Hadoop是Apache的一个开源框架,用于分布式存储以及在商用硬件上运行的计算机集群上的大数据的分布式处理。 Hadoop将数据存储在Hadoop分布式文件系统(HDFS)中,并使用MapReduce完成这些数据的处理。 YARN提供用于在Hadoop集群中请求和分配资源的API。
Apache Hadoop框架由以下模块组成:
- Hadoop Common
- Hadoop Distributed File System (HDFS)
- YARN
- MapReduce
Pre: Hadoop的几种运行环境
- 单机模式
单机模式又叫非分布式模式,常用于本地调试。这种模式在一台单机上运行,没有DFS(分布式文件系统)。 - 完全分布式模式
这种模式是真正的分布式模式,由≥3个的实体机或者虚拟机组成,若需要在虚拟机中创建完全分布式环境,至少需要一个主设备Master与两个从设备Slave1、Slave2。 - 伪分布式模式
顾名思义,伪分布式模式是在模拟完全分布式模式,这种模式也是在单机上运行,但是会用不同的Java进程模拟分布式运行中的NameNode,DataNode,JobTracker,TaskTracker等结点。
本文介绍了如何在Ubuntu 16.04LTS下搭建Hadoop伪分布式环境。
** 注意,以下所有终端命令片段均需要分步执行。
一:准备
-
创建hadoop用户并增加su权限
$ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户 $ sudo passwd hadoop #设置密码 $ sudo adduser hadoop sudo #为hadoop用户增加su权限 -
将当前会话切换到hadoop用户
切换后执行:$ sudo apt-get update #更新源 -
安装SSH并取消密码登陆
$ sudo apt-get install openssh-server #安装openssh-server $ cd ~/.ssh/ #如果报错,执行ssh localhost $ ssh-keygen -t rsa #生成SSH密钥生成密钥的过程中需要点3次回车以确保为空密码
出现下图,则密钥生成成功。
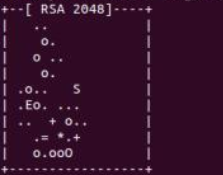
继续执行以下命令:$ cat ./id_rsa.pub >> ./authorized_keys #加入授权 $ ssh localhost #登陆localhost此时登陆localhost应该是不需要密码的,如果需要密码,请重复上一步。
出现类似下图的输出则说明登陆成功
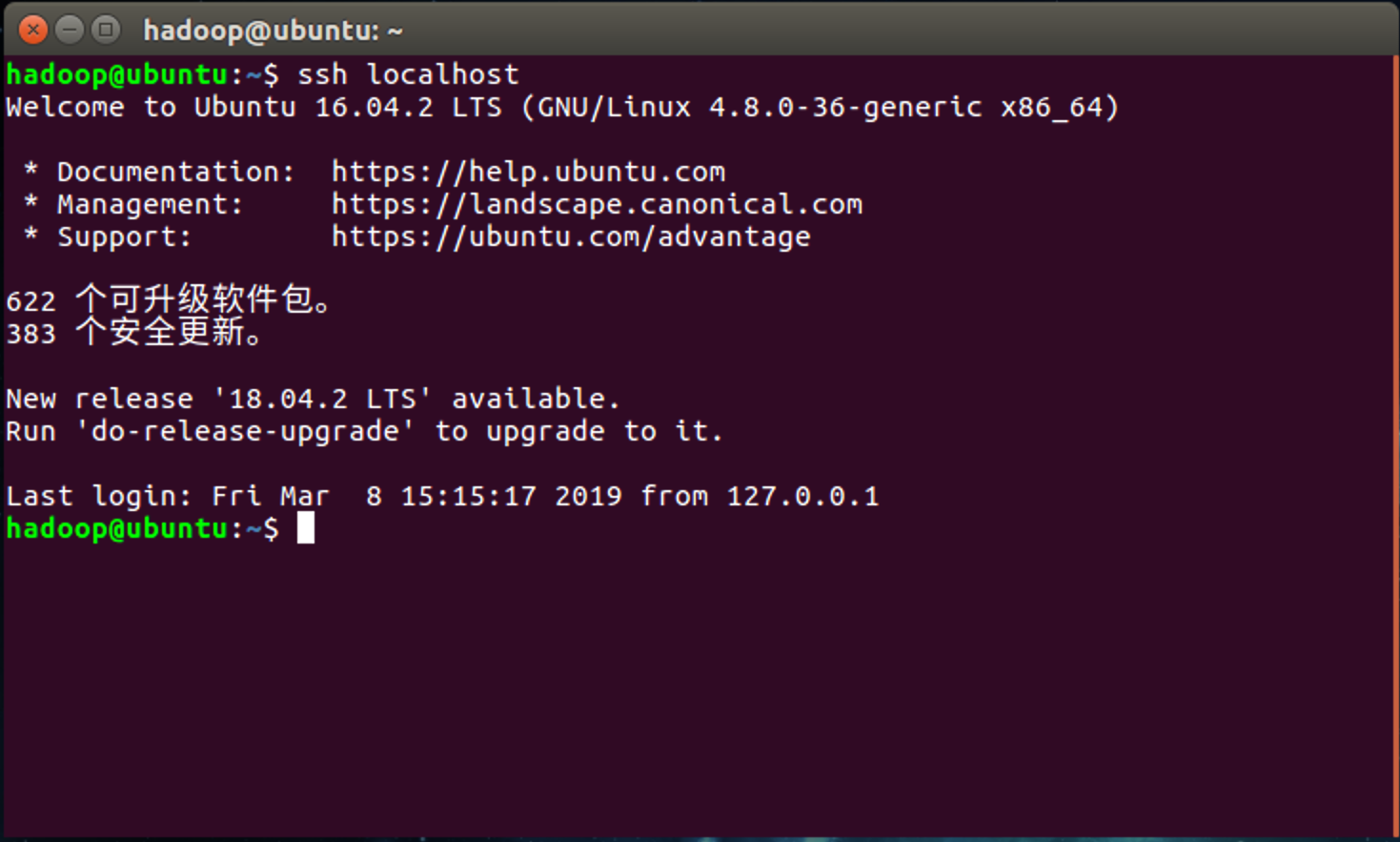
二:安装Java SE
在Oracle官网下载合适的jdk:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
以jdk-8u201-linux-x64.tar.gz为例。
下载完成后执行以下命令:
$ sudo mkdir /usr/lib/jvm #在库中创建jvm文件夹
$ cd ./下载 #进入下载文件夹(注意系统语言的区别,此文件夹是刚下载的jdk包目录)
$ sudo tar zxvf jdk-8u201-linux-x64.tar.gz -C /usr/lib/jvm #/ 解压到/usr/lib/jvm目录下
$ cd /usr/lib/jvm #进入该目录
$ sudo mv jdk1.8.0_201 java #重命名为java
稍后测试java是否安装成功
三:安装hadoop-2.77
1.分步执行以下命令,安装hadoop
$ cd ~ #进入home
$ wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz #下载hadoop-2.77
#下载需要的时间比较长,耐心等待完成后再进行下一步
$ sudo tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local #解压到/usr/local目录下
$ cd /usr/local #进入local
$ sudo mv hadoop-2.7.7 hadoop #重命名为hadoop
$ sudo chown -R hadoop ./hadoop #修改文件权限
- 配置hadoop的环境变量
$ cd ~
$ sudo gedit ~/.bashrc #打开环境变量文件
将下列代码追加到文件尾,然后Ctrl+S保存:
#JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
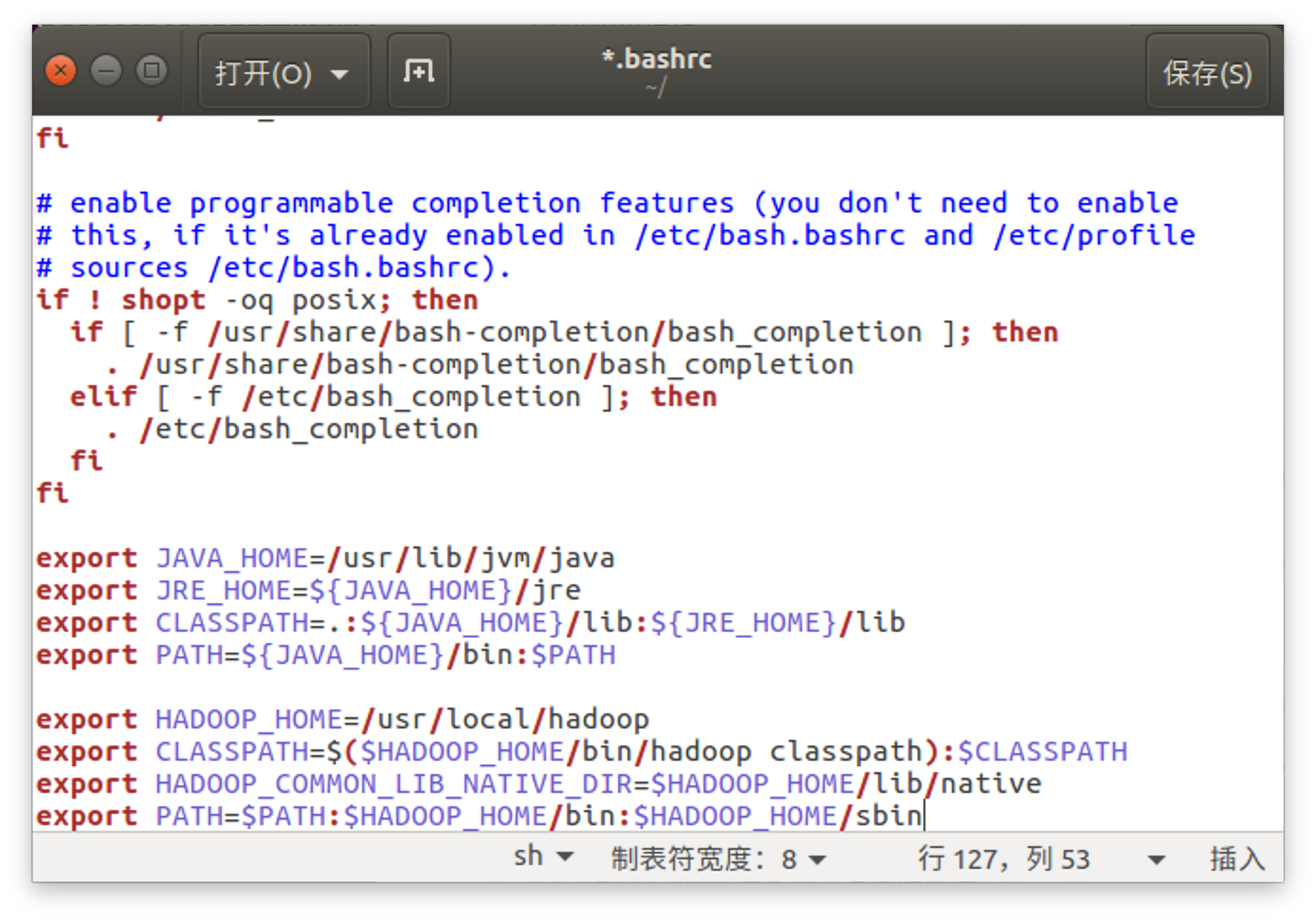
- 执行source ~ /.bashrc刷新环境变量配置。
$ source ~ /.bashrc #刷新环境变量配置
- 检查Java和Hadoop的版本,查看是否安装成功。
$ java -version #查看Java版本
$ hadoop version #查看hadoop版本
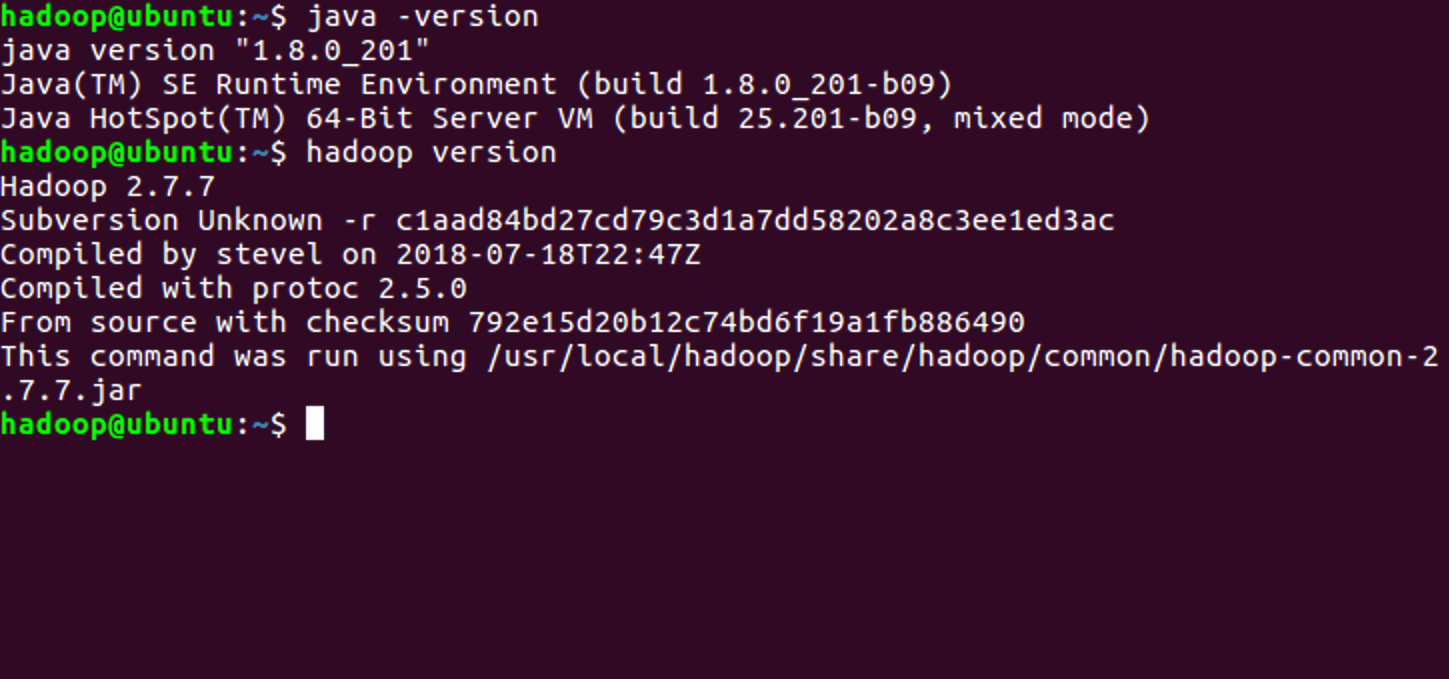
出现版本号则说明安装成功。
四:伪分布式模式配置
- 执行以下命令:
$ cd /usr/local/hadoop/etc/hadoop #进入hadoop安装目录
$ ls #列出目录文件,如下图

Hadoop的配置文件:
hadoop-env.sh 配置JAVA_HOME
core-site.xml 配置HDFS节点名称和地址
hdfs-site.xml 配置HDFS存储目录,复制数量
mapred-site.xml 配置mapreduce的jobtracker地址
- 执行以下命令
$ sudo gedit hadoop-env.sh
将export JAVA_HOME=/usr/lib/jvm/java添加到hadoop-env.sh文件,并保存。
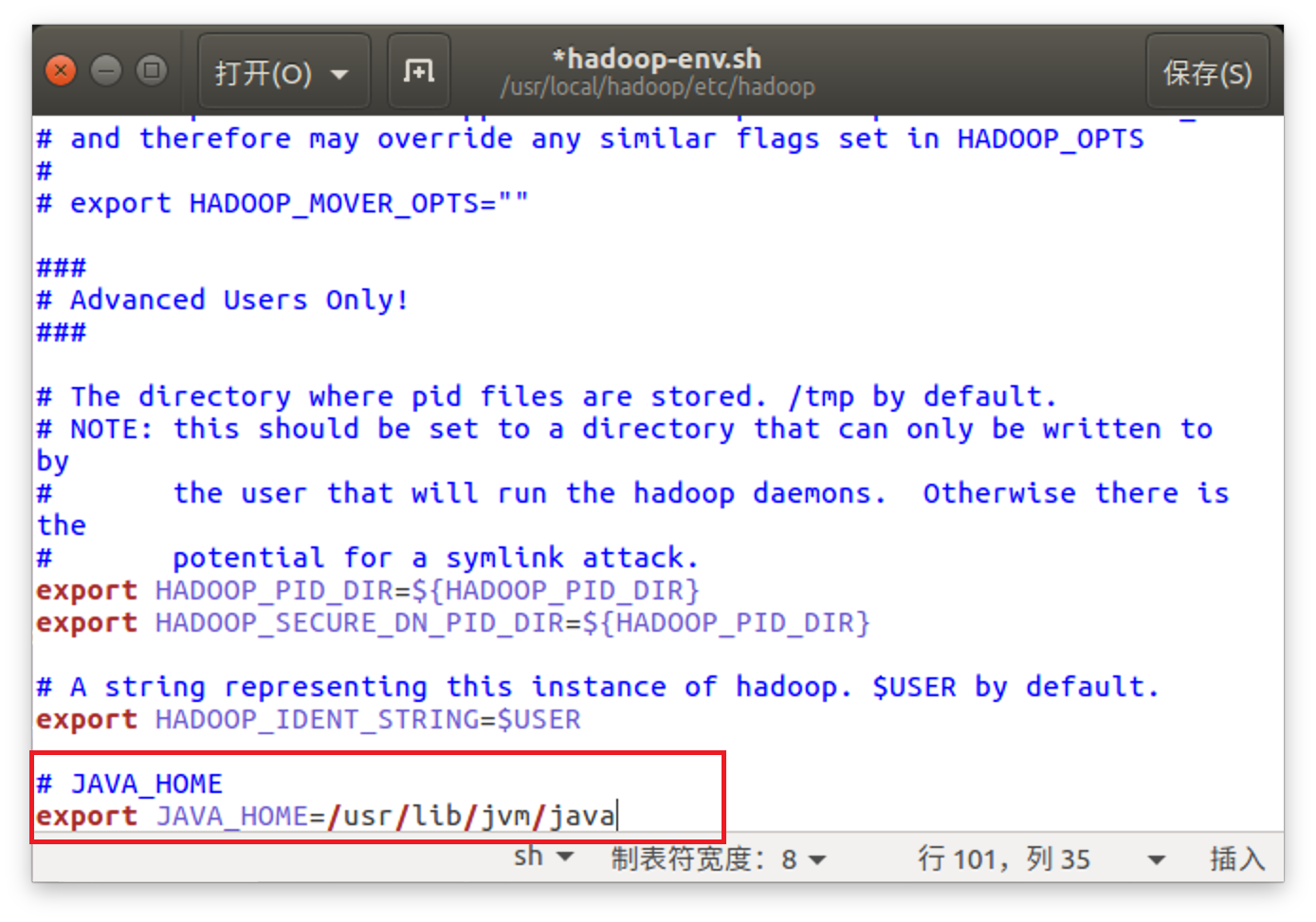
- 修改
core-site.xml文件
$ sudo gedit core-site.xml
写入以下内容并保存
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- 修改
hdfs-site.xml文件
$ sudo gedit hdfs-site.xml
写入以下内容并保存
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(可参考官方教程),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
- 格式化NameNode
$ cd ~
$ hadoop namenode -format
- 启动NameNode&DataNode
$ /usr/local/hadoop/sbin/start-dfs.sh #启动进程,需要输入'yes'
$ jps #查看启动结果
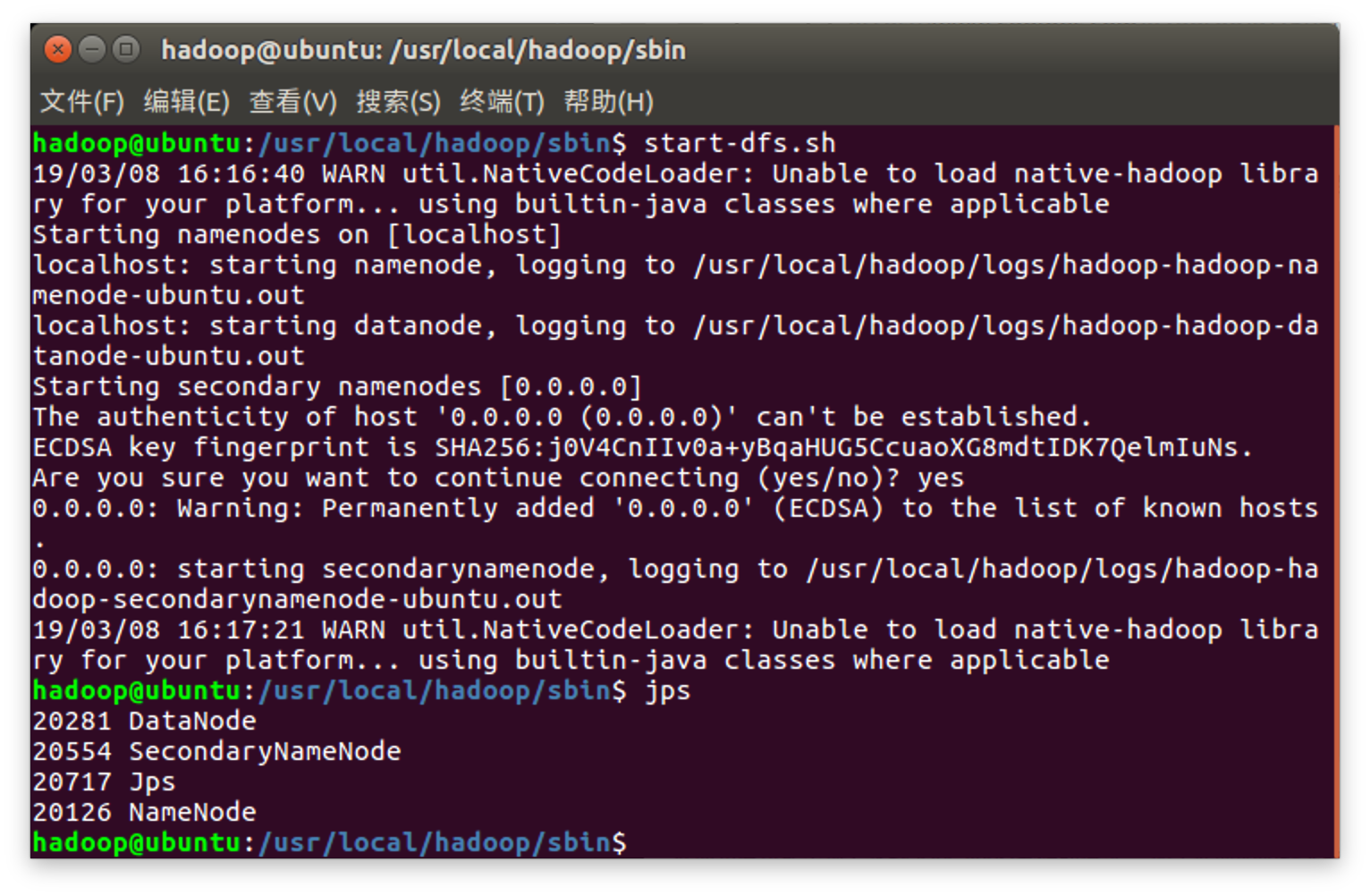
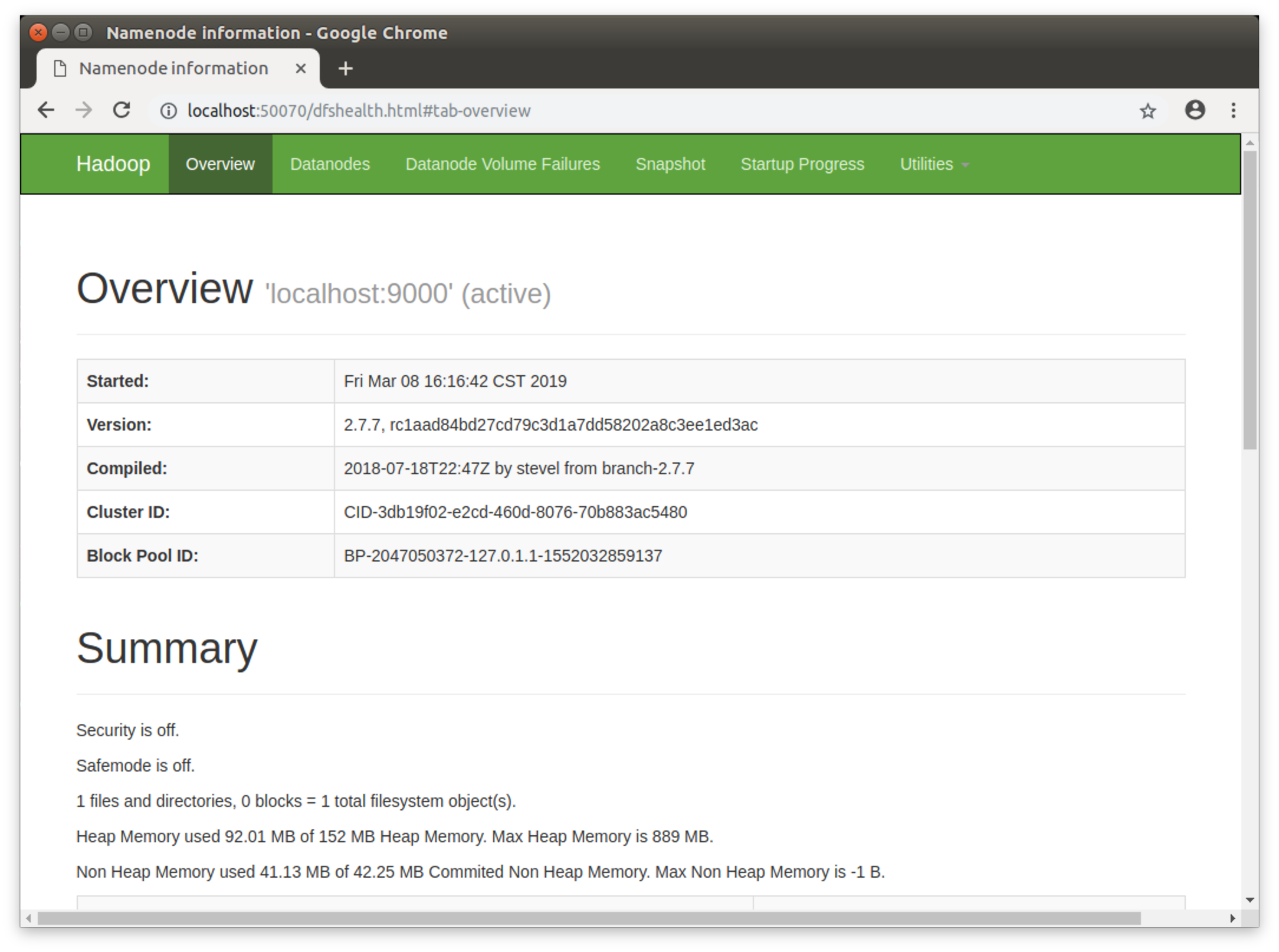
出现NameNode,DataNodeSecondary,DataNode,Jps进程则启动成功,此时,可以访问http://localhost:50070查看NameNode和DataNode信息和HDFS中存储的文件信息。
以上为Ubuntu 16.04 LTS 下搭建Hadoop伪分布式环境教程,如果教程中存在错误或疑问,请在评论区留言。