论文链接:
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf
作者运用了一个披着深度学习外表的传统方法做这个问题,技术不提倡,思路、想法很天才。
主要思路:
1、想办法分离style features和content features;
2、怎么得到content features,作者偷懒直接取vgg19里面conv4_2的features,当作content features;
3、怎么得到style features,作者发挥天才的偷懒,认为style就是features之间的相关度,作者直接取vgg19里面conv1_1,conv2_1,conv3_1,conv4_1,conv5_1这5层的feature map来算风格相关度,作者又发现不同的layer对风格有影响,前面的风格细腻,后面的风格粗犷,又给这5个层的loss误差加了权重。
4、那么目标是什么了?就是new_image和content_image的内容接近,new_image和stytle_image的风格接近,
=
+
,首先要像,其次才是风格,所以
的比重要大。
pytorch实现:
计算content的Loss:
前面提到了作者偷懒直接取vgg19里面conv4_2的features,当作content features,那么只需要比较两个feature map的差别就行了。
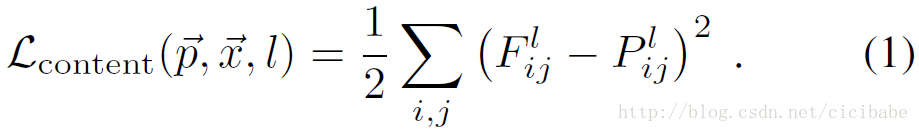
# the content loss
content_loss = torch.mean((target_features['conv4_2'] - content_features['conv4_2'])**2)
计算style 的Loss:
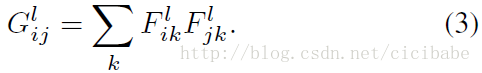
def gram_matrix(tensor):
""" Calculate the Gram Matrix of a given tensor
Gram Matrix: https://en.wikipedia.org/wiki/Gramian_matrix
"""
# get the batch_size, depth, height, and width of the Tensor
_, d, h, w = tensor.size()
# reshape so we're multiplying the features for each channel
tensor = tensor.view(d, h * w)
# calculate the gram matrix
gram = torch.mm(tensor, tensor.t())
return gram
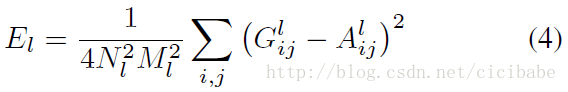
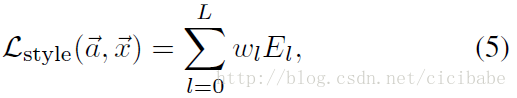
# weights for each style layer
# weighting earlier layers more will result in *larger* style artifacts
# notice we are excluding `conv4_2` our content representation
style_weights = {'conv1_1': 1.,
'conv2_1': 0.75,
'conv3_1': 0.2,
'conv4_1': 0.2,
'conv5_1': 0.2}
# get style features only once before training
style_features = get_features(style, vgg)
# calculate the gram matrices for each layer of our style representation
style_grams = {layer: gram_matrix(style_features[layer]) for layer in style_features}
for layer in style_weights:
# get the "target" style representation for the layer
target_feature = target_features[layer]
target_gram = gram_matrix(target_feature)
_, d, h, w = target_feature.shape
# get the "style" style representation
style_gram = style_grams[layer]
# the style loss for one layer, weighted appropriately
layer_style_loss = style_weights[layer] * torch.mean((target_gram - style_gram)**2)
# add to the style loss
style_loss += layer_style_loss / (d * h * w)
计算total的Loss:
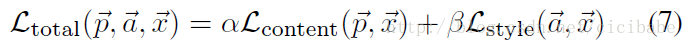
content_weight = 1 # alpha
style_weight = 1e6 # beta
# calculate the *total* loss
total_loss = content_weight * content_loss + style_weight * style_loss
训练过程:
有人可能问VGG参数固定住了,需要的参数是什么了,参数就是新图啊?通过上述loss调整图像的像素值,这个和我们一般了解到的有点不一样。
新图就是在原图的基础上慢慢变化,f复制原图并设置新图为trainable的:
# create a third "target" image and prep it for change
# it is a good idea to start of with the target as a copy of our *content* image
# then iteratively change its style
target = content.clone().requires_grad_(True).to(device)
训练大概代码如下:
# for displaying the target image, intermittently
show_every = 400
# iteration hyperparameters
optimizer = optim.Adam([target], lr=0.003)
steps = 2000 # decide how many iterations to update your image (5000)
for ii in range(1, steps+1):
# get the features from your target image
target_features = get_features(target, vgg)
# the content loss
content_loss = torch.mean((target_features['conv4_2'] - content_features['conv4_2'])**2)
# the style loss
# initialize the style loss to 0
style_loss = 0
# then add to it for each layer's gram matrix loss
for layer in style_weights:
# get the "target" style representation for the layer
target_feature = target_features[layer]
target_gram = gram_matrix(target_feature)
_, d, h, w = target_feature.shape
# get the "style" style representation
style_gram = style_grams[layer]
# the style loss for one layer, weighted appropriately
layer_style_loss = style_weights[layer] * torch.mean((target_gram - style_gram)**2)
# add to the style loss
style_loss += layer_style_loss / (d * h * w)
# calculate the *total* loss
total_loss = content_weight * content_loss + style_weight * style_loss
# update your target image
optimizer.zero_grad()
total_loss.backward()
optimizer.step()