这一段时间因为工作的原因,有了更多的时间,于是感兴趣学习了深度学习的相关内容,参考了大牛们编写MATLAB,C,Python等版本,自己重新捡起Python,小试牛刀,基本完成了autoencoder的主要功能,并通过小例子进行验证。
什么是深度学习?深度学习的目的又是什么?深度学习即通过多层模型,学习事物的特征,最后得到反映事物本质的真正特征,比如我们要看一段话,首先我们看到的是每一个字,然后不同的字组成不同的词,然后这些词组成一句话,最后这些句子组成了一段话,从字到段,这些特征从低级到高级,所表达的意思越来越清晰,深度学习类似,也就是从最简单的特征,映射到另外一个更具本质的特征,具体可以参考博客zouxy09的专栏
回归到正题,本次是要对autoencoder进行Python的实现,什么是autoencoder,UFLDL中给出了解释,这里我简单的说明,
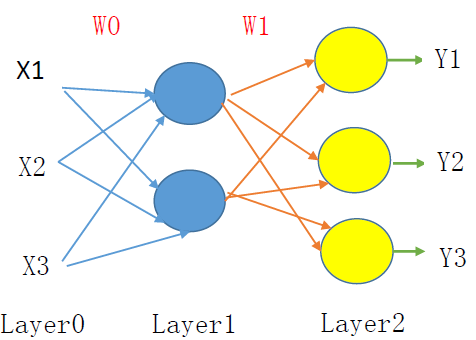
如上图所示,简单神经网络结构,因为autoencoder是非监督学习,为了得到W0,我们增加layer2层,其输出y1=x1,y2=x2,y3=x3,通过神经网络模型的训练机制,得到W0,然后layer0到layer1作为autoencoder的第一层结构a0,layer1的输出作为autoencoder下一层a1的输入,依次类推,得到autoencoder的多层模型结构。
因为autoencoder的本质还是分类,所以最后层选取一个分类器,或者还是原来的神经网络,并利用带标签的数据,进行整体模型结构的微调,本次Python实现的分类层依然是神经网络,因此微调的时候采取的back propagation算法。具体见下图所示
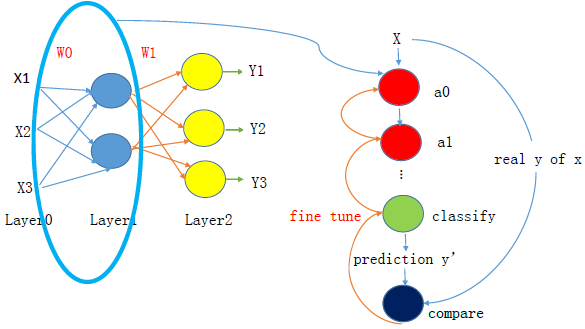
如果不能很好的理解,上述推荐的两个链接里面,有详细的解释,希望可以帮到大家对深度学习和autoencoder有一个初步的印象。
理论部分说明结束后,下一篇,就是纯粹的Python编程实现了。