
大数据(BigData)
-
什么是大数据?
数据量很大的数据,量级TB级或者日均增长GB级 -
大数据的特点 (4V)?
Volume 数据量大
Variety 数据种类多
结构化数据:
半结构化数据: xml json
无结构化数据: 音频 视频 图像
Velocity 快速处理
相对快
value 在大量没有价值的数据中,抽取出数据的价值 -
大数据的来源?
本系统自己产生的数据(大型公司) 开发日志 Nginx日志
爬虫(免费)
行业大数据(交通,医疗,政府,金融,电信) -
大数据的类型?
目前处理的大数据类型,都是文本数据 -
大数据面临的问题?[重点]
-
如何存储
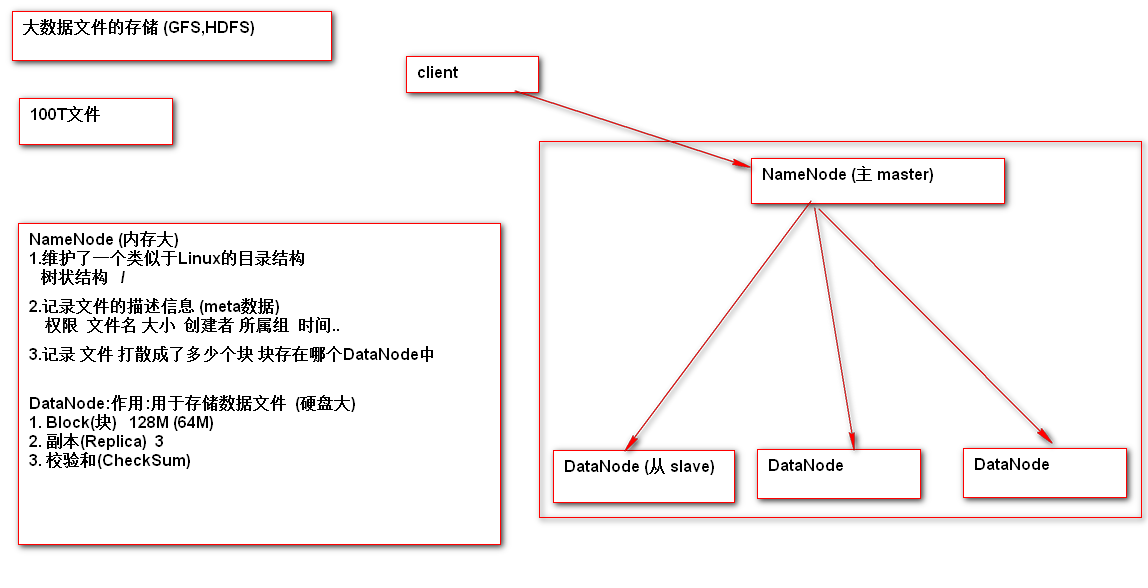
-
计算(CPU 内存 = 资源(算力))
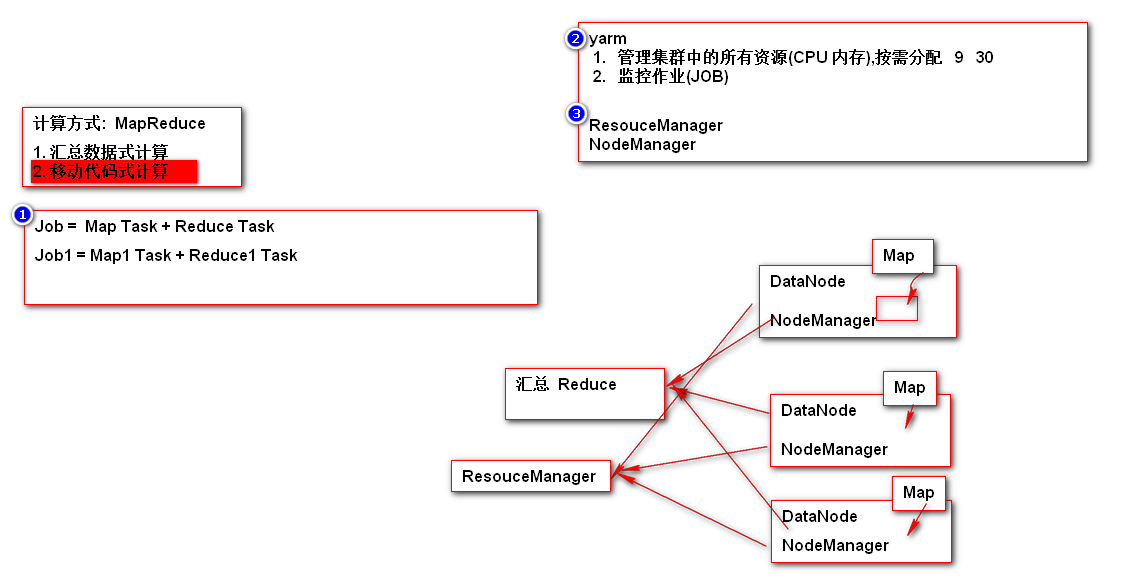
大数据技术的发展演变
-
2003年Google 发布3篇论文,解决大数据问题
1. GFS Google File System
2. MapReduce
3. BigTable -
Hadoop是基于Google3篇论文的思想,应用java编程语言实现
1. Hadoop之父 Doug Cutting
2. HDFS (Hadoop Distributed File System) 对应 GFS
3. MapReduce 对应 MapReduce
4. HBase 对应 BigTable -
Hadoop的发行版本
1. Apache组织提供的开源 免费版 [重点]
2. Cloudera (CDH) Hadoop之父 4000美元 1个节点 [重点]
3. Hortonworks 12000美元 10个节点
Hadoop的环境搭建
-
Notepad++远程操作linux下的远程文件
NppFTP插件
-
环境基础
1. linux64位
2. JDK 1.7+-
网络的基本设置
-
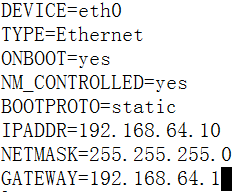
修改网卡
vi /etc/sysconfig/nework-script/ifcfg-eth0
-
-
-
从新启动网卡
service network start|stop|restart # 设置网卡 -
关闭防火墙
# 临时关闭防火墙
service iptables stop
# 永久关闭防火墙
chkconfig iptables off -
修改主机名
vi /etc/sysconfig/network -
主机名映射
windows
C:\Windows\System32\drivers\etc\hosts
192.168.64.10 hadoop
linux
vi /etc/hosts
-
关闭Selinux
Selinux 是红帽子的安全套件 RedHat = CentOS
vi /etc/selinux/config
SELINUX=disabled -
规范Linux中软件的安装目录
#原始安装文件
/opt/models
#安装目录
1. 如果软件有默认安装目录则默认安装 /usr
2. 如果需要指定安装目录 统一放置在 /opt/install文件夹 -
安装JDK
#rpm
rpm -ivh jdkxxxxx
vi .bash_profile
JAVA_HOME=/usr/java/jdk1.7.0_71
CLASSPATH=.
PATH=$JAVA_HOME/bin:$PATH:$HOME/bin
export JAVA_HOME
export CLASSPATH
export PATH
source .bash_profile
9.Hadoop安装
#hadoop的伪分布式环境
1. 上传hadoop2.5.2压缩包 /opt/models
2. 解压缩 /opt/install
3. 配置文件配置 etc/hadoop
1. hadoop-env.sh export JAVA_HOME=/usr/java/jdk1.7.0_71 2. core-site.xml <property> <name>fs.default.name</name> <value>hdfs://hadoop1.baizhiedu.com:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/install/hadoop-2.5.2/data/tmp</value> </property> 3. hdfs-site.xml <property> <name>dfs.replication</name> <value>1</value> </property> 4. yarn-site.xml <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> 5. mapred-site.xml <!--改名 mapred-site.xml.template 该名称 mapred-site.xml--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
4. namenode的格式化
相对于hadoop安装路径 /opt/install/hadoop-2.5.2
bin/hdfs namenode -format
5. 启动hadoop的后台进程
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
6. 验证效果
ps -ef | grep java
jps #底层 jdk提供 javac java javadoc
http://hadoop:50070-
Hadoop中HDFS的基本使用
1.shell命令
bin/hdfs dfs -xxx [新版]
bin/hadoop fs -xxx [旧版]
#查看hdfs上某一个目录中的文件
bin/hdfs dfs -ls /
#hdfs中创建目录
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir -p /user
#上传文件 linux ---> hdfs /root/hdfs/data文件 上传 hdfs
bin/hdfs dfs -put /root/hdfs/data /xiaohei/xiaojr
#查看文件内容
bin/hdfs dfs -text /xiaohei/xiaojr/data
bin/hdfs dfs -cat /xiaohei/xiaojr/data
#下载文件
bin/hdfs dfs -get /xiaohei/xiaojr/data /root
#删除 bin/hdfs dfs -rm -r xxxx
bin/hdfs dfs -rm /xiaohei/xiaojr/data
bin/hdfs dfs -rm /xiaohei
#复制,移动
bin/hdfs dfs -cp
bin/hdfs dfs -mv
Java Client访问
#HDFS Client
Configuration
FileSytem
IOUtils
maven
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.5.2</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.5.2</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.5.2</version> </dependency>
java
## HDFS默认只能进行读操作,如果进行写操作则会有权限的控制
hdfs-site.xml 额外的配置
<property> <name>dfs.permissions.enabled</name> <value>false</value> </property>
/*从远端HDFS中下载文件到本地*/
@Test public void test1() throws Exception{ Configuration configuration = new Configuration(); configuration.set("fs.default.name","hdfs://hadoop:8020"); FileSystem fileSystem = FileSystem.get(configuration); FSDataInputStream inputStream = fileSystem.open(new Path("/test/data")); IOUtils.copyBytes(inputStream,System.out,1024,true); } /*本地文件中*/ @Test public void test2() throws Exception{ Configuration configuration = new Configuration(); configuration.set("fs.default.name","hdfs://hadoop:8020"); FileSystem fileSystem = FileSystem.get(configuration); FSDataInputStream inputStream = fileSystem.open(new Path("/test/data")); FileOutputStream outputStream = new FileOutputStream("d:\\suns.txt"); IOUtils.copyBytes(inputStream,outputStream,1024,true); } /*上传文件*/ @Test public void test3()throws Exception { Configuration configuration = new Configuration(); configuration.set("fs.default.name","hdfs://hadoop:8020"); FileSystem fileSystem = FileSystem.get(configuration); FSDataOutputStream outputStream = fileSystem.create(new Path("/test/test1")); FileInputStream inputStream = new FileInputStream("d:\\suns.txt"); IOUtils.copyBytes(inputStream,outputStream,1024,true); } @Test public void test4()throws Exception { Configuration configuration = new Configuration(); configuration.set("fs.default.name","hdfs://hadoop:8020"); FileSystem fileSystem = FileSystem.get(configuration); //fileSystem.delete(); //fileSystem.mkdirs(new Path("/xiaojr/xiaowb")); // RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fileSystem.listFiles(new Path("/test"), true); // // while(locatedFileStatusRemoteIterator.hasNext()){ // LocatedFileStatus next = locatedFileStatusRemoteIterator.next(); // System.out.println(next); // } }
练手:用户上传本地文件到hdfs,如果文件不存在,则上传,如果文件已经存在则在控制台打印存在,或者jsp页面alert
思路:页面选择提交文件,controller接收multifile文件,MD5得到文件的唯一加密码,并将加密码存入redis,key为加密码,值为文件名
上传至hdfs前,判断redis是否有key,有则不上传,没有则调api上传即可
难点:maven集成redis,MD5的加密
代码:https://github.com/lhcmmd/hadoop/tree/master/hadoop-day1