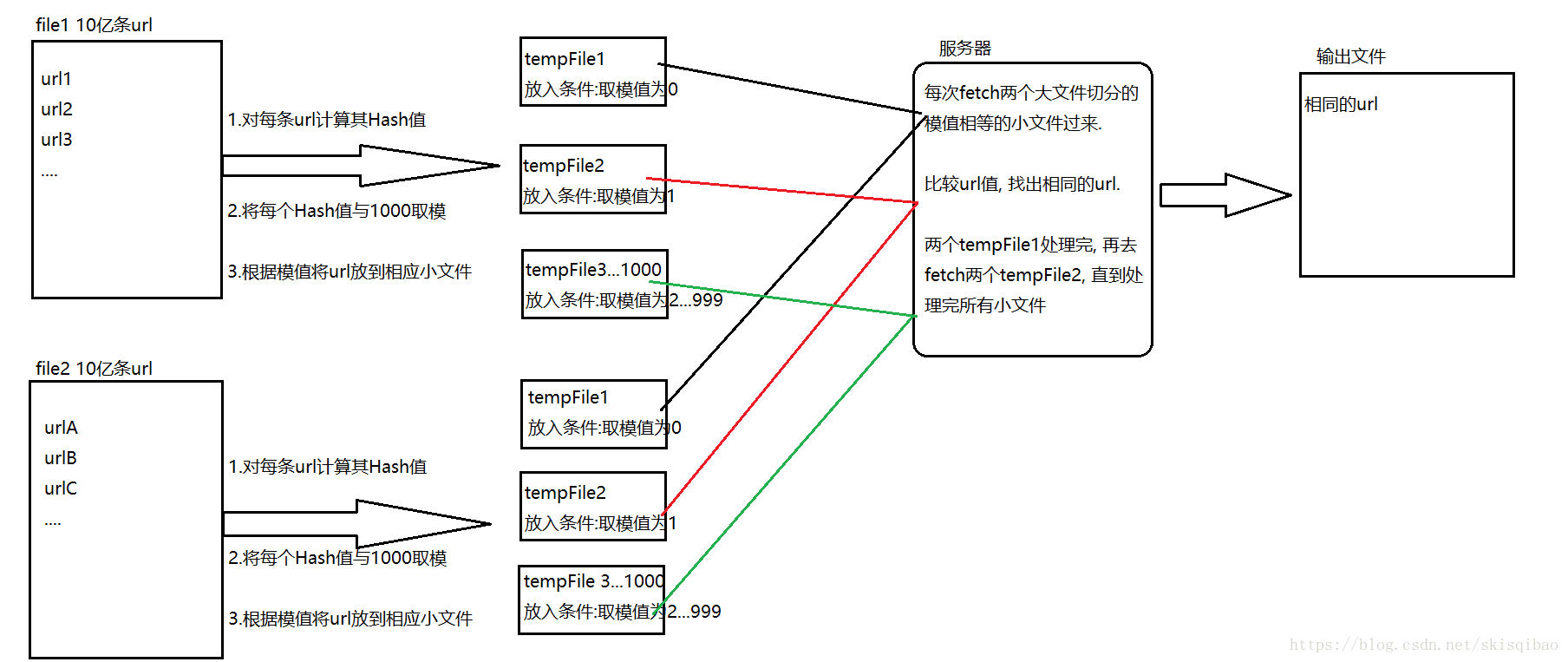
上述流程是一台服务器再处理, 假设现在有1000台服务器, 试想会是什么样情景呢?
整个过程的流程图如下:
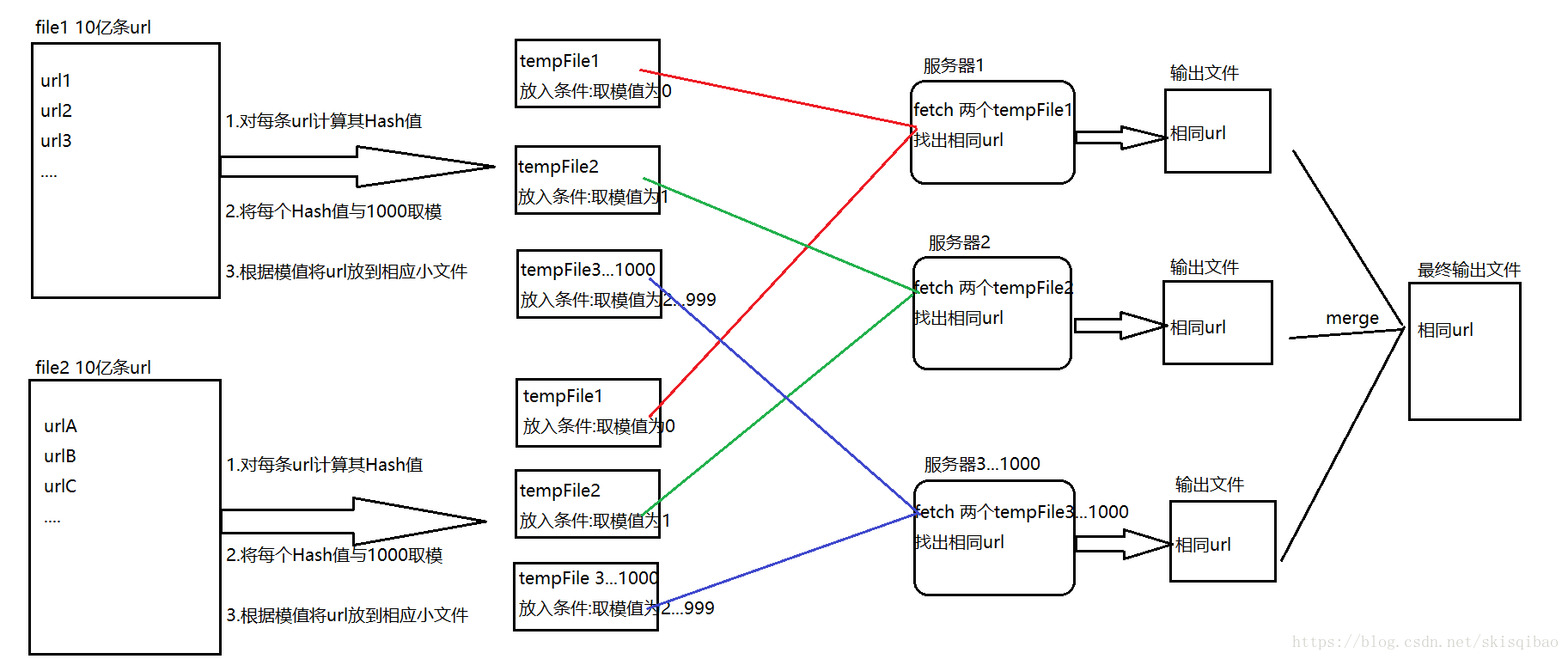
上述流程的思想已经很接近MapReduce处理的思想.
3. 对于第三个问题, 通常会认为伐木工砍完树之后, 将去掉树枝的树干运送到加工厂. 加工厂加工后还会剩下一批废料, 这些废料也占用了"运输通道", 对它们的传输是无用的, 因此也降低生成的效率, 那能否将这些无用的废料从"运输通道" 中除去呢?
很简单, 只需要在山头那边对树木进行一定程度的加工不就可以了吗. 例如, 可以先分别加工出红木, 橡木和樟木的桌面, 桌腿再进行运输, 假设一次运输只能运送同一个组件, 那么这会造成运输次数的增加, 也降低了运输效率.
既然如此, 桌面桌腿加工出来了, 再对它们进行简单组装形成半成品, 运输时直接输送半成品.
可以看到, 我们在山头上对树干进行了两次加工, 分别产出桌面桌腿和桌子的半成品, 这一过程在MapReduce中称为Combiner. Combiner的过程减少了山头输出的数据, 类似于减少了网络IO
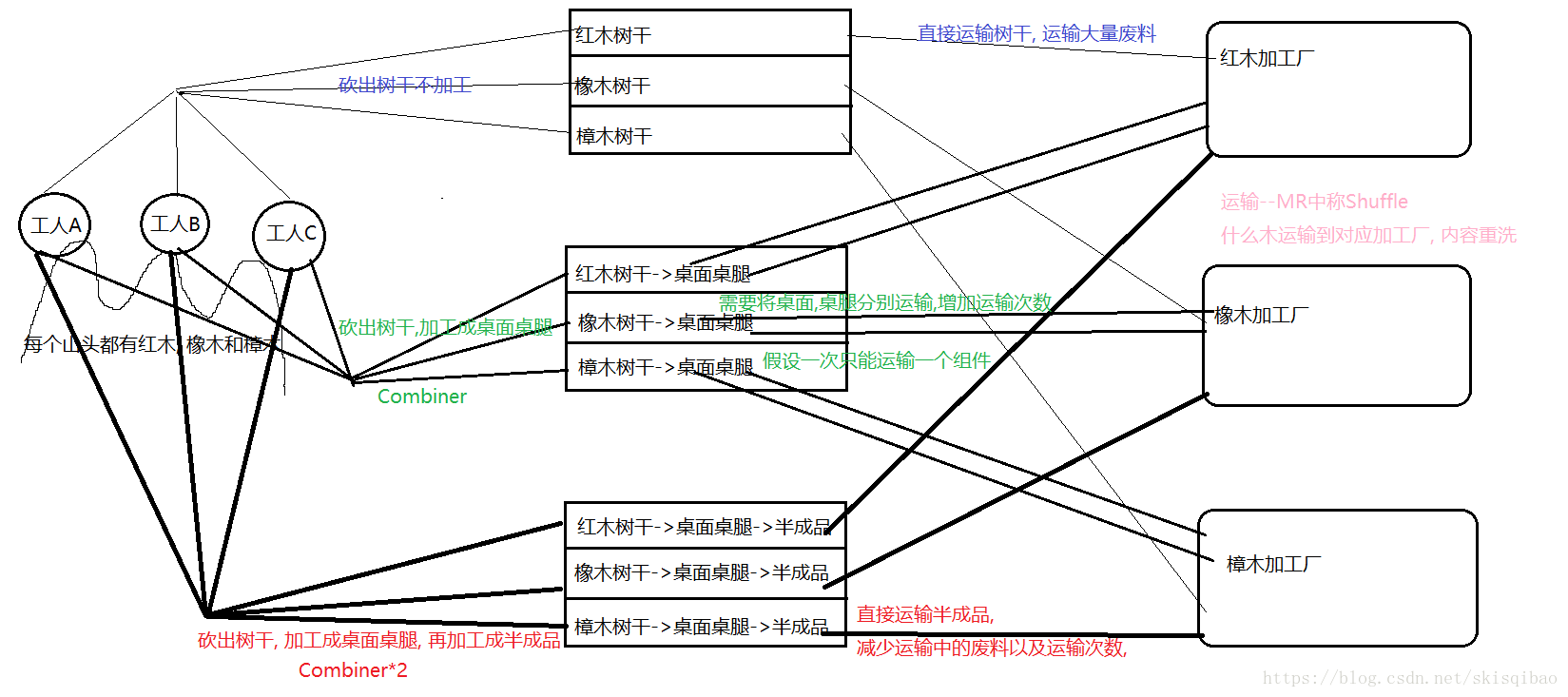
上述第三个过程就跟MapReduce的过程类似了. MapReduce主要分两个过程Map和Reduce. 这里工人相当于Map; 每个山头上的组装称为combiner; 将半成品运输到各个工厂称为shuffle; 将运输过来的半成品组装成成品的过程称为reduce;
MapReduce处理流程
官方配图:
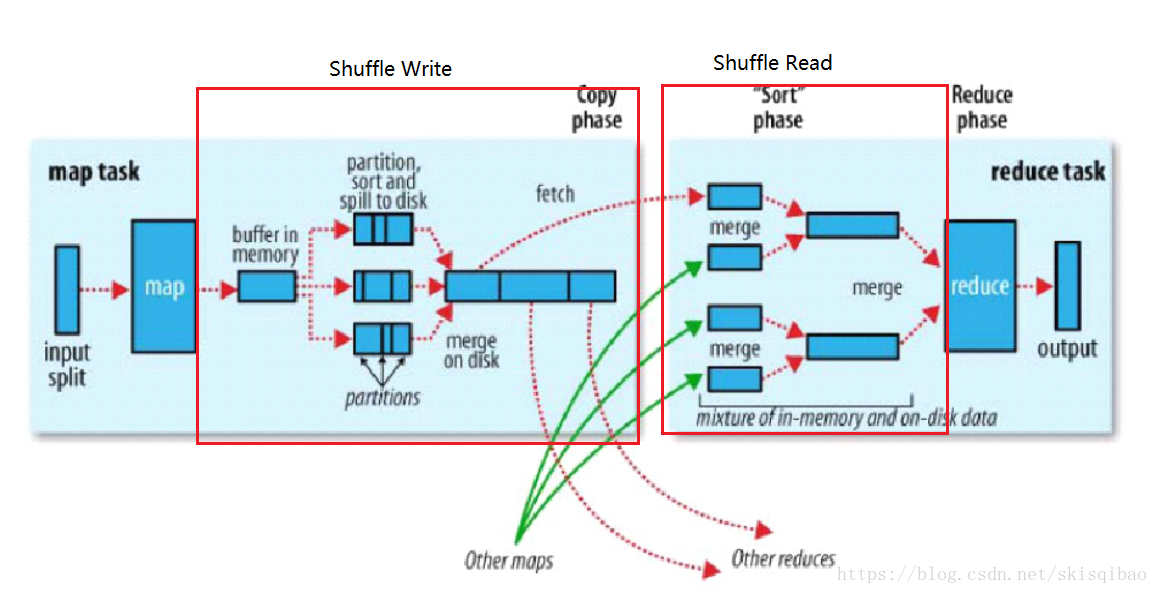
MapReduce 具体分为四步:
- Map 阶段;
- Shuffle Write阶段
- Shuffle Read阶段
- Reduce 阶段
MapReduce中的几个名词:
-
map task – Map端开启的处理线程, 一个map task 读取的数据称为一个split(切片),
-
split – 切片的概念, 假设数据存放在HDFS上, 每一个map task读取的数据就是一个切片,但这并不是在读取前就切好的. split的默认大小与一个block的大小一致, 即block数 = split数 = map task数.
也可设置split与block之间的大小关系, 例如, 2block = split = map task; 1/2block = split = map task.也可设置split与block之间的大小关系, 例如, 2block = split = map task; 1/2block = split = map task.
split是一个逻辑概念, map task会一行一行的读取某个block中的数据, 为防止数据被切分, 它还会多读取下一个block的第一行数据(HDFS中按照字节存储数据, 所以极有可能一条数据被拆分存放在两个block中). -
key-value : MR处理过程中, 数据都是通过键值对的形式传递的. 起初key值为block中一条记录的偏移量(long类型), value为block中的数据(String类型), 两个偏移量之间是一条记录. 经过map, reduce处理过后, key-value内容根据需求而定.
-
map – 对数据切分的方法, 输入类型为<LongWritable, Text>, 输出类型<key, value>由需求决定.
-
HashPartitioner – 默认分区器. 相同的分区由相同的reduce task处理, 分区策略: 经map处理后, 将key的Hash值与reduce task的个数(NUM)取模, 模值相同的key将放在同一个分区中.
-
buffer in memory – 内存缓冲区, map对split内容处理后先写入内存缓冲区, 进入缓冲区的每一条记录都由三部分组成: 分区号, key, value. buffer大小默认100M, 分为两份, 一份80M, 一份20M.
当达到溢写比例(buffer中约有80M数据)时, 会将这80M数据封锁, 然后对数据进行聚合, 排序, 排序时先按照分区排序, 分区相同的再按照key排序. 排序完成后就将数据溢写到磁盘上. 每次溢写产生一个磁盘小文件.
聚合排序过程中, 如果还有内容继续往buffer中写的话, 这些内容将被写入buffer剩余的20M中. -
merge – map阶段的merge基于磁盘小文件进行合并, 合并时按照分区号进行合并, 将相同分区号的数据放在同一个大分区中. 合并完成后会对相同分区的数据进行排序.
– reduce阶段的merge合并时会对每一个有序的磁盘小文件进行排序, 这些小文件已经属于同一个分区. 最后合并成一个磁盘大文件时, 会根据key值进行分组, key值相同的为一组. -
fetch – reduce task进程从map task产生的磁盘大文件中拉取数据, 拉取的数据先放入Reduce端的内存中, 内存大小默认为1G的70%. 内存中数据达到一定的溢写比例后, 就会将内存中的数据溢写到磁盘小文件中, 溢写之前也会进行排序.
-
reduce – 对有序的大文件中key值相同的一组数据处理的方法, 输入参数由map端的输出参数决定, 输出参数由需求决定, 都是key-value的形式.
-
reduce task – Reduce端开启的处理线程, 一个reduce task产生一个output文件 .
MapReduce执行流程:
假设MR处理的数据存储在HDFS上, HDFS上的数据是以block的形式存放.
假设有三个map task和三个reduce task线程.
-
map task 线程
执行流程
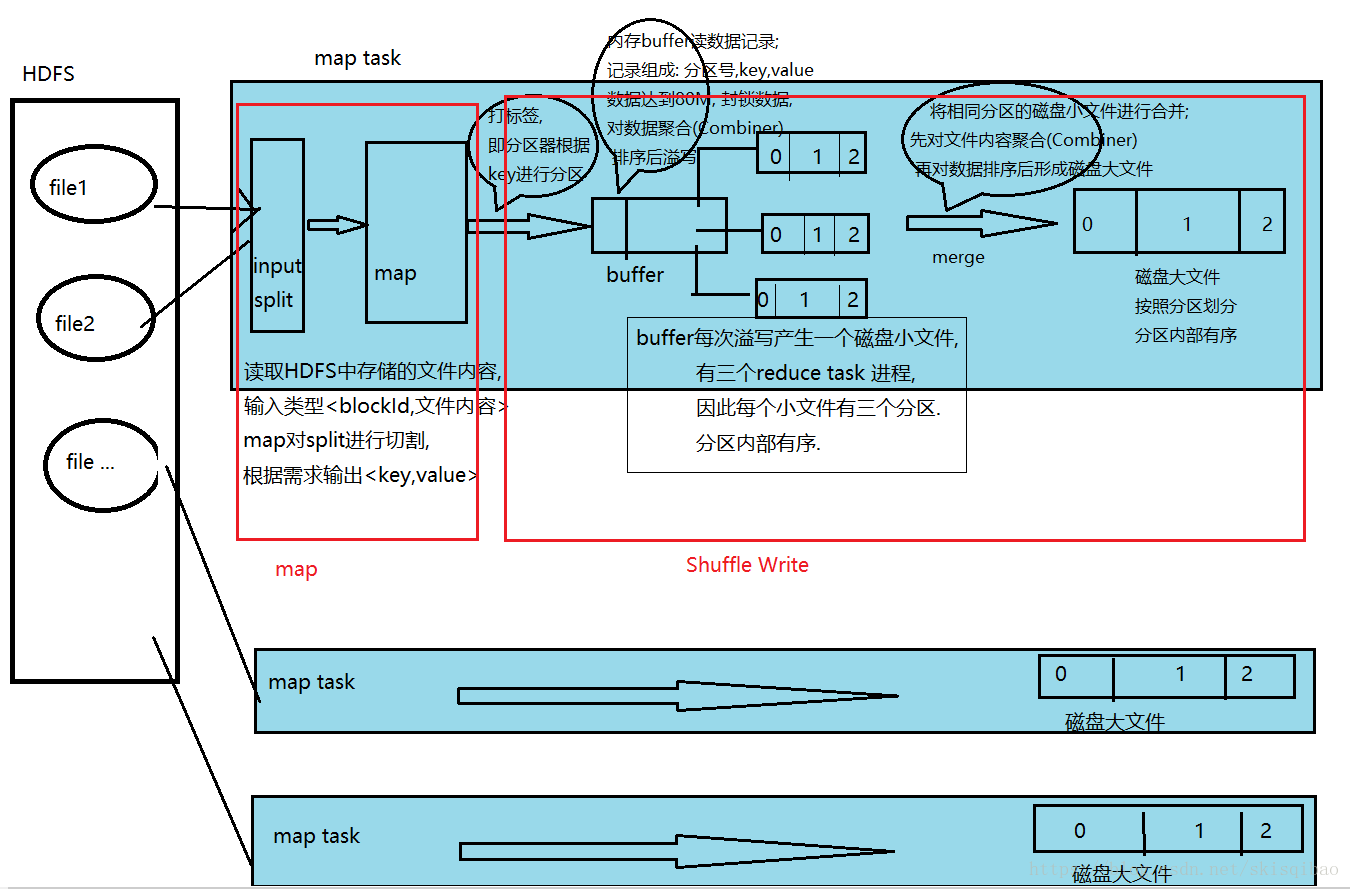
1.1 map阶段
1.1.1 map task从HDFS中读取文件内容, HDFS中文件以block块的形式存在. 整个过程数据以键值对的形式传输, 输入map前的key为文件中一条数据的偏移量, value为这条数据的内容.
1.1.2 map方法根据需求将传入的value进行切割, 再根据需求设置输出类型的key和value.1.2 shuffle write阶段
1.2.1 分区器分区(打标签), 分区的目的就是让同一个分区的数据被同一个reduce task 来处理. 默认的分区器是HashPartitioner, 它的分区策略为将经map处理后得到的key的Hash值与reduce task的个数(NUM)取模, 模值相同的key将放在同一个分区中.
1.2.2 向内存buffer中写数据, 将打上标签的map输出的数据写入到内存buffer中, 内存buffer默认大小为100M. 此时每一个数据记录都由三部分组成:(1)分区号;(2)key;(3)value;
1.2.3 当内存buffer中写入的数据达到80M时, 此时会将这80M的内存封锁, 封锁后对内存中的数据进行聚合(Combiner), combiner完成后再根据分区号排序, 分区号排序完之后再按照key的大小排序(Sort). 此时这80M的数据中相同分区号的数据存放在一起, 并且分区内的数据是有序的.
1.2.4 溢写(Spill), 内存buffer达到80M内存时, 排序完成后对这80M数据溢写. 将数据写入磁盘, 形成一个磁盘小文件, 文件根据分区号划分并且内部有序. 每次内存buffer溢写都会产生这么一个小文件.
1.2.5 合并(Merge), 所有溢写完毕后, 会将磁盘小文件合并成一个大文件, 合并时先对数据进行聚合(Combiner), 然后再使用归并算法将各个小文件合并成一个根据分区号划分且内部有序的大文件. 每一个map task都会产生这么一个大文件. -
reduce task 线程
执行流程:
2.1 shuffle read阶段
1.1.1 读取map产生的大文件中对应分区的数据. 将分区数据写入内存中, 内存大小默认为1G, 当内存中写入的数据达到溢写比例时, 内存的溢写过程与map中buffer溢写几乎一样, 首先封锁数据, 然后对数据排序, 排序完成后将排好序的数据写入磁盘小文件中.
1.1.2 当map中对应分区的数据全部读取之后. reduce task会对所有的磁盘小文件进行归并算法合并, 合并成一个内部有序的磁盘大文件. 大文件中相同key值的数据为同一组数据.2.2 reduce阶段
1.2.1 遍历整个大文件, 对同一组的数据调用一次reduce方法, 将输出的<key, value>结果写入output文件中. 每个reduce task产生一个输出文件, 输出文件不再合并.
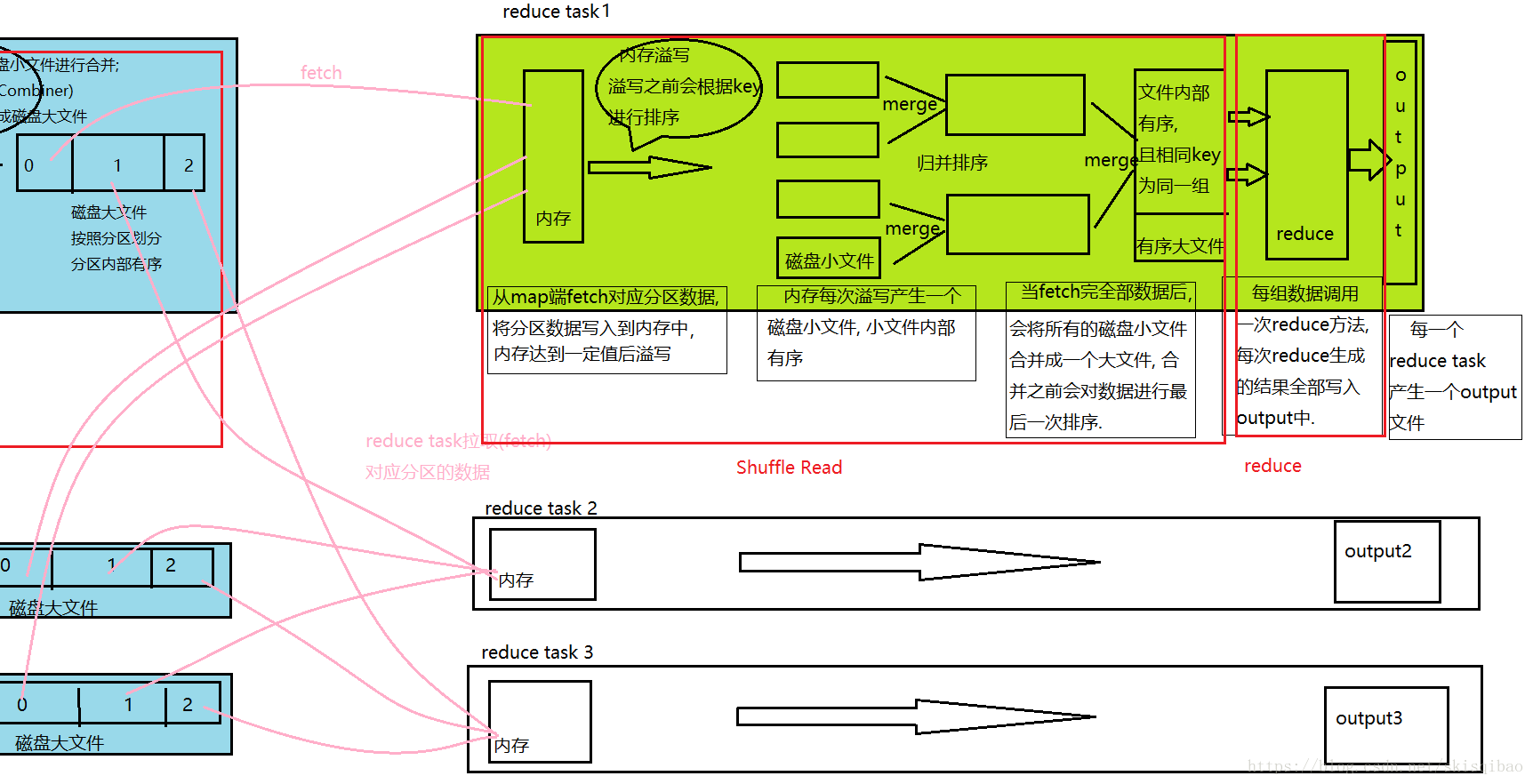
MapReduce整个过程流程图:
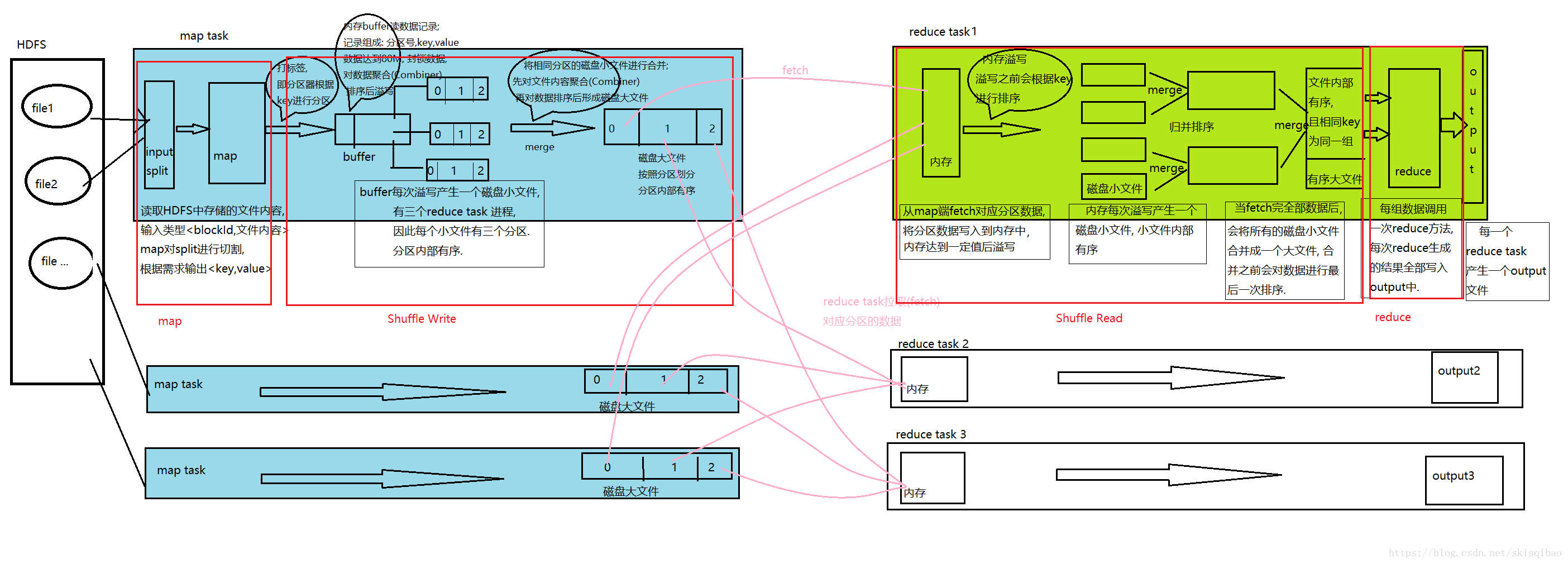
流程中可以看出, 一共进行了四次排序, 而这四此排序的最终目的都是在于提高最终分组的效率.
MR核心思想:“相同”的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算
MapReduce概述
MapReduce的定义
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
上文是官方对MapReduce的描述, 大意为MapReduce是一个软件框架, 用来写应用程序, 该程序以可靠, 容错的方式能够在大型集群(上千节点)上处理海量数据(多为TB级别).
换句话说, MapReduce是一个分布式计算框架, 它能将用户编写的程序和其默认组件整合为一个分布式处理程序, 并发运行在Hadoop集群上.
MapReduce的优缺点
-
优点
- 易于编程. 实现一个分布式程序只需简单地实现几个接口即可, 而且这个程序可以放到大量廉价的服务器(或PC机)上执行, 门槛低.
- 扩展性较好. 当计算资源得不到满足时, 可通过简单地增加服务器数量来提升计算性能.
- 高容错性. 既然MapReduce部署在廉价机上, 那么就要求它具备较高的容错性. 当一个节点挂掉后, 集群内部可以自动地将计算任务转移到其他服务器节点上执行. 不仅保证任务不会失败, 而且还不需要开发人员的参与.
- 适合海量数据的离线处理. MapReduce可实现有上千台服务器集群的并发工作, 从而提高计算能力.
-
缺点
- 不适合实时计算. 无法像MySQL一样, 在毫秒或秒级内返回结果.
- 不适合流式计算. MR自身设计决定它处理的数据集必须是静态的, 不能动态变化.
- 不适合有向图(DAG)计算. 当多个程序之间有相互依赖关系, 比如说前一个程序的输出要作为后一个程序的输入时, MR在处理时, 需要先将前一个程序的处理结果写入磁盘, 然后后一个程序再去磁盘读取结果之后才能处理, 从而造成大量磁盘IO, 导致性能低下.