MapReduce计算模型
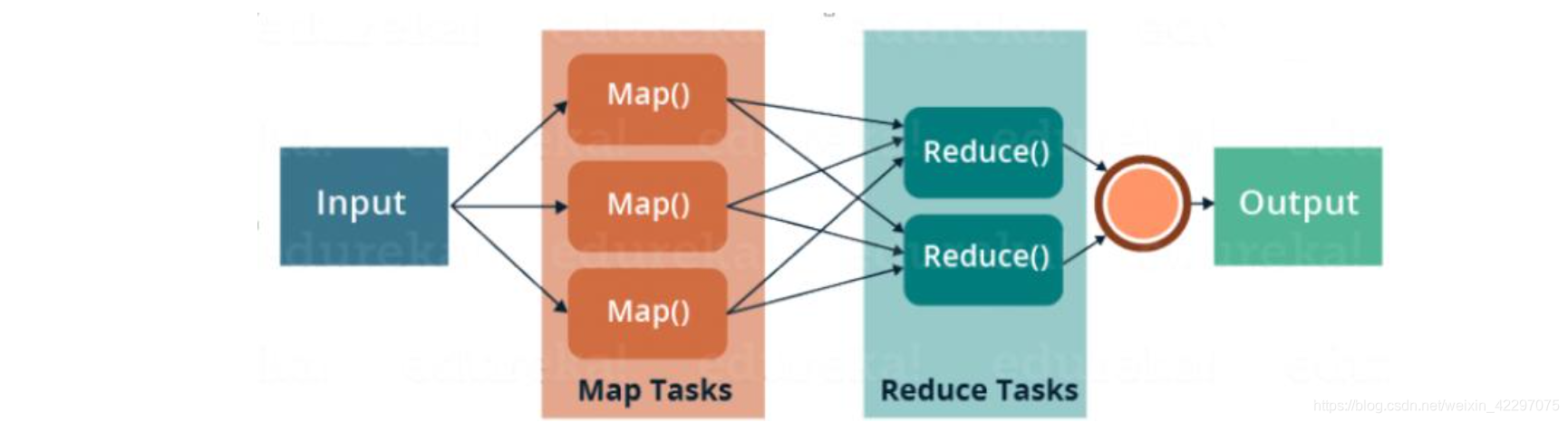
- 主要由Map和Reduce两部分组成。
- Reduce阶段在Map阶段执行结束之后执行。
- Map阶段的输出结果作为Reduce阶段的输入结果。
- Reduce阶段的输入结果对应于多个Map的输出结果。
- Reduce阶段计算最终结果并将结果输出。
MR示例
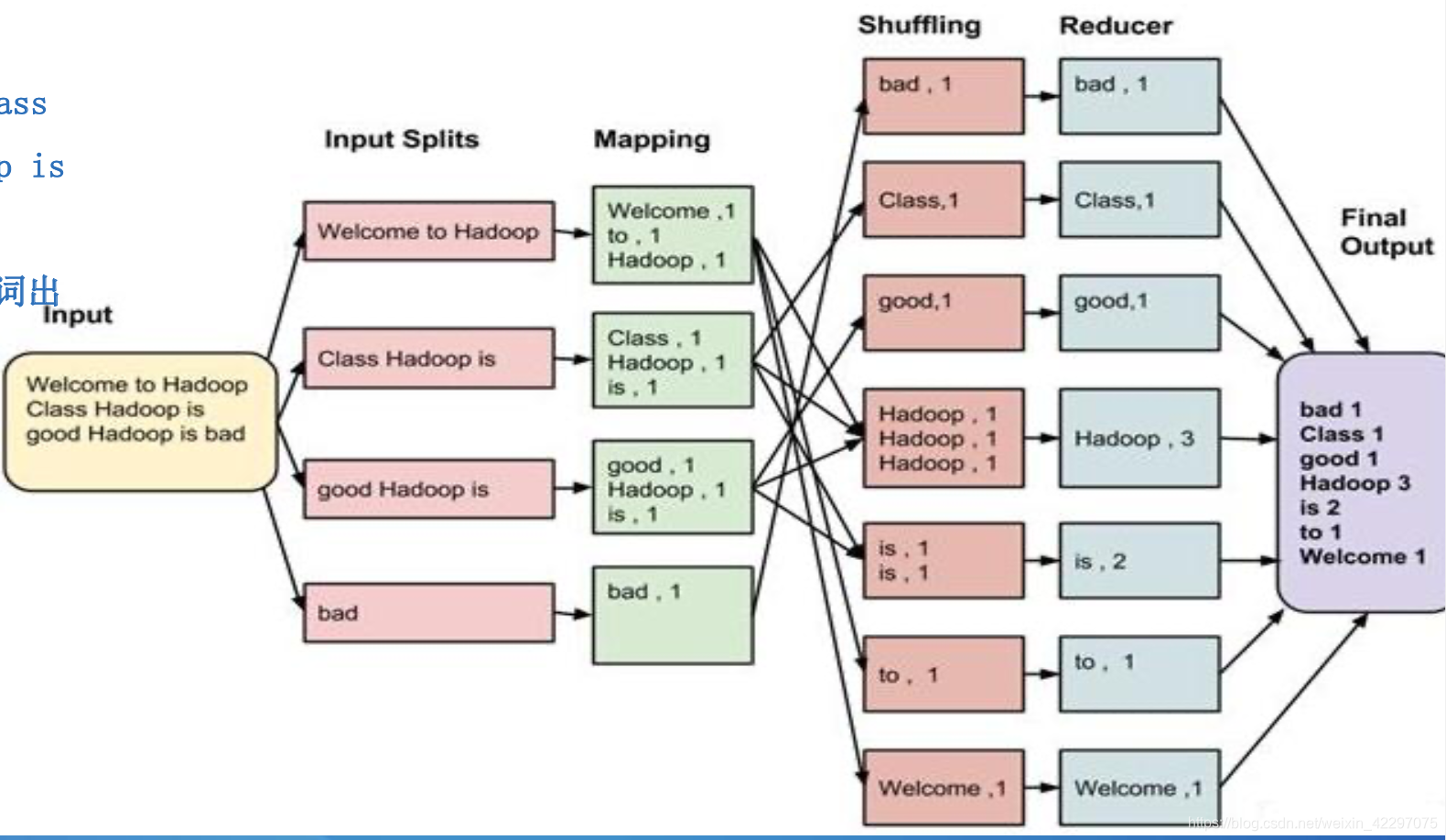
- 输入数据:一系列key/value对。
- 用户实现两个函数,map和reduce。
- Input Splits:对文件进行分片
- Map:将每个String split 成(word->1)
- shuffle:按key进行排序
- Reduce:将相同的word进行合并,value相加
- final output:将reduce 结果输出
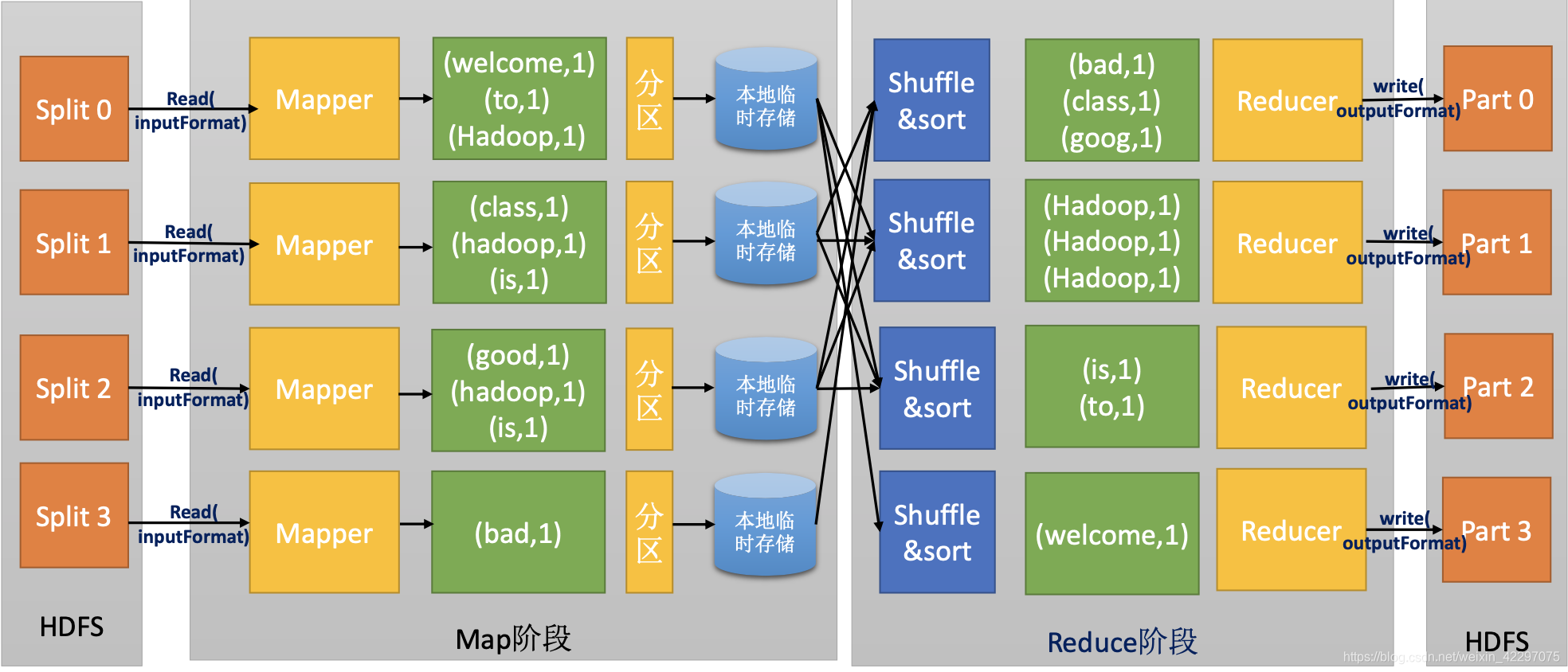
序列化&反序列化
序列化:是指将结构化的数据转化为字节流以便在网络上传输或写入到磁盘进行永久存 储的过程。
反序列化:是指将字节流转换为结构化对象的逆过程。
- 序列化常见应用场景:进程间通信和永久存储。
- Hadoop中,序列化要满足:
- 紧凑
- 快速
- 可扩展
- 支持互相操作
Hadoop中使用了自己的序列化格式Writable。它绝对紧凑、速度快、但不容易扩展。
MR常用数据类型
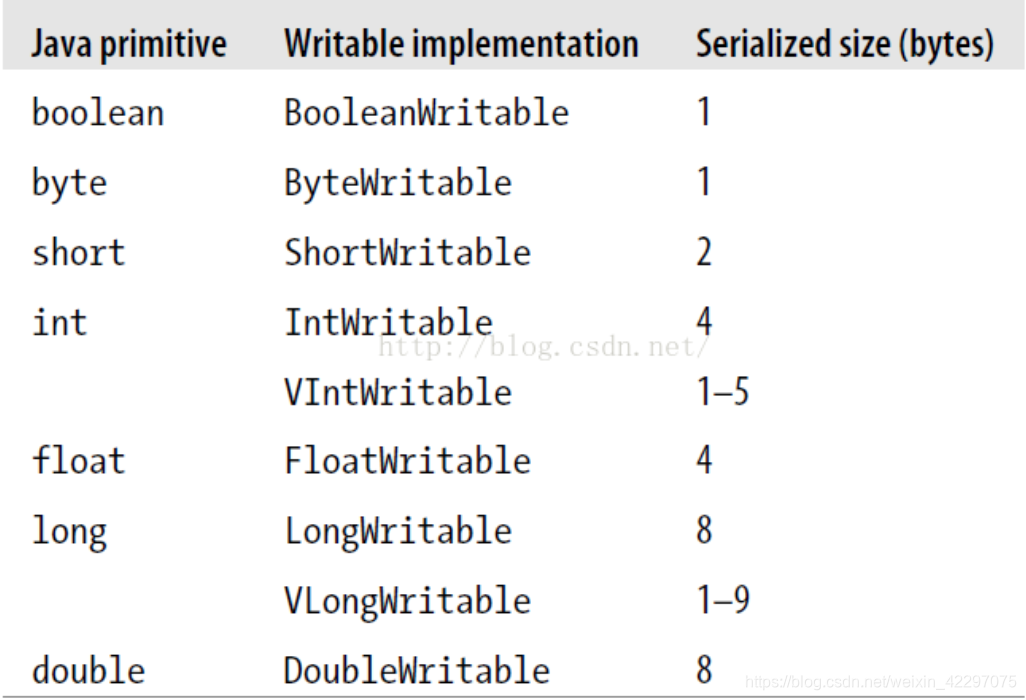
这些数据类型都实现了WritableComparable 接口,以便进行网络传输和文件存储,以及 进行大小比较
自定义数据类型
- 实现Writable接口,以便该数据能被序列化后完成网络 传输或文件输入/输出。
- 如果该数据需要作为主键key使用,或需要比较数值大 小时,则需要实现WritableComparable接口。
MR数据流
数据分片
- 等长的数据块,每个分片对应一个map任 务。
- 分片的大小很大程度影响了map执行的效率。建 议分片大小和hdfs数据块大小相同。
- “输入分片”并 非数据本身,而是逻辑上的分片长度和数据位置数组。
- Map任务结果并非保存在hdfs:临时数据。Map失败后 会在其他节点上启动map。
- Reduce的任务数量并非由输入数据大小指定,而事实 上是独立指定的。Map:reduce=n:m
Partition
map输出结果会根据reduce个数进行分区,默认是hash函数来分区,也可以自定义(partition函数)。
Shuffle
map和reduce之间的数据流。每个reduce的输入 来自于多个map任务的输出。在这个阶段,参数调优对job的运行时间有很大的影响。是奇迹发生的地方。
MapReduce编程模型-inputFormat*
InputFormat接口定义的方法就是如何读取文件和分割文件以提供分片给mapper。 TextInputFormat是InputFormat的默认实现类。

通过使用InputFormat,MapReduce可以做到:
- 验证作业的输入的正确性
- 把输入文件切分成多个逻辑块( InputSplit),并把它们分发给一个单独的MapperTask。
- 实例化一个能再每个InputSplit类上工作的RecordReader的实现,这个RecordReader从指定的InputSplit中正确读出一条一条的K-V对,这些K-V对将由我们写的Mapper方 法处理。
MapReduce编程模型-split和block
Block(块)
- HDFS中存储数据的最小单元。
- 默认大小是128MB。
Split(分片)
- Mapreduce中最小计算单元。
- 分片并非数据本身,而是记录一个分片的长度和分片数据位置信息的数组。
- 每个Split对应一个MapTask。
- 默认split数量和Block一一对应。
- Block和split的关系是任意的,可由用户控制
InputSplit大小
-
文件大小<=块容量(128M):每个文件对应一个InputSplit。
-
文件大小>块容量(存在多个块时):使用更为复杂的公式来计算InputSplit大小。
在块容量内,选最大的
-
InputSplitSize = Max(minSplitSize, Min(blockSize, maxSplitSize)) minSplitSize = mapreduce.input.fileinputformat.split.minsize blockSize = dfs.blocksize maxSplitSize=mapreduce.input.fileinputformat.split.maxsize minSplitSize默认值=1; maxSplitSize默认值=Long.MAX_VALUE;
-
-
分片数量=文件大小/分片大小(splitNum = totalsize / inputSplitSize)
-
得出以下结论:
- 如果想增加map数量:需要调小maxSplitSize的值。
- 如果想减少map数量:需要调大minSplitSize的值。
MR shuffle
确保每个reduce的输入都是按键排序的;系统制定排序过程为shuffle
map端
-
Map输出并非简单输出到磁盘,而是缓冲的方式写入内存并做预排序。当缓冲区满了则刷入磁盘。
-
Map缓冲区每刷一次磁盘,产生一个溢出文件。Map输出结束后,所有溢出文件会被合并为一个已分区且已排序的输出文件。
-
将压缩后的map结果输出可以减少磁盘写入量和网络传输量
reduce端
- 只要有一个map任务完成,reduce便开始复制其输出,reduce有少量的线程做复制。
- 复制完所有map输出后,reduce便会进入合并阶段。合并后的数据作为reduce输入。
压缩
-
地方
- 输入数据压缩
- map输出压缩
- reduce输出压缩
-
压缩方式
-
gzip:压缩后小于块大小
-
lzo:大文件
-
snappy:map输出数据比较大,数据衔接时候的压缩
-
bzip2:速度要求不高;较高压缩率;文本
-
MapReduce Combiner函数
- 集群上最紧俏的资源便是网络带宽,因此尽量减少map和reduce阶段的网络传输对MapReduce的性能提升是很重要的。 Hadoop为map任务的输出指定了一个合并函数(combiner),合并函数的输出作为reduce的输入。
- Combiner是的map的输出结果更加紧凑,同时减少了写磁盘和网络传输的数据量。
- Combiner又称为Local Reducer。
MR压缩
压缩可以发生在三个地方: 输入数据压缩、map输出压缩、reduce输出压缩。
压缩的优点:
- 减少网络I/O,
- 减少磁盘占用。
压缩的缺点:增加CPU计算量。
MR调优
- Reducer个数。直接影响map分区个数
- 输入:大文件优于小文件。某些maptask处理小文件影响负载均衡
- 减少网络传输:压缩、combiner
- 优化Map数量。
