大数据环境部署 第二章——Hadoop 伪分布式环境搭建
一、准备阶段
- 1、Hadoop-x.x.x.tar.gz (版本随意 但是这里推荐使用2.7.x版本,毕竟现在这是稳定的版本,后面对一些其他的组件之间的依赖也更好一些)
官网的下载地址 https://hadoop.apache.org/old/releases.html
点击 下载二进制文件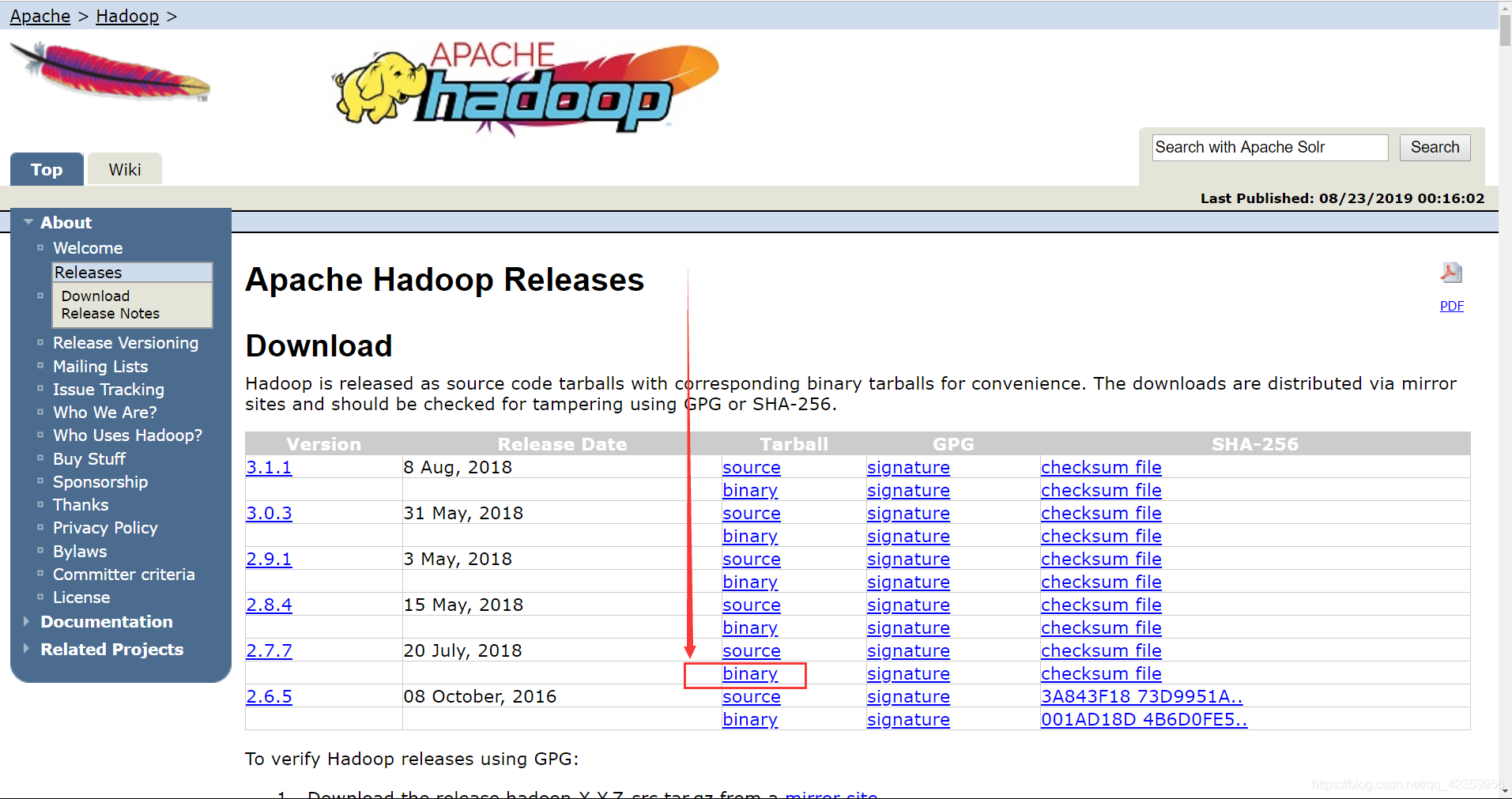

选择清华源进行下载,这样下载速度会快一些。 - 2、jdk-xxxxx-linux-x64.tar.gz (Java JDK文件)
官网下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
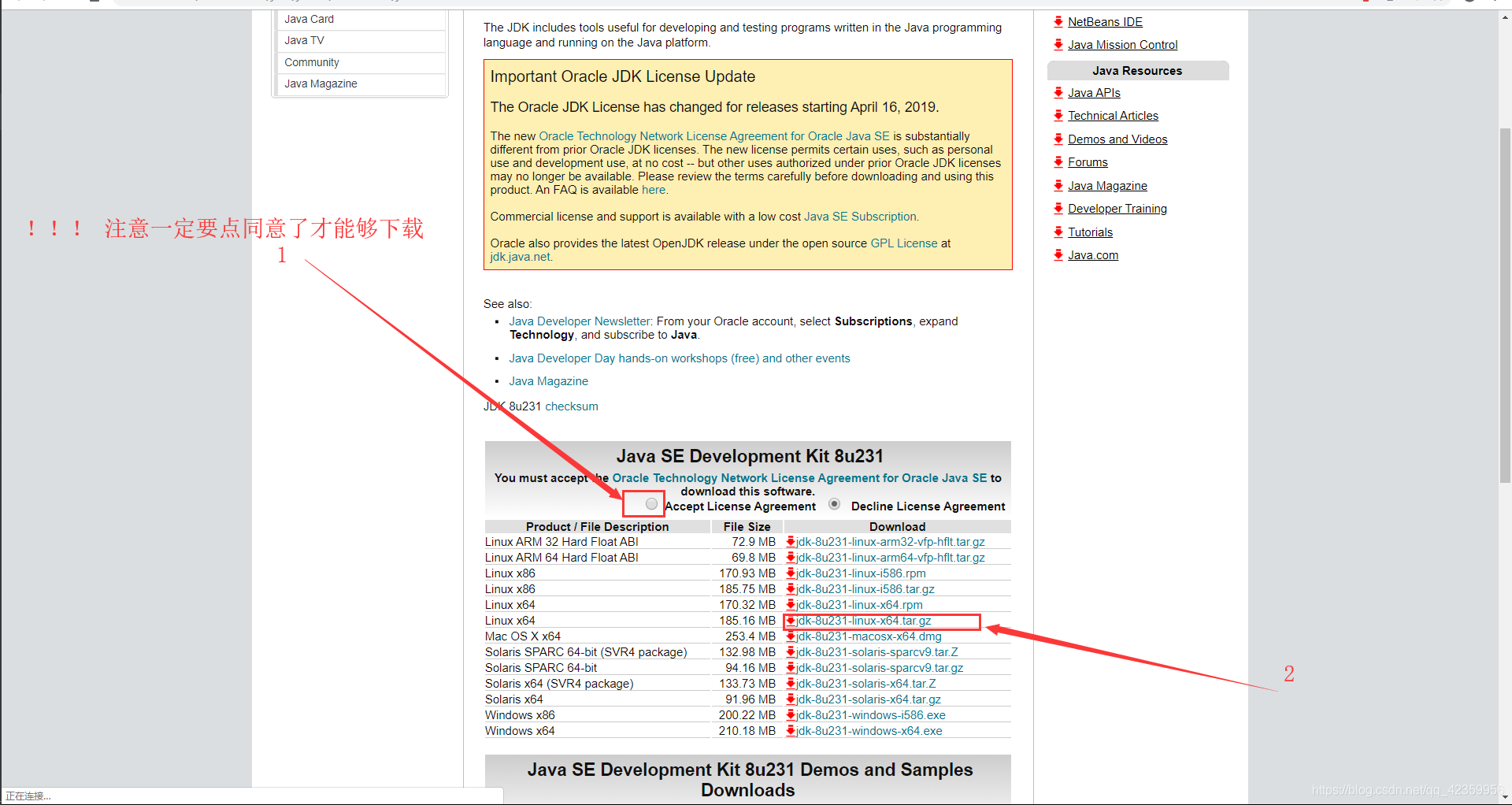
二、文件上传阶段
前言:默认读者已经安装好了以下两个工具:
- 1、使用Xshell工具连接Ubuntu虚拟机
(1)第一步打开Vmvare中的Ubuntu虚拟机
(2)使用 ifconfig 命令查看虚拟机的IP地址
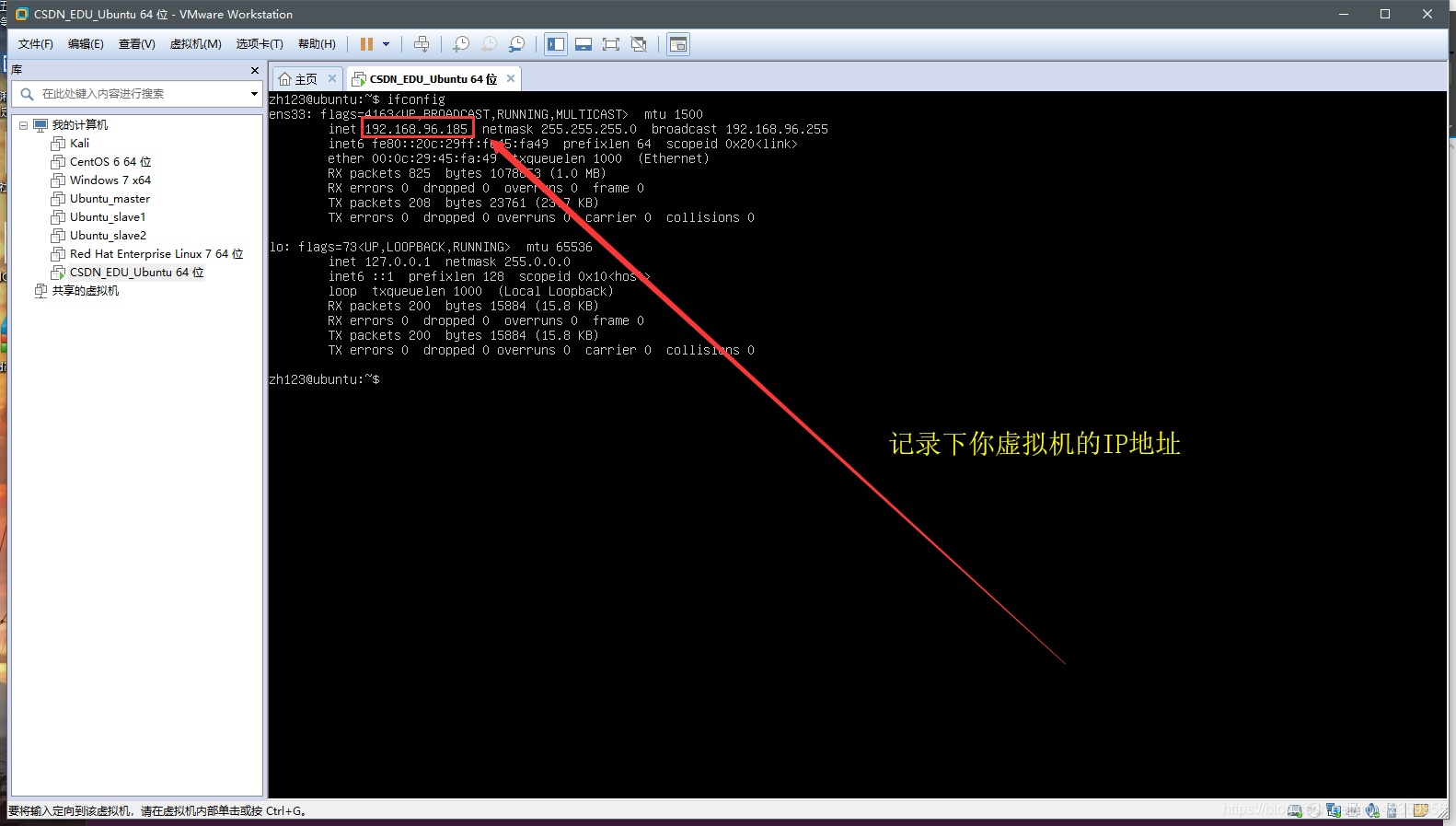
看图可以知道笔者这台虚拟机的ip地址即是192.168.96.185 先把这个IP记录下来
(3)打开Xshell应用程序,点击新建连接
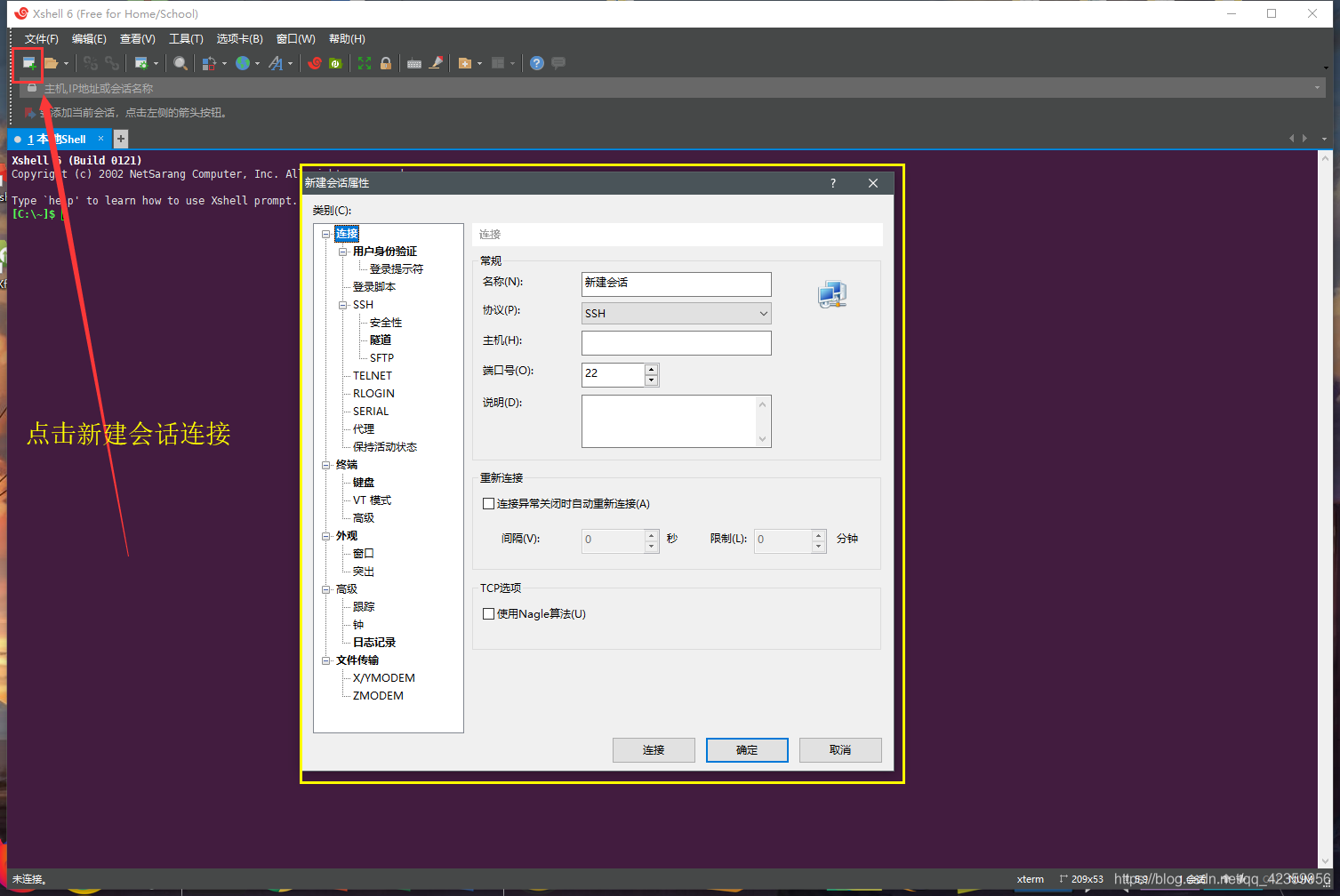
(4)在主机处填入你刚才记录的IP地址
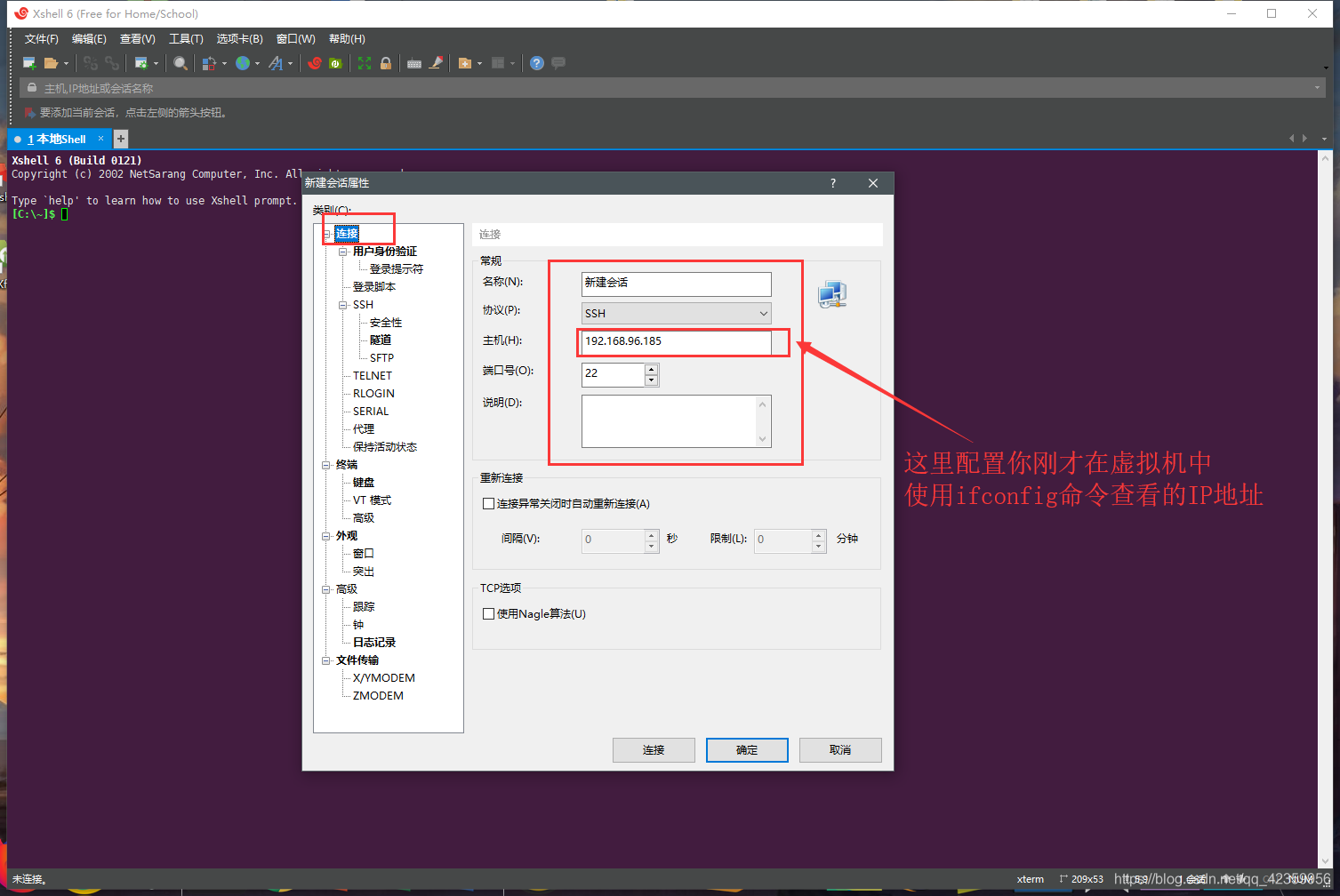
(5)点击用户身份验证,配置虚拟登录虚拟机的用户名和密码
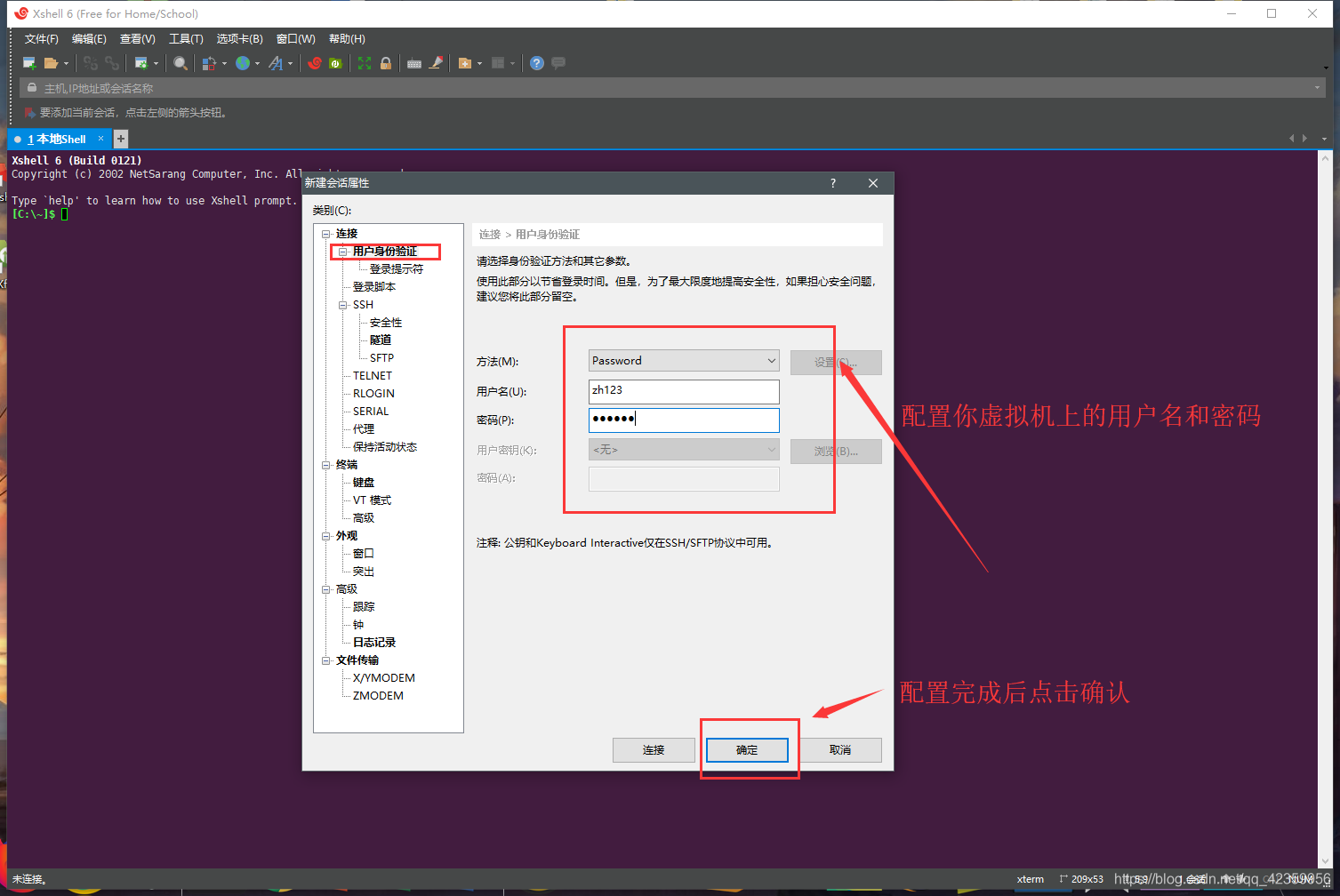
(6)点击打开连接,选择到刚才的新建的连接,然后进行连接虚拟机
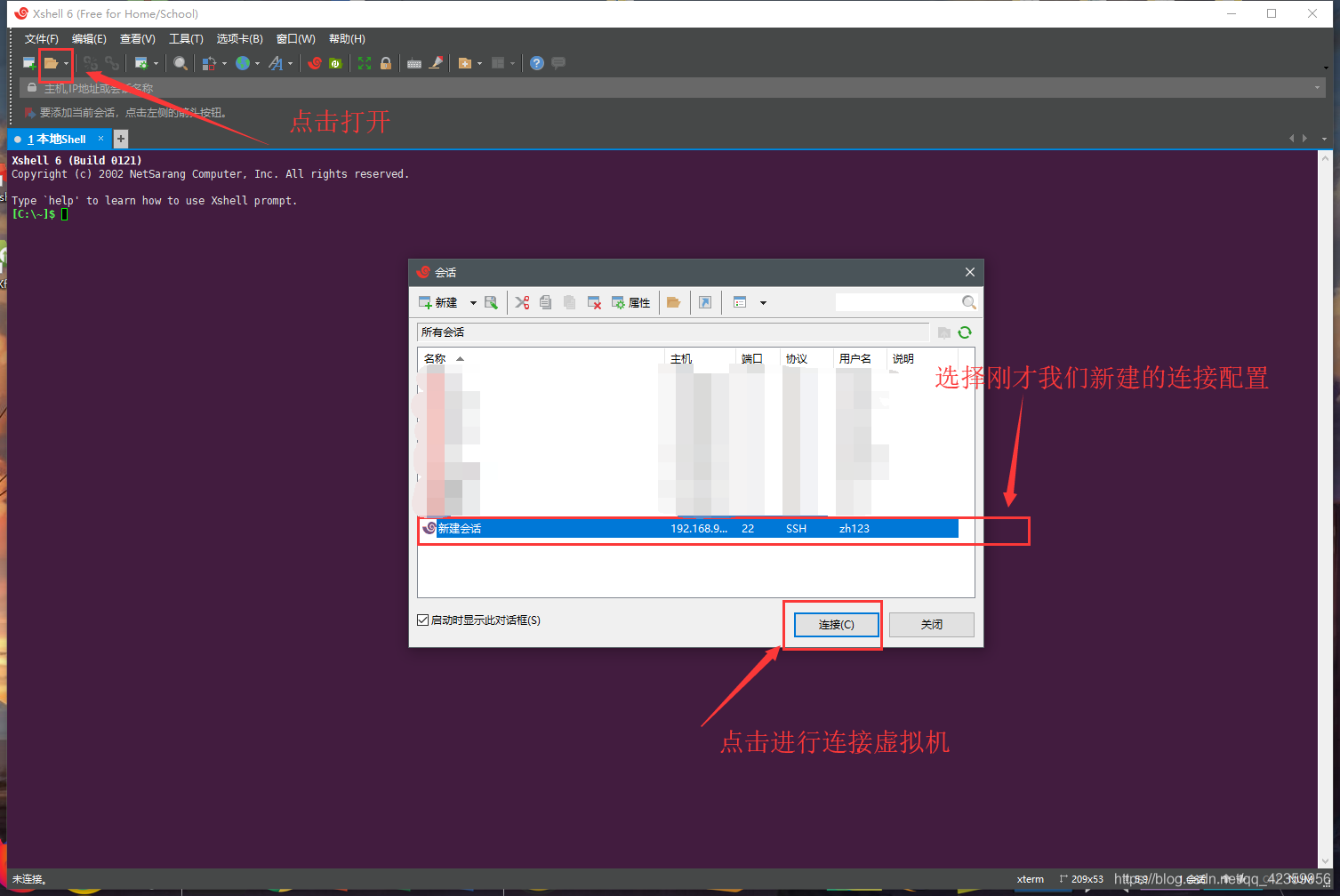
点击保存连接的公钥
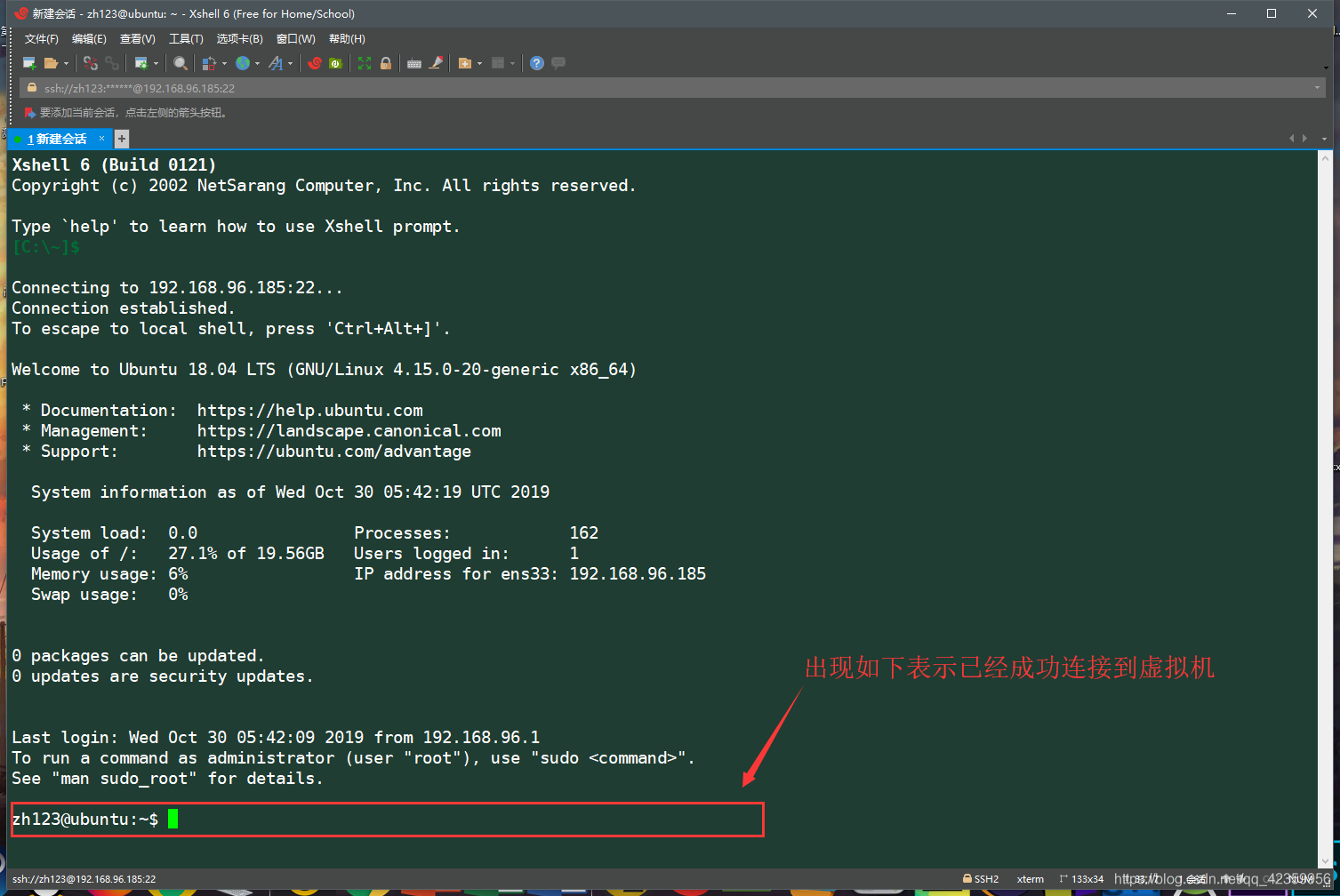
(7)出现如下图片所示即连接成功(这里可能大家会有疑惑为什么你的颜色跟笔者的不一样,这里是没有关系的,你可以自己调整一下终端的字体颜色和背景)
- 2、使用Xftp将Windows上下载的hadoop和JDK安装包上传到Ubuntu虚拟机上
(1)点击Xshell上绿色的这个Xftp按钮
(2)选择Windows对应要上传的文件拖拽(上传)到Ubuntu虚拟机上
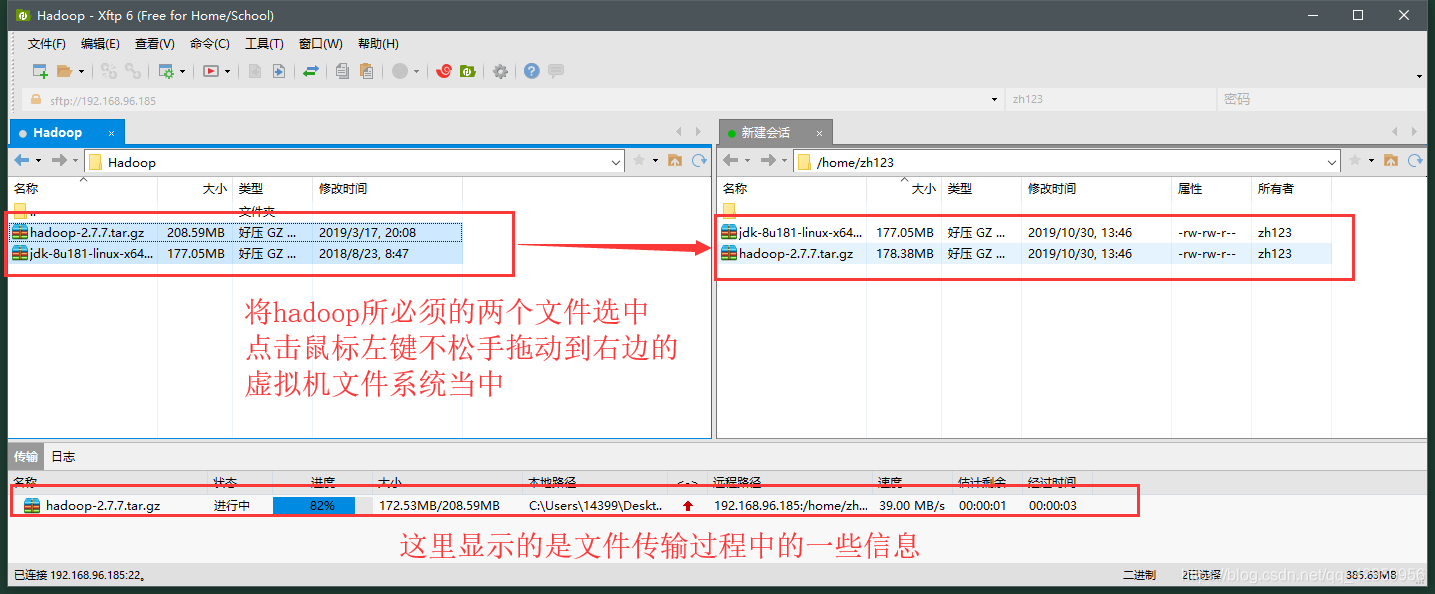
(3)上传完毕,返回到Xshell中查看刚才上传的两个文件
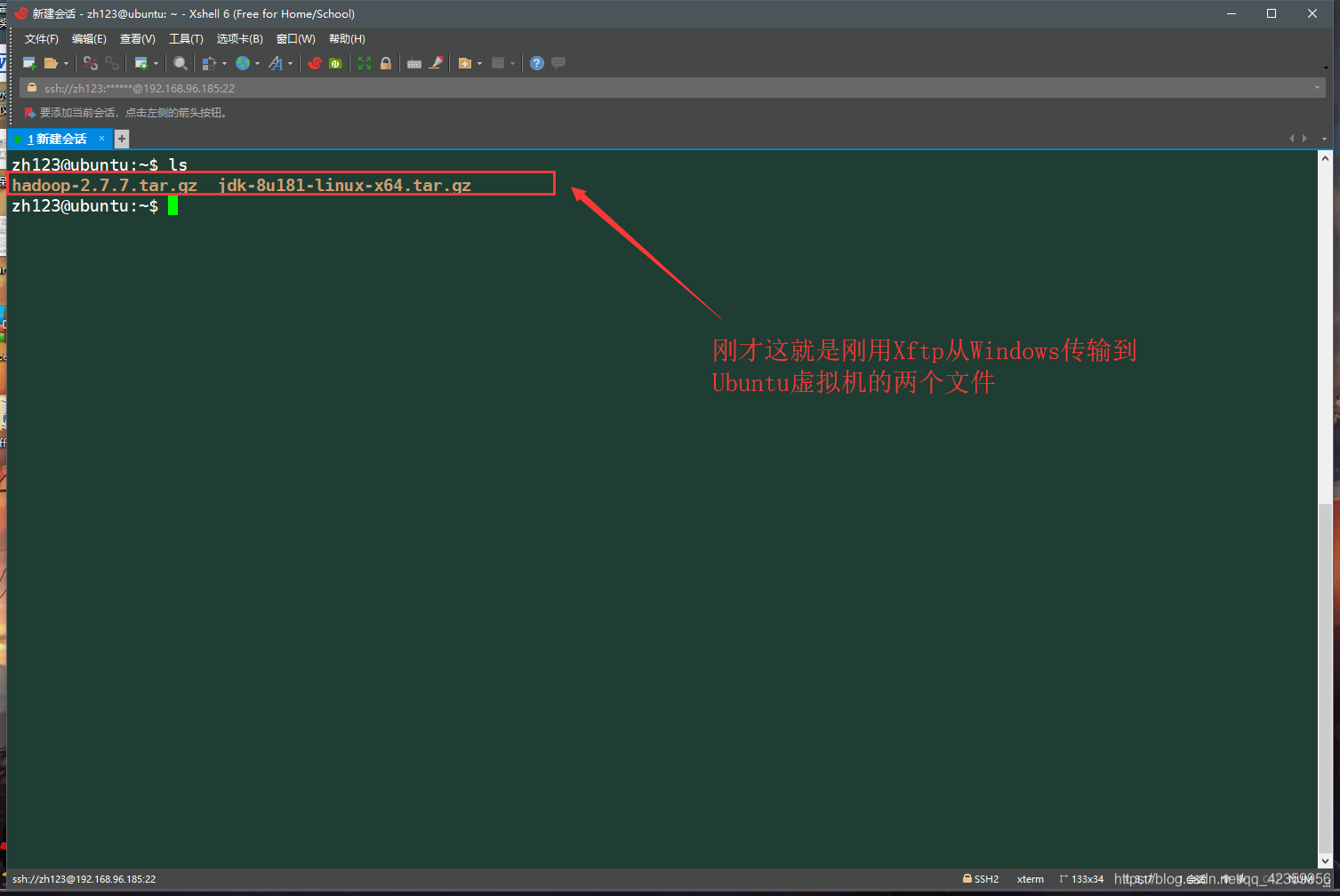
三、配置Hadoop
- 1、JDK的安装与配置(因为hadoop是使用java作为开发的,所以hadoop的运行要依赖与java环境,所以JDK的安装是必不可少的)
(1)在当前用户的home目录下新建opt目录(我们将把这个新建的目录作为所有大数据组件的安装目录)

(2)将JDK文件解压到刚才新建的opt目录下

(3)使用 cd ~/opt 命令进入刚才新建的目录下

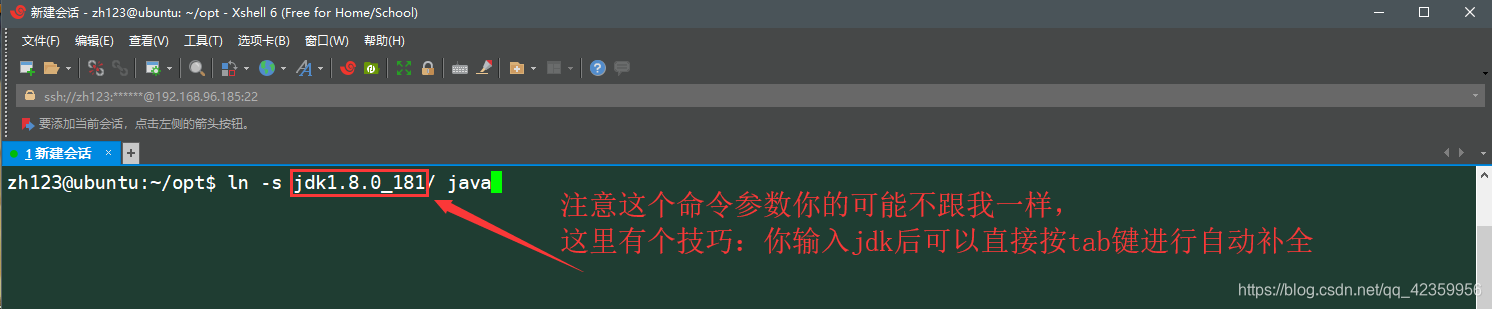
(4)使用 “ ln -s “命令为刚才解压的jdk文件创建一个软连接
(5)使用 vim ~/.bashrc 命令进入修改用户环境变量(如果读者第一次接触vim命令操作起来可能会有一点难,请认真看截图的操作)

进来后按键盘 i 键 使得编辑器变为插入模式(按下后左下角会出现–INSERT–字样这样你才能编辑此文件)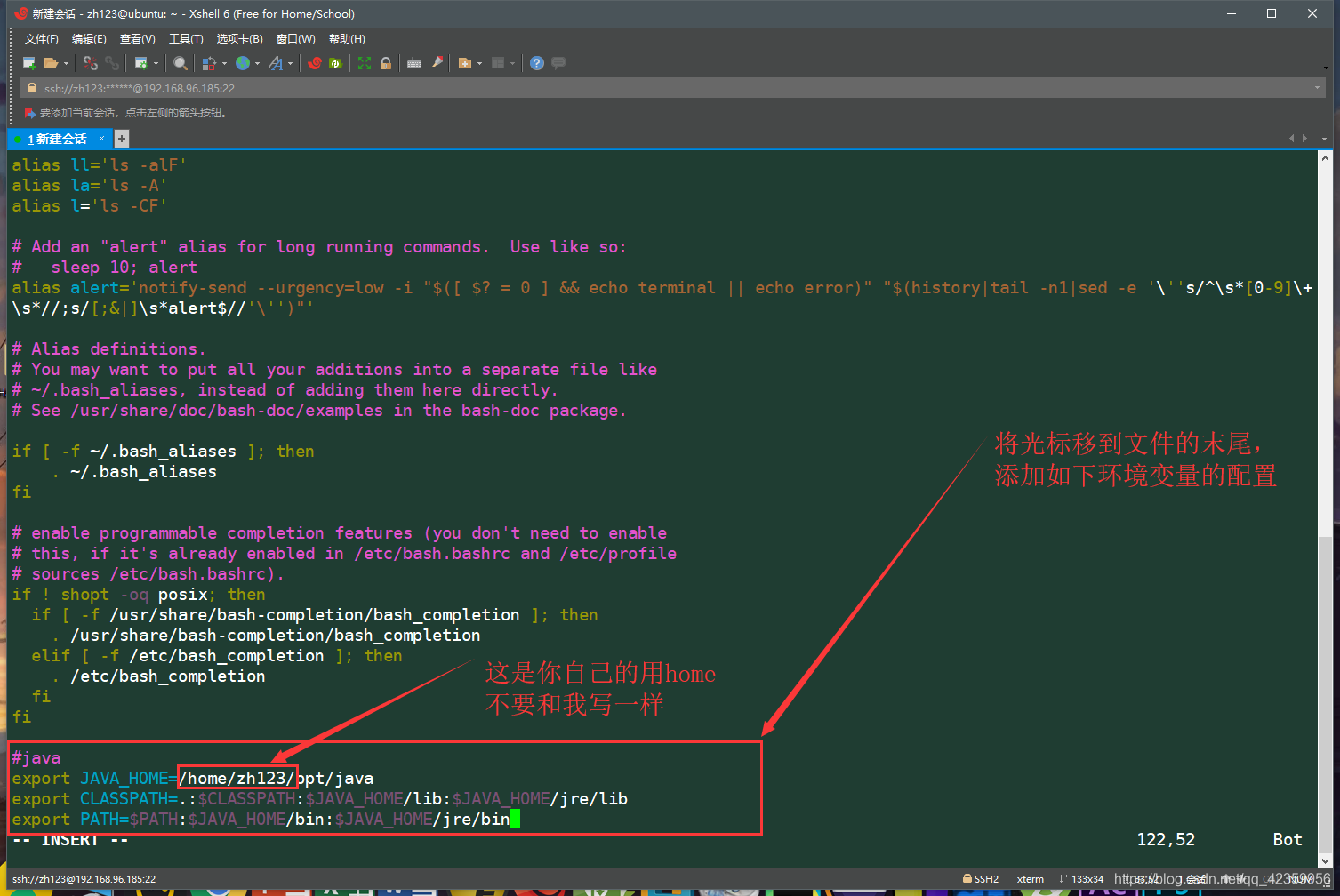



(6)保存退出后在命令行中输入命令 source ~/.bashrc 刷新一下源使刚才的配置生效

(7)输入命令 java -version 测试jdk是否配置成功
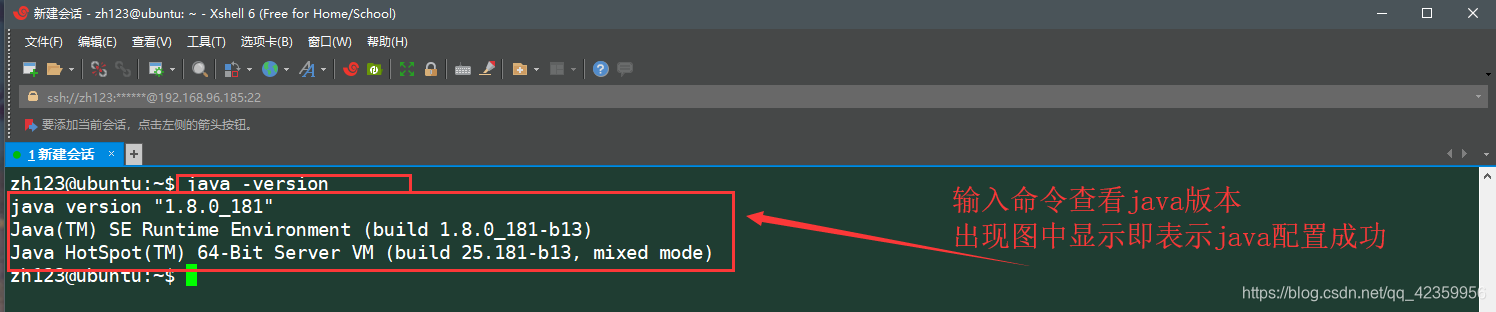
- 2、Hadoop的安装与配置(Hadoop有三种搭建模式[单机模式,伪分布模式,集群模式] 这里进行的是伪分布模式搭建)
(1)使用tar -zxvf hadoop-x.x.x.tar.gz -C ~/opt 解压hadoop文件到opt目录下

(2)cd ~/opt 进入到opt目录下再属用ln -s命令为hadoop文件创建软连接
(3)vim ~/.bashrc 编辑修改用户环境变量 再前面java环境变量后添加图片所示的内容
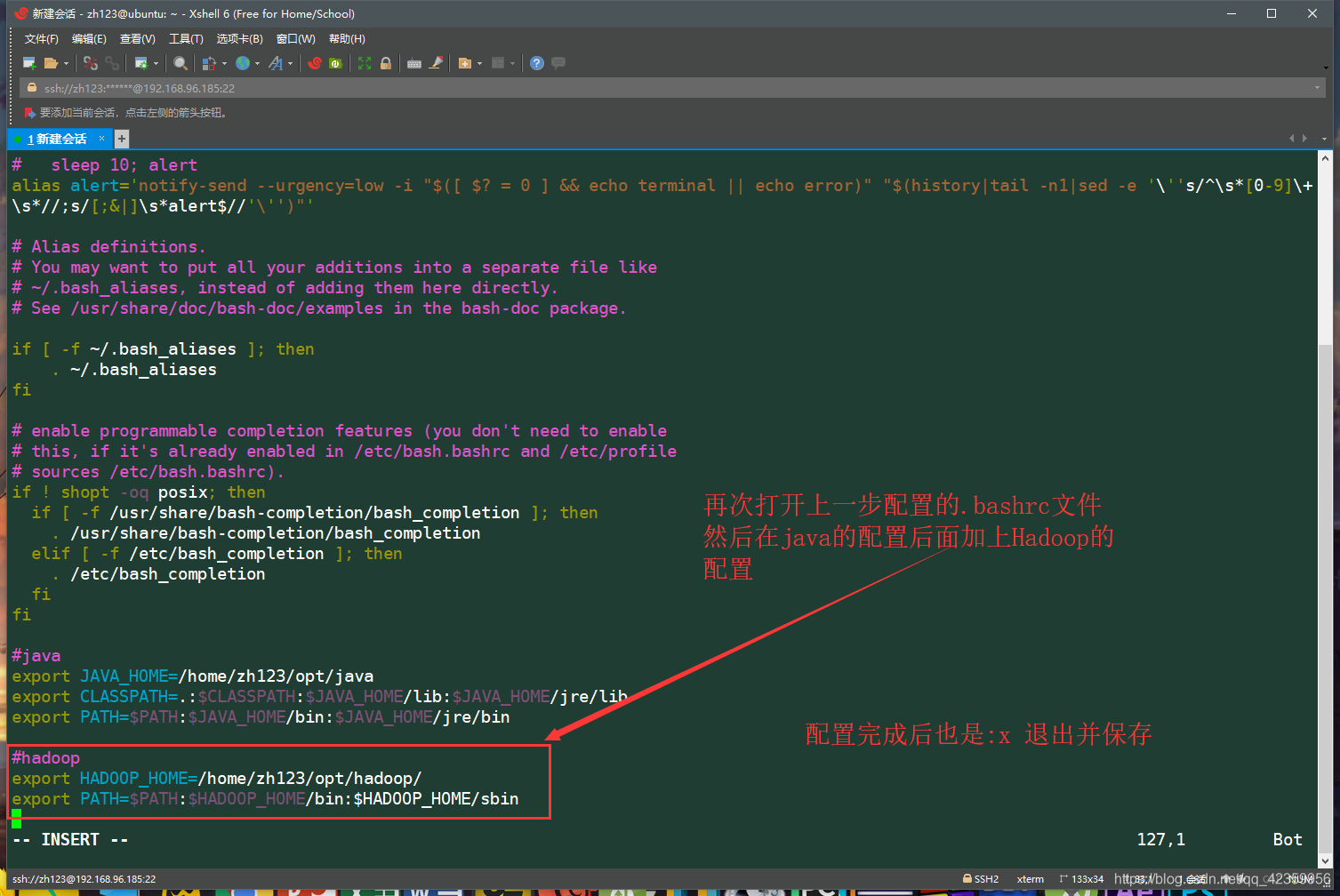
保存并退出回到命令行界面
(4)source ~/.bashrc 更新源使刚才的配置生效

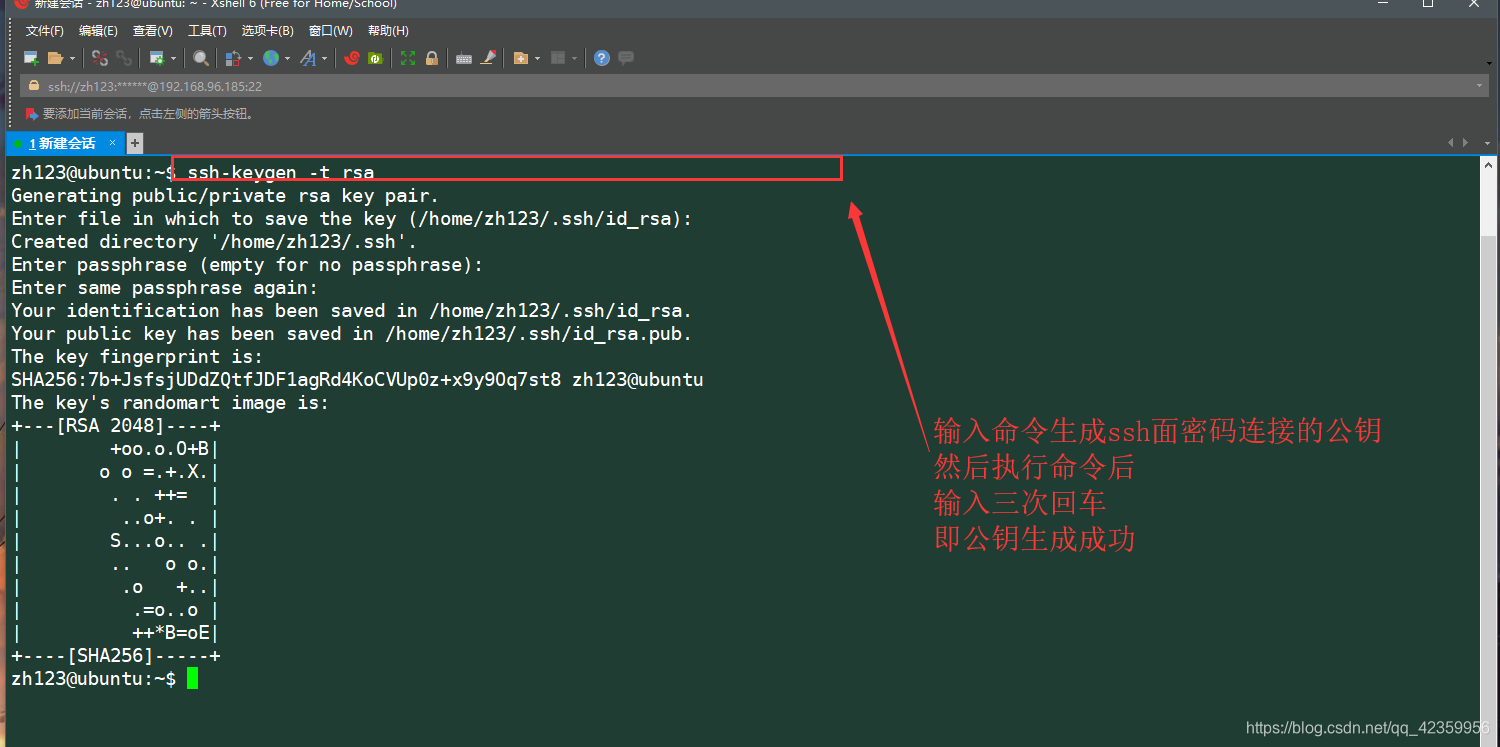
(5)使用ssh-keygen -t rsa 生成ssh的连接公钥
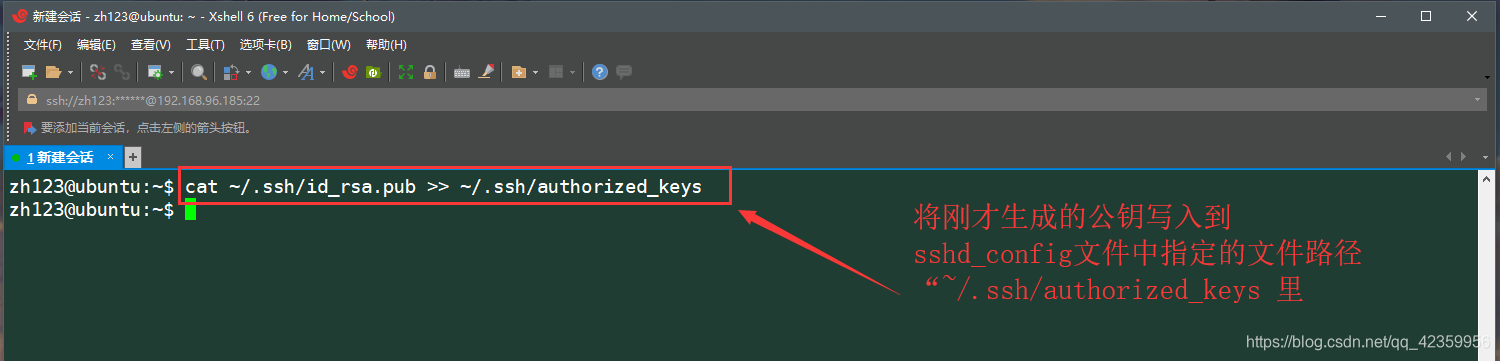
(6)使用cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 将刚才生成的公钥写入到ssh配置的指定文件当中
(7)进入hadoop 的配置文件所在目录

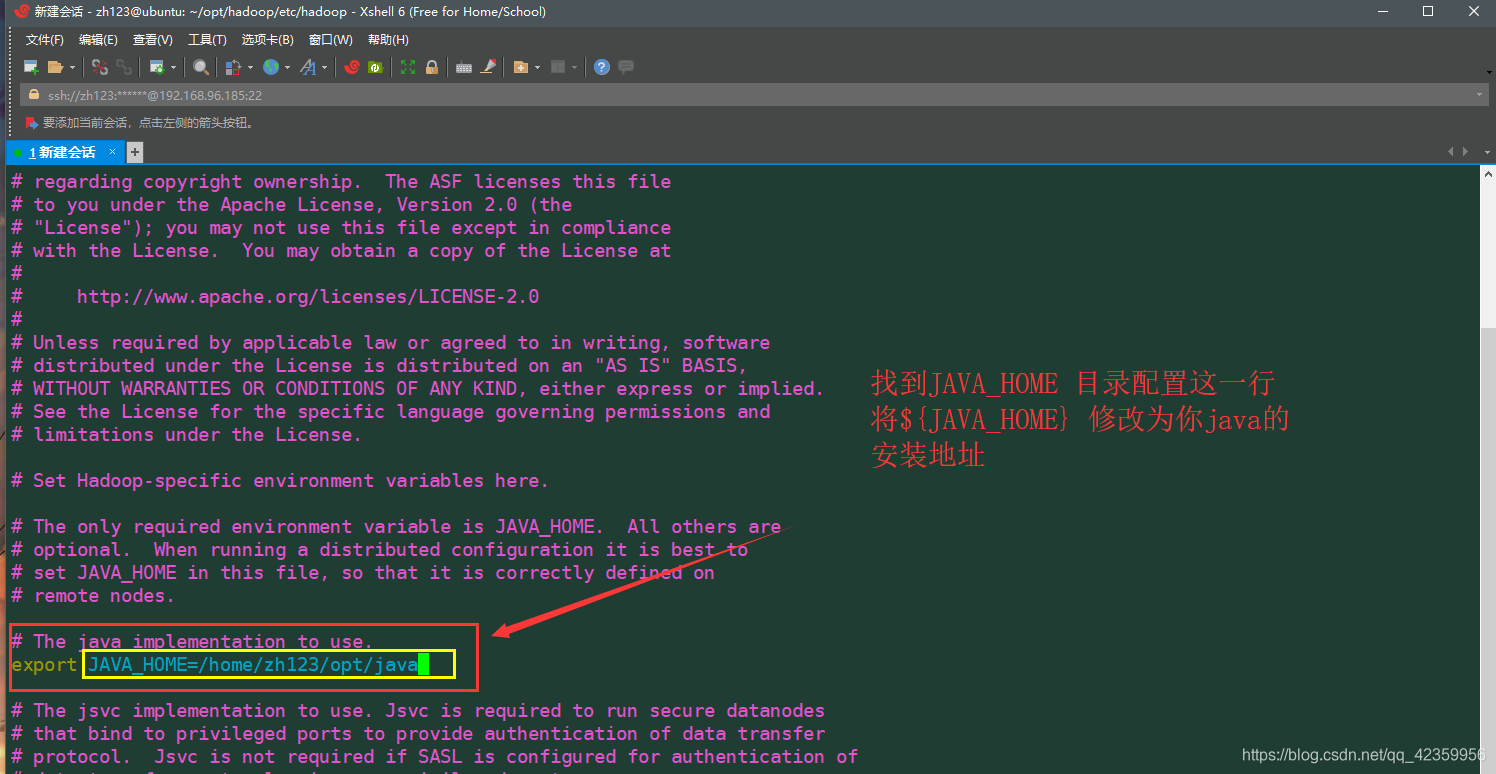
(8)编辑 vim hadoop-env.sh文件 进入后按如图配置保存后退出
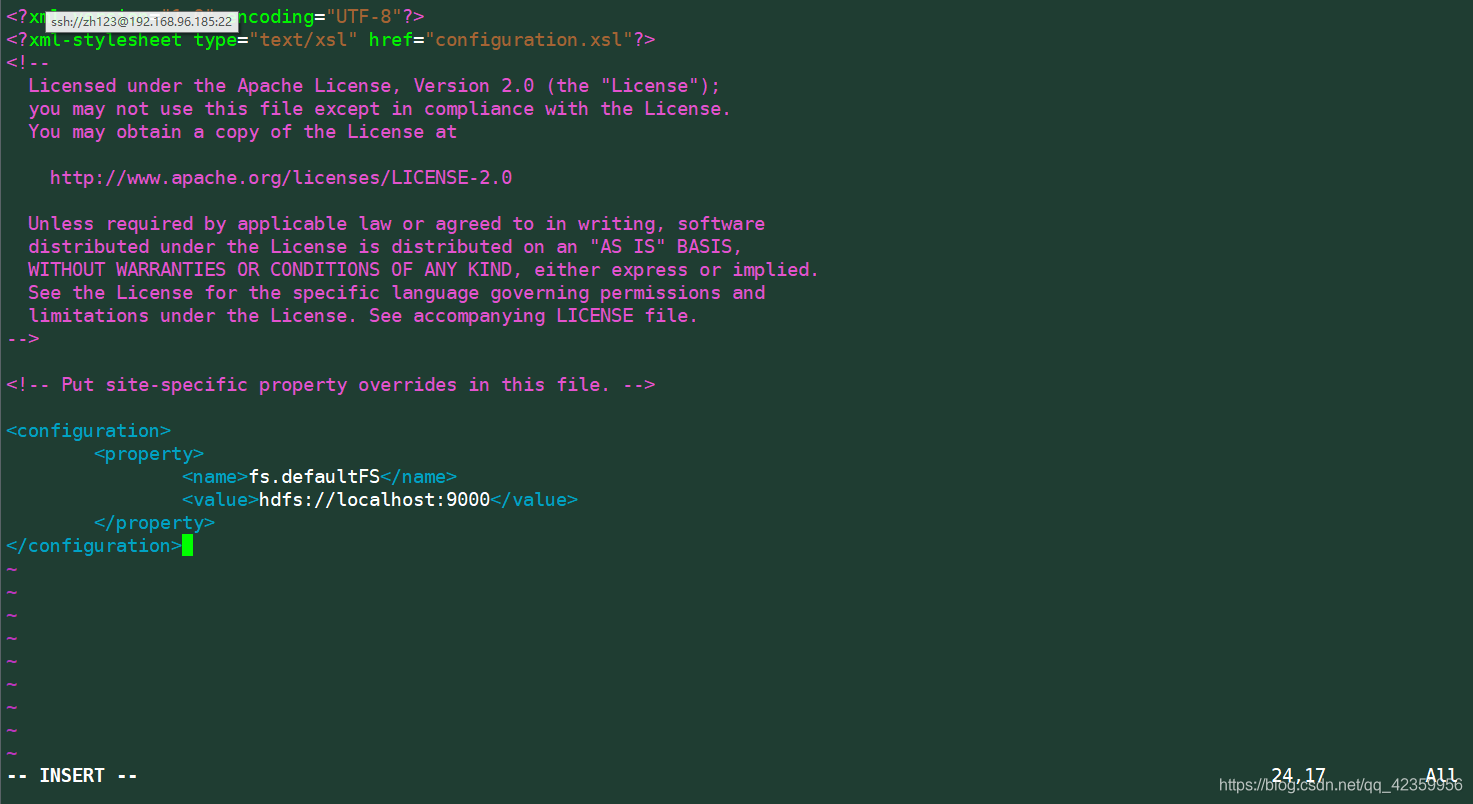
(9)修改配置文件 vim core-site.xml 按如下进行配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
(10)vim hdfs-site.xml 进入文件后按如下配置信息进行配置文件
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/zh123/opt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/home/zh123/opt/hadoop/dfs/data</value>
</property>
</configuration>

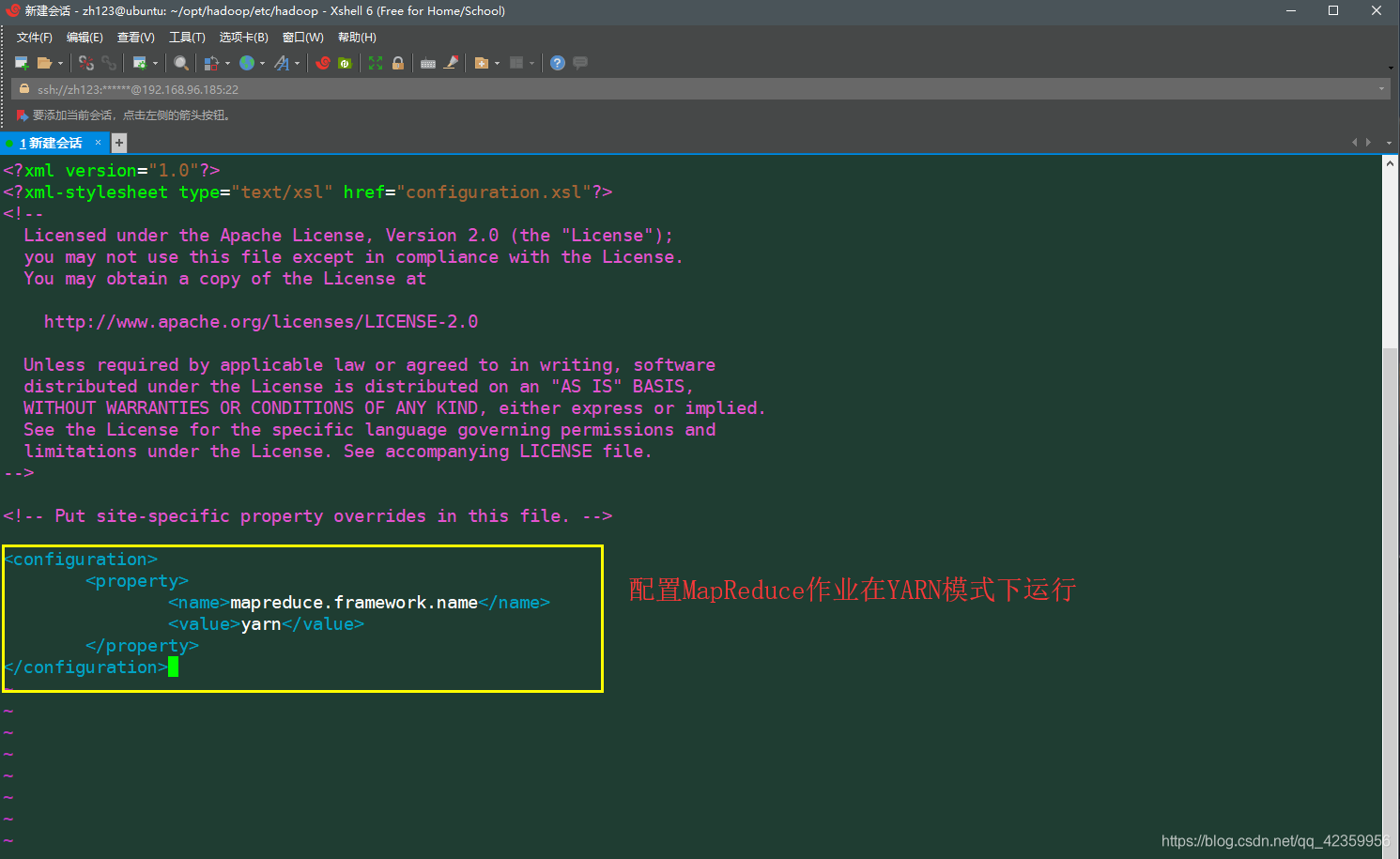
(11)配置mapred-site.xml 文件,因为这个文件最先是不存再得所以我们先要从他原本目录含有得这个mapred-site.xml.template中复制一份出来
:cp mapred-site.xml.template mapred-site.xml
然后 vim mapred-site.xml 按如下配置信息编辑文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
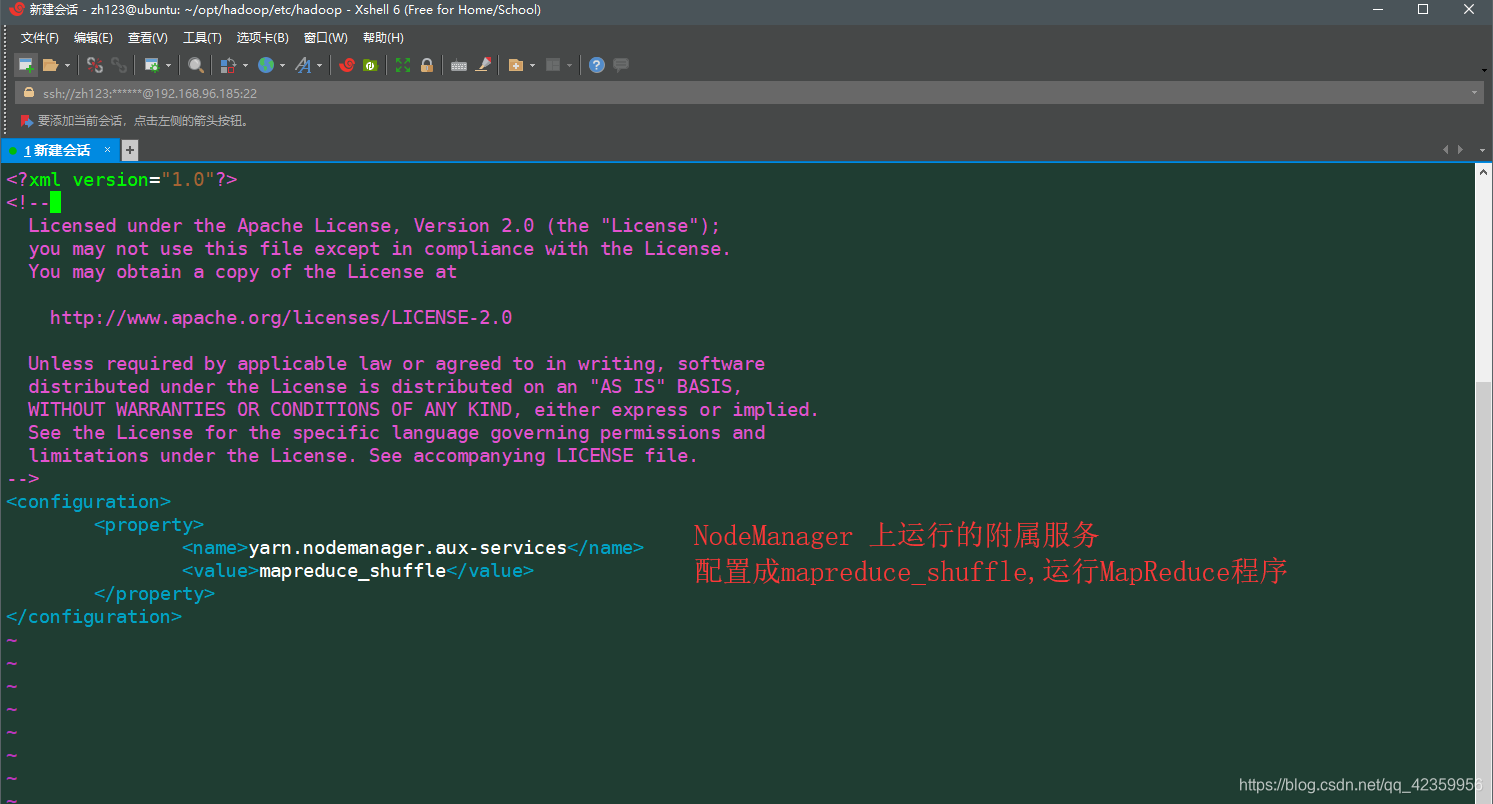
(12)vim yarn-site.xml 按如下配置信息进行配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
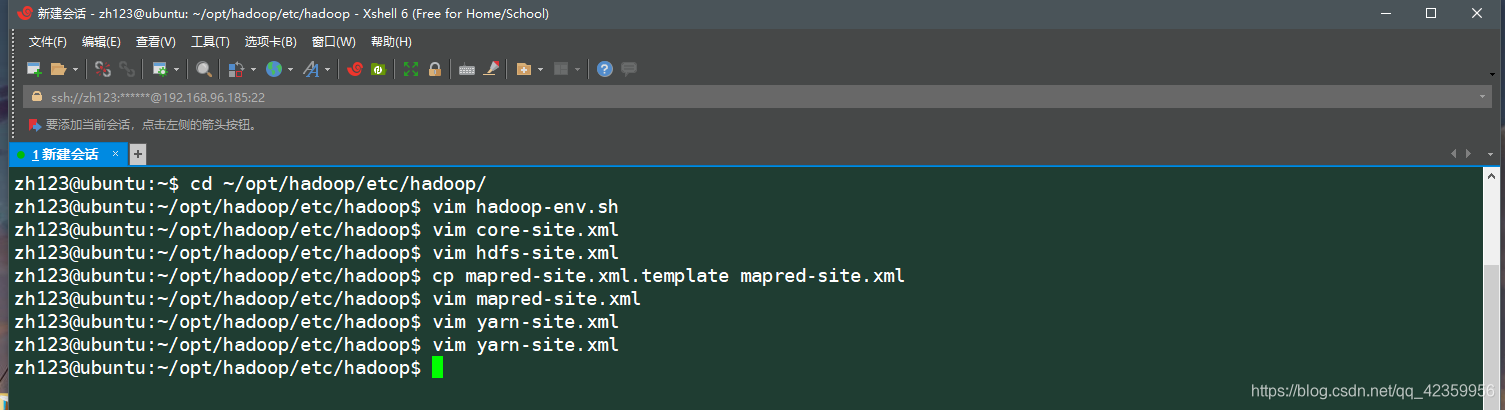
上面就是配置伪分布式下得hadoop要修改得配置文件名
四、启动hadoop
- 1、格式化namenode(注意!!! 只有第一次启动hadoop才执行此命令进行格式化namenode)
hdfs namenode -format

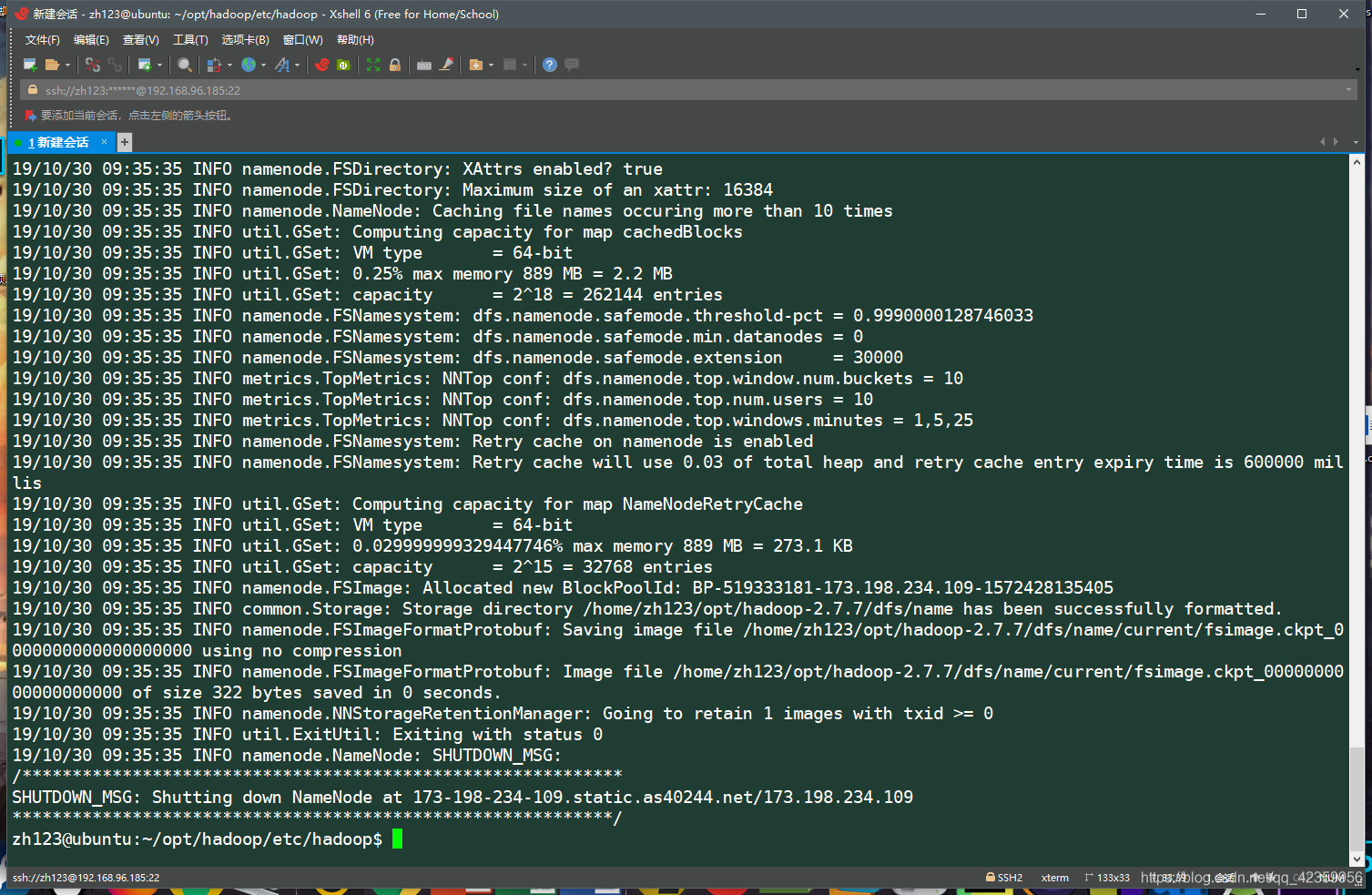
看输出得日志信息如没有错误提示即表示namenode格式化成功 - 2、启动Hadoop服务
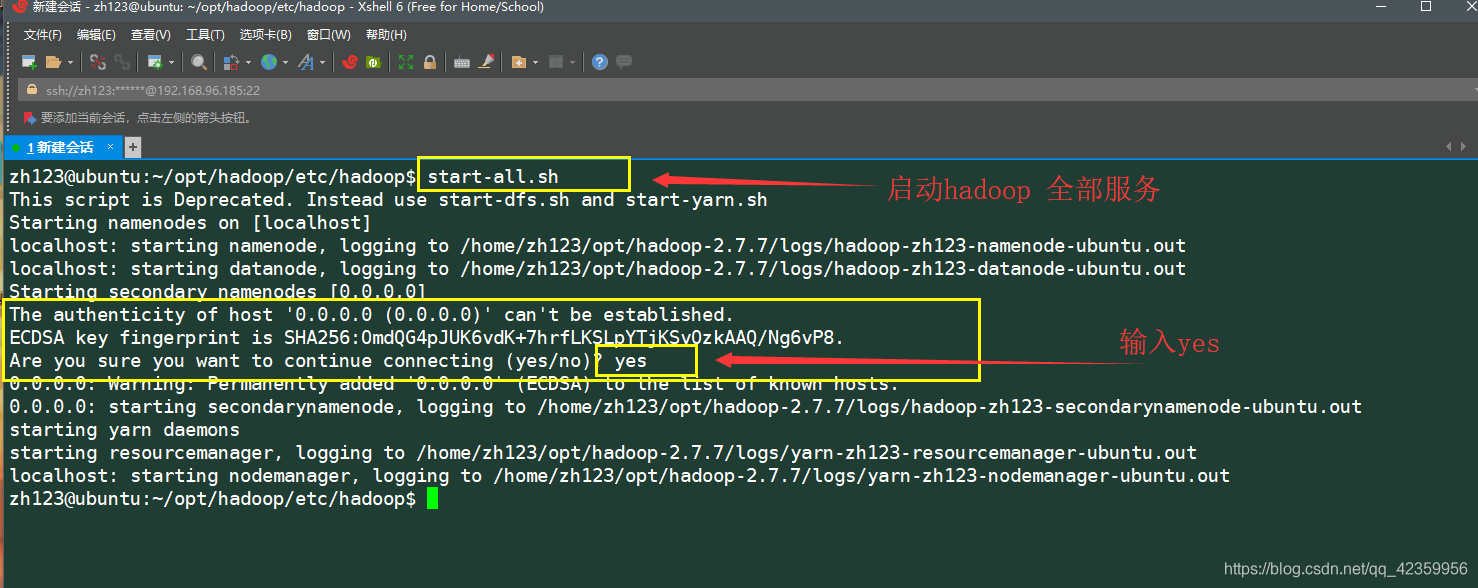
使用命令 start-all.sh 启动hadoop的所有服务
再命令行输入jps命令查看,正在活跃的java进程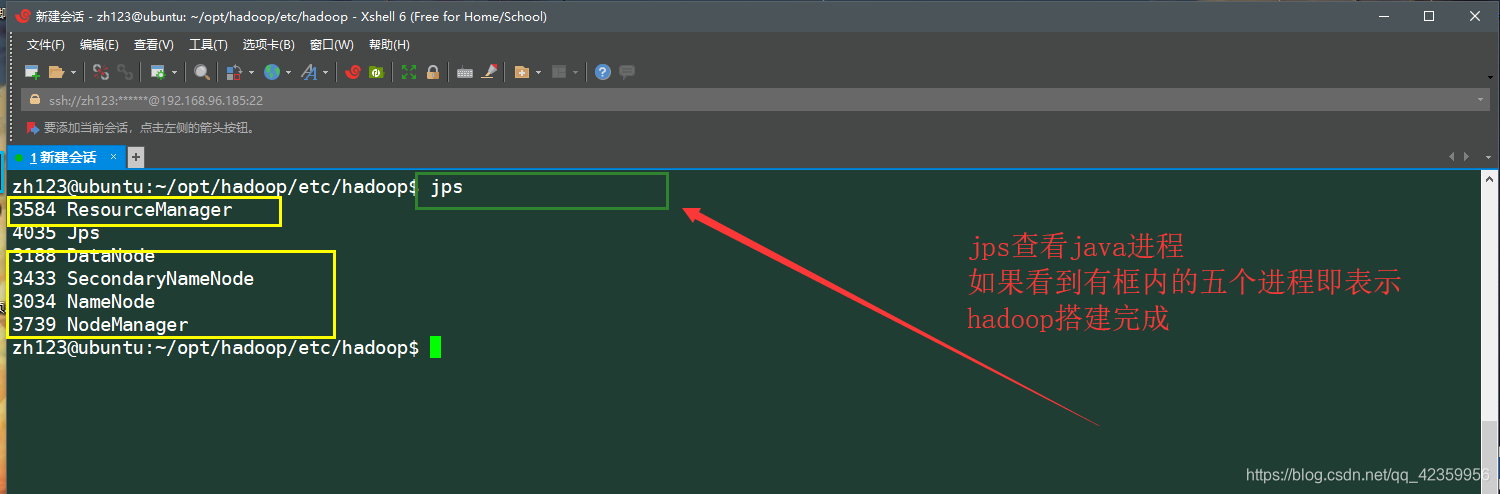
使用命令 hdfs dfsadmin -report 可以查看hdfs的详细信息
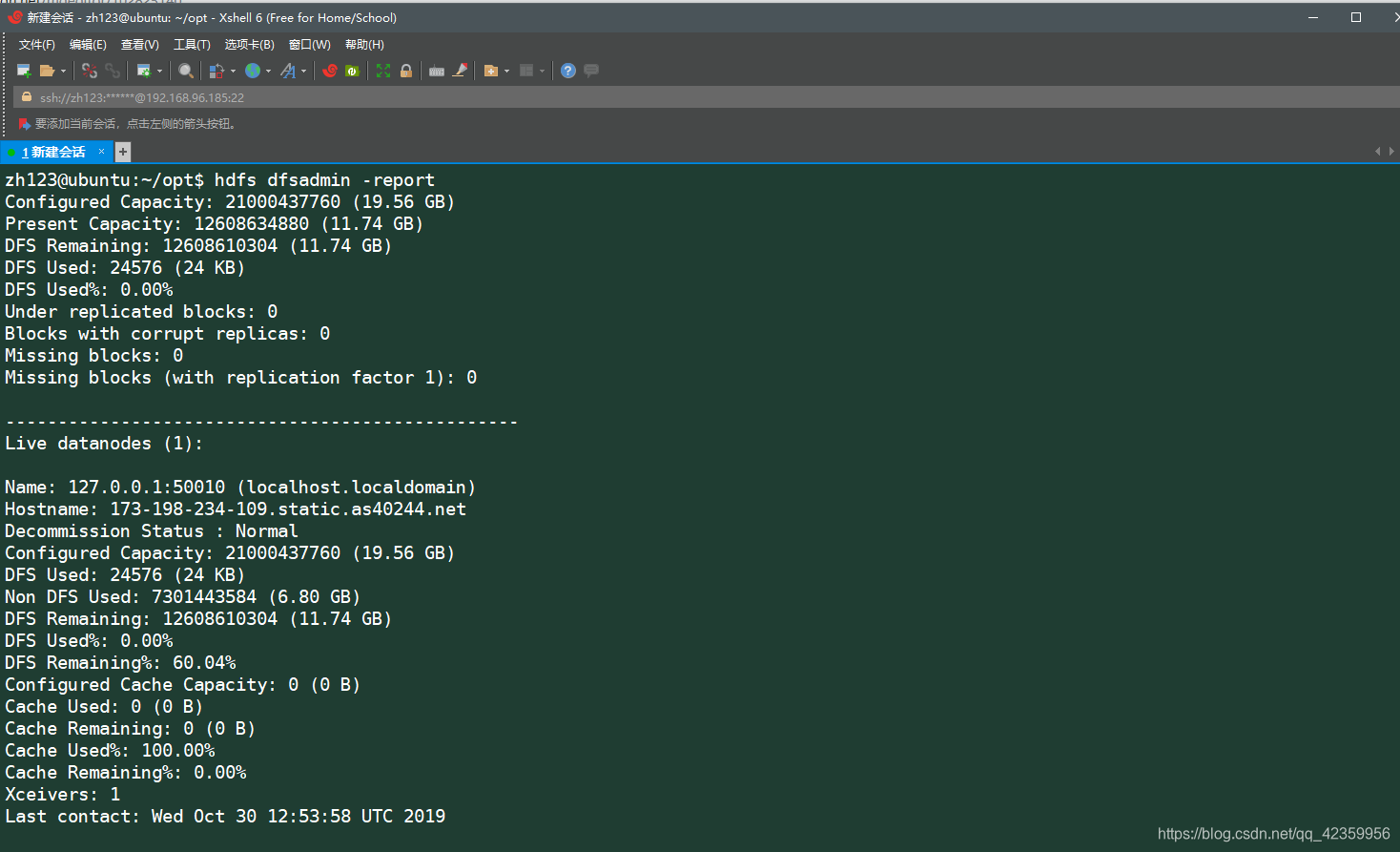
至此Hadoop的伪分布式环境已搭建完成,如果小伙伴再配置hadoop的过程中发现问题请在下面进行评论,进行探讨!!!
