大数据环境部署 第五章——Spark 伪分布式搭建
前言:本文为系列教程,至此默认读者已经安装好了Hadoop,jdk;
如还未配置好上述服务,可以查看笔者前面的博文进行参考配置
一、准备阶段
- scala文件下载及配置
(1) 进入scala官网复制下载链接
下载官网:https://www.scala-lang.org/download/
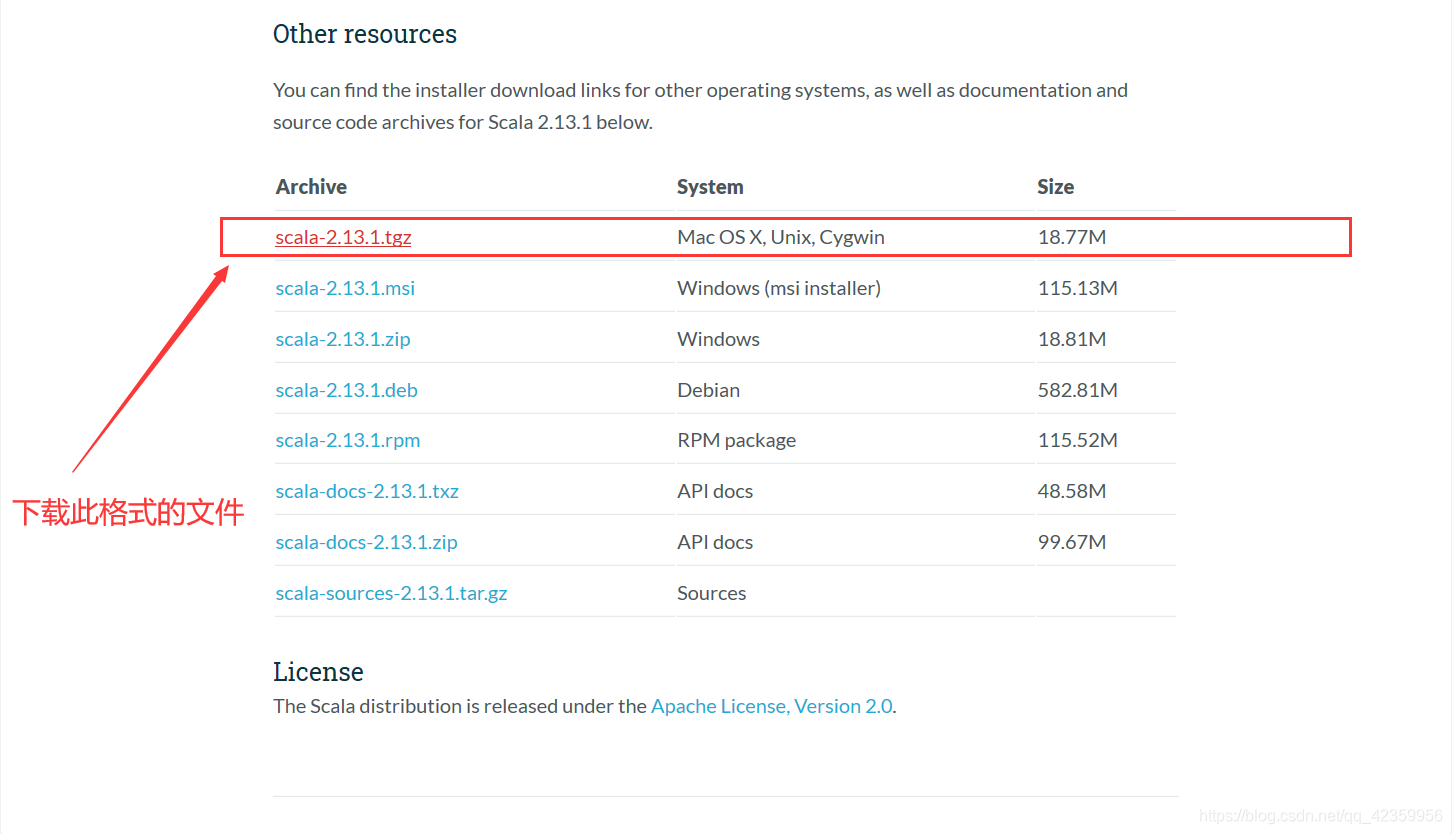
进入官网后下拉到底部选择此格式文件复制下载链接
(2)下载并解压文件
命令:wget https://downloads.lightbend.com/scala/2.13.1/scala-2.13.1.tgz
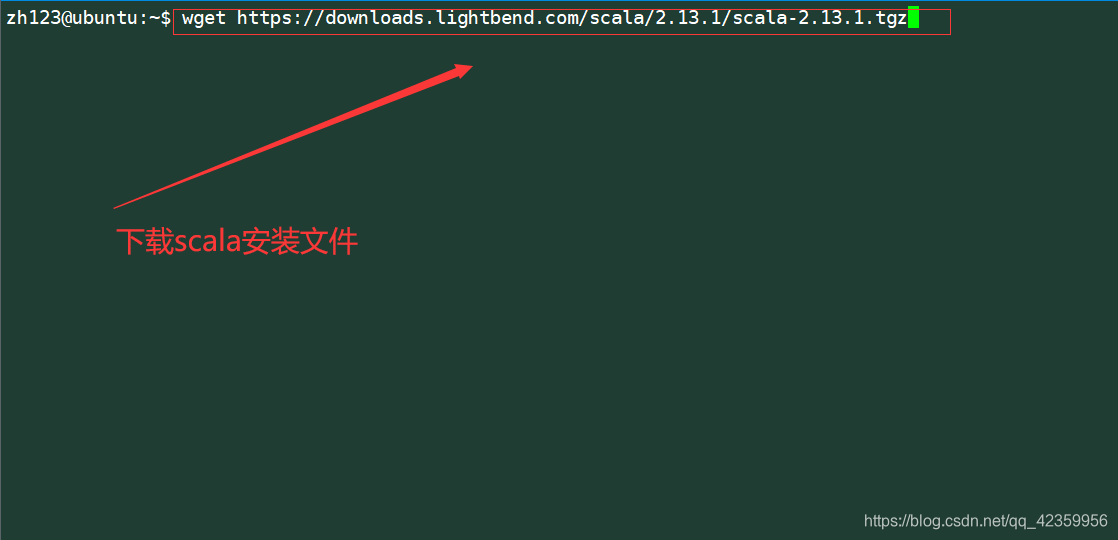
将下载好的文件解压到~/opt/目录下
命令:tar -zxvf scala-2.13.1.tgz -C ~/opt/
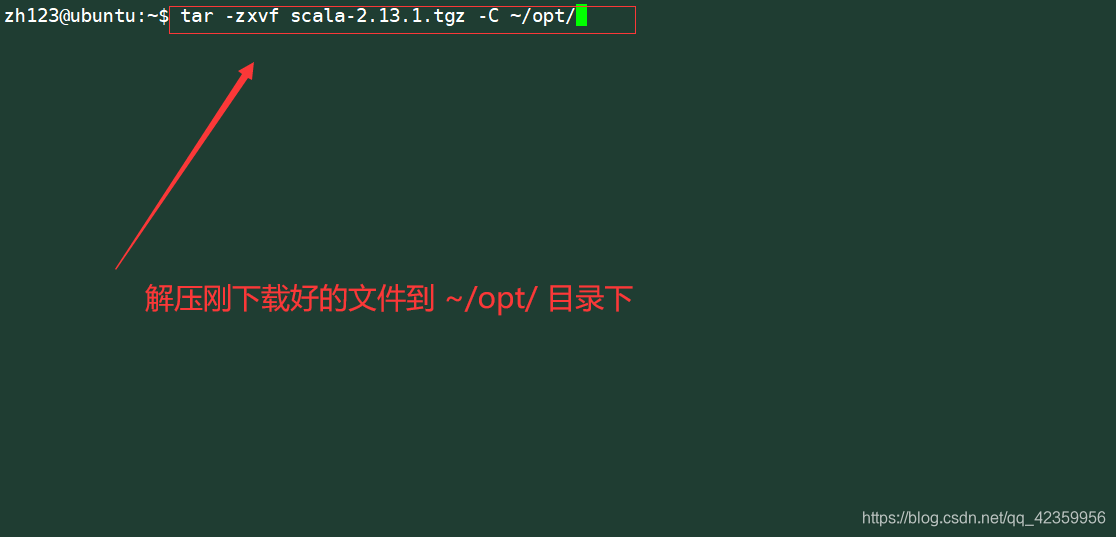
创建软连接便于后面的维护
命令:ln -s ~/opt/scala-2.13.1/ ~/opt/scala
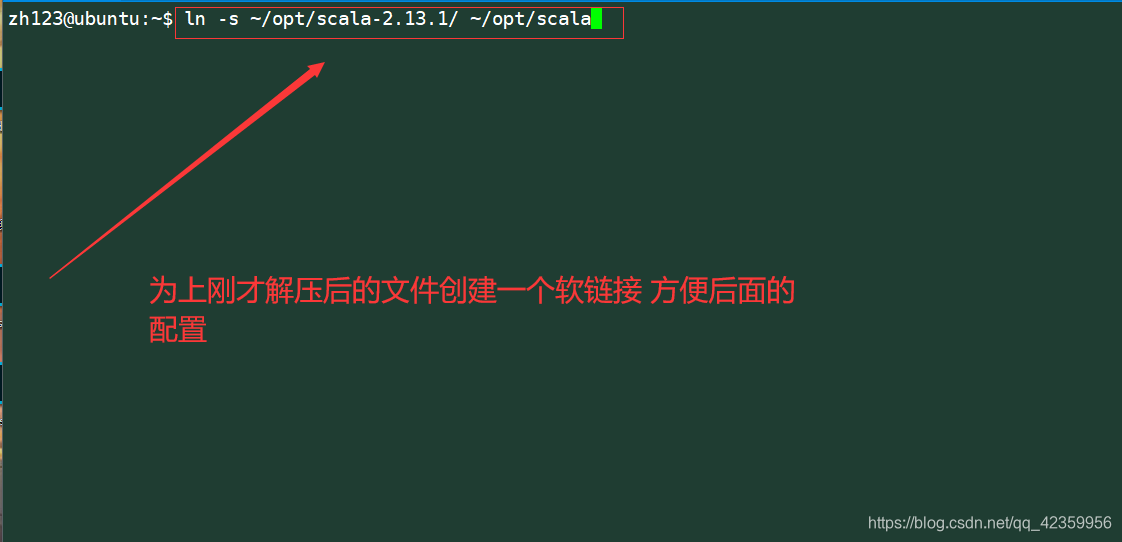
修改.bashrc 文件配置scala的环境
命令:vim .bashrc
在文件的末尾插入scala的位置信息
export SCALA_HOME=/home/zh123/opt/scala
export PATH=$PATH:$SCALA_HOME/bin
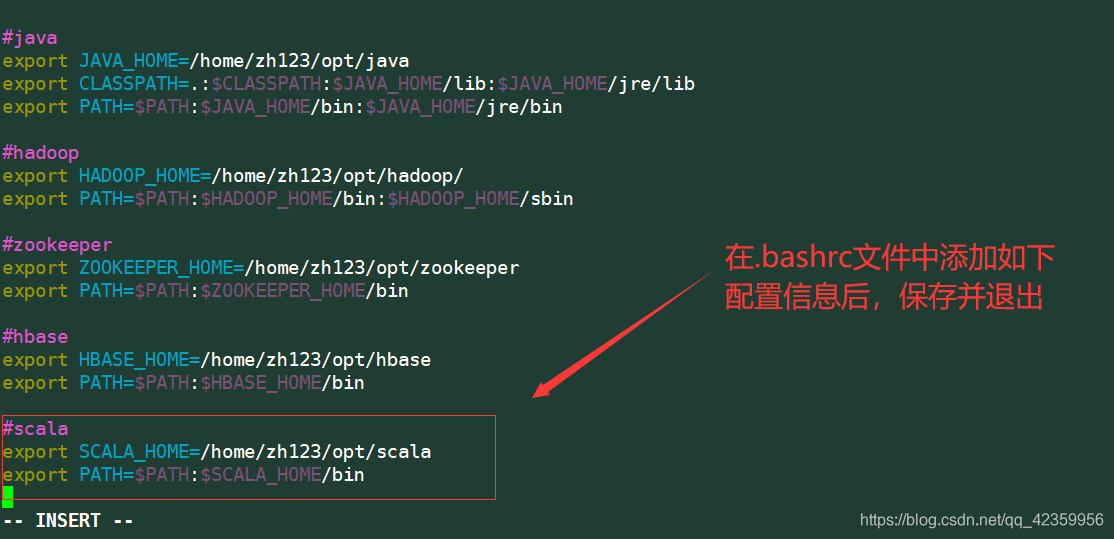
修改完毕后使用命令:
source .bashrc 使得刚才的配置生效
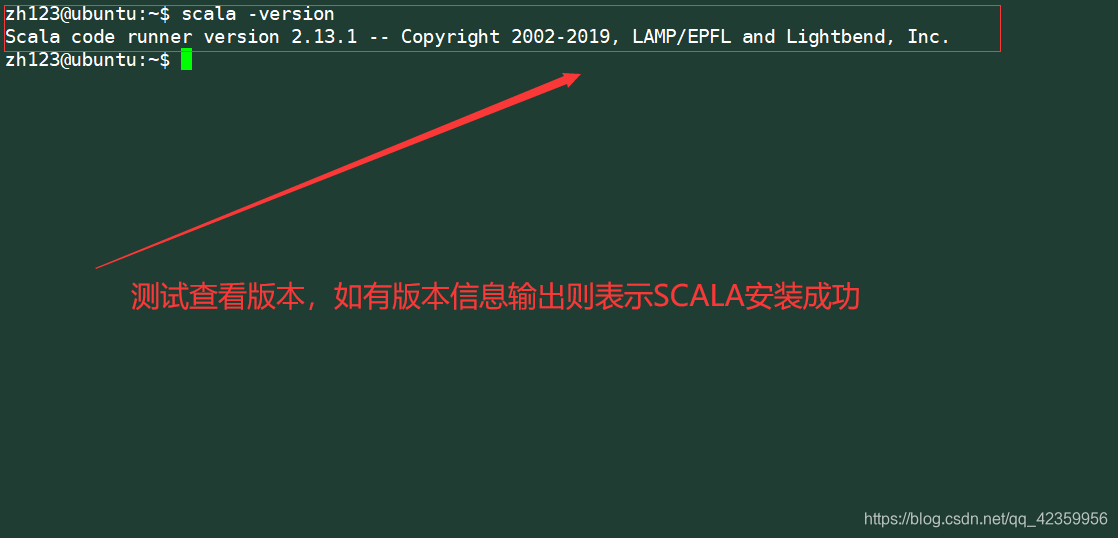
然后使用命令
scala -version 测试查看scala版本是否能够查看成功
- spark文件下载
(1)进入官网
官网地址:http://spark.apache.org/downloads.html
选择需要的版本进行下载
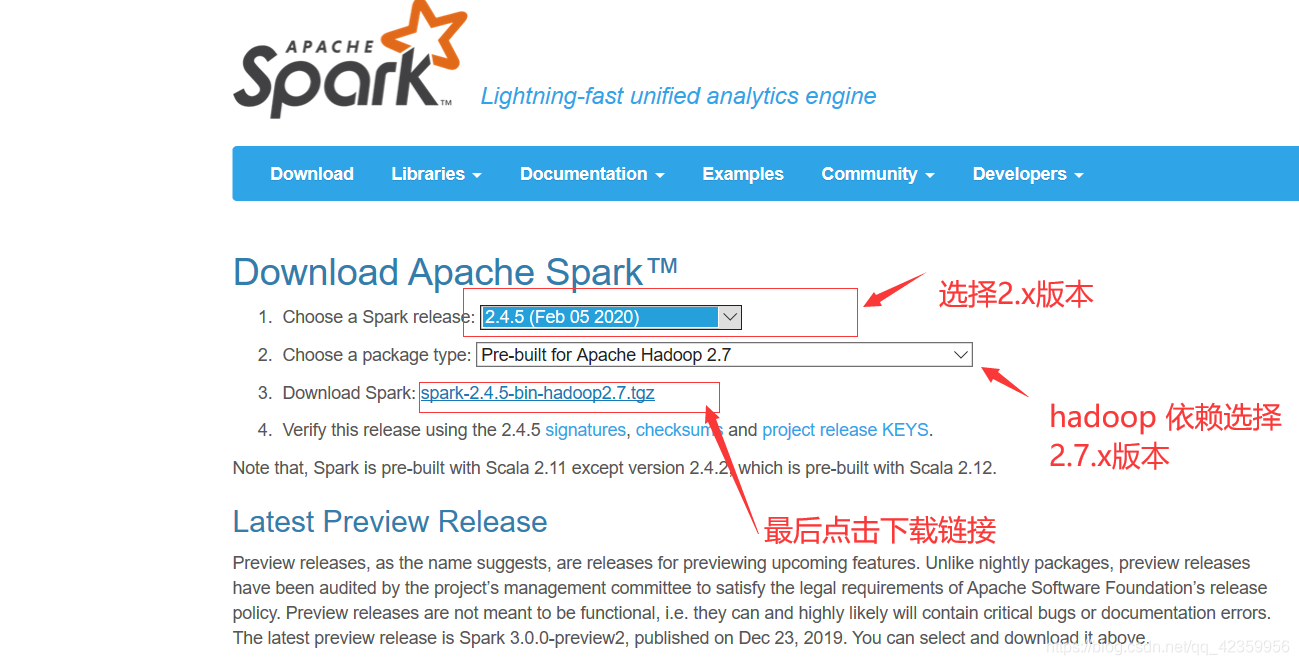
复制清华源镜像下载链接
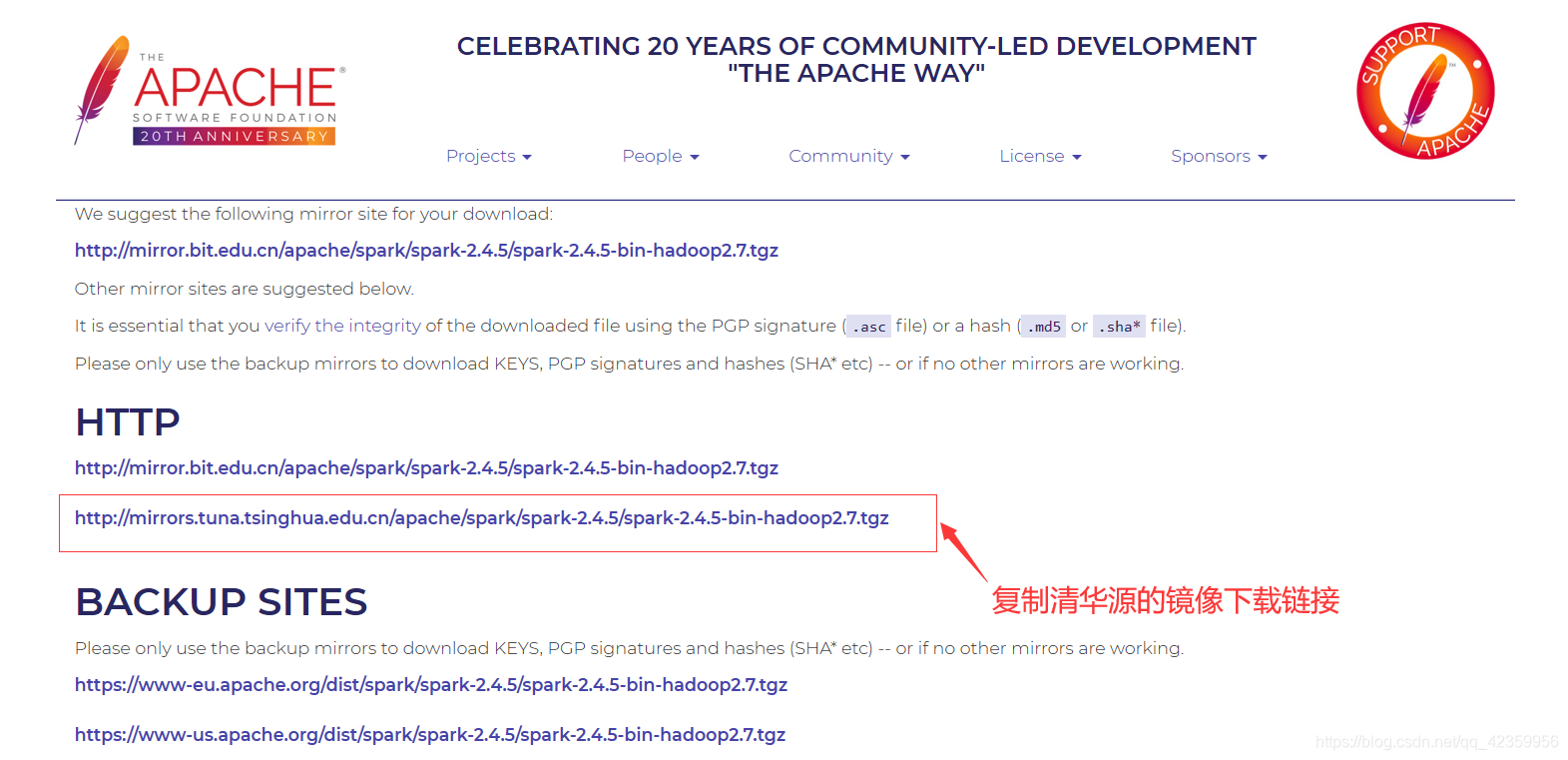
(2)下载并解压文件
命令 wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
将下载好文件解压到~/opt/目录下
命令:tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C ~/opt/
为解压后的文件创建软连接
命令:ln -s ~/opt/spark-2.4.5-bing-hadoop2.7/ ~/opt/spark
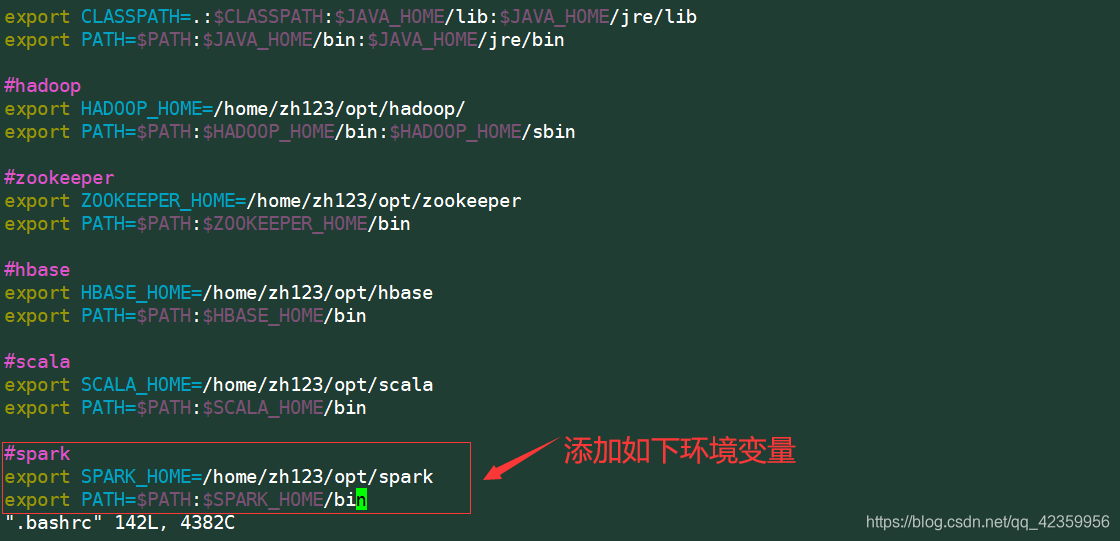
编辑.bashrc文件添加路径信息
命令:vim .bashrc
添加内容:
export SPARK_HOME=/home/zh123/opt/spark
export PATH=$PATH:$SPARK_HOME/bin
二、spark环境配置
- 1、拷贝spark配置示例
命令:cp spark-env.sh.template spark-env.sh
- 2、修改配置文件spark-env.sh
命令:vim spark-env.sh
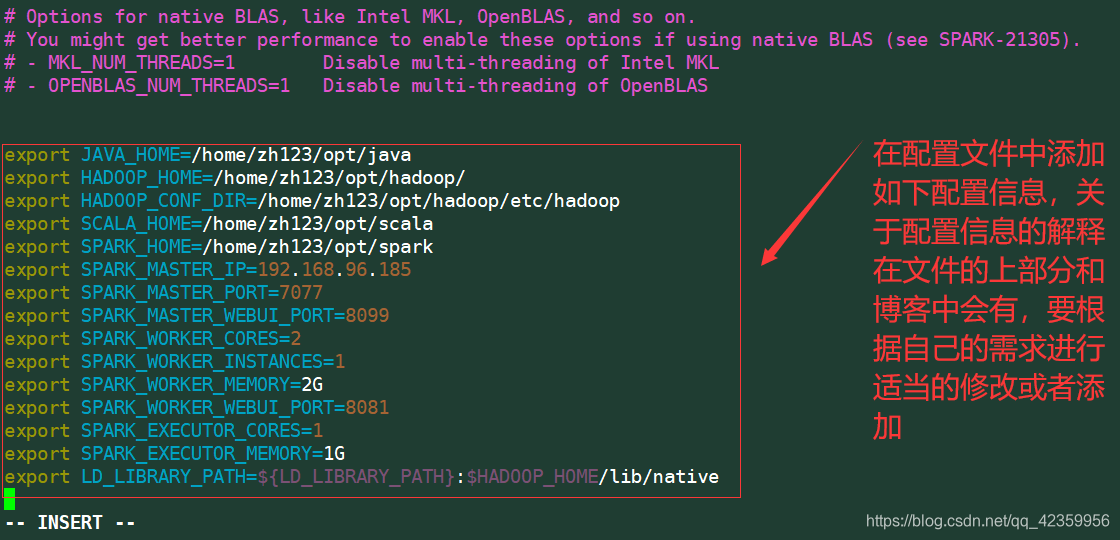
添加内容:
export JAVA_HOME=/home/zh123/opt/java export
HADOOP_HOME=/home/zh123/hadoop export
HADOOP_CONF_DIR=/home/zh123/hadoop/etc/hadoop export
SCALA_HOME=/home/zh123/scala export SPARK_HOME=/home/zh123/spark
export SPARK_MASTER_IP=192.168.96.185 export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8099 export SPARK_WORKER_CORES=2 export
SPARK_WORKER_INSTANCES=1 export SPARK_WORKER_MEMORY=2G export
SPARK_WORKER_WEBUI_PORT=8081 export SPARK_EXECUTOR_CORES=1 export
SPARK_EXECUTOR_MEMORY=1G export
LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native
内容解释:
| 变量名 | 解释 |
|---|---|
| JAVA_HOME | jdk的安装目录 |
| HADOOP_HOME | hadoop的安装目录 |
| HADOOP_CONF_DIR | hadoop的配置文件存放目录 |
| SCALA_HOME | scala的安装目录 |
| SPARK_HOME | spark的安装目录 |
| SPARK_MASTER_IP | spark主节点绑定的地址 |
| SPARK_MASTER_PORT | spark主节点绑定的端口号 |
| SPARK_MASTER_WEBUI_PORT | spark master节点的网页端口 |
| SPARK_WORKER_CORES | worker使用的cpu核心数 |
| SPARK_WORKER_INSTANCES | 最多能够同时启动的EXECUTOR的实例个数 |
| SPARK_WORKER_MEMORY | worker分配的内存数量 |
| SPARK_WORKER_WEBUI_PORT | worker的网页查看绑定的端口号 |
| SPARK_EXECUTOR_CORES | 每个executor分配的cpu核心数 |
| SPARK_EXECUTOR_MEMORY | 每个executor分配的内存数 |
| LD_LIBRARY_PATH | 指定查找共享库 |
- 3、配置salve节点
拷贝原来的示例配置文件一份
命令:cp slaves.template slaves
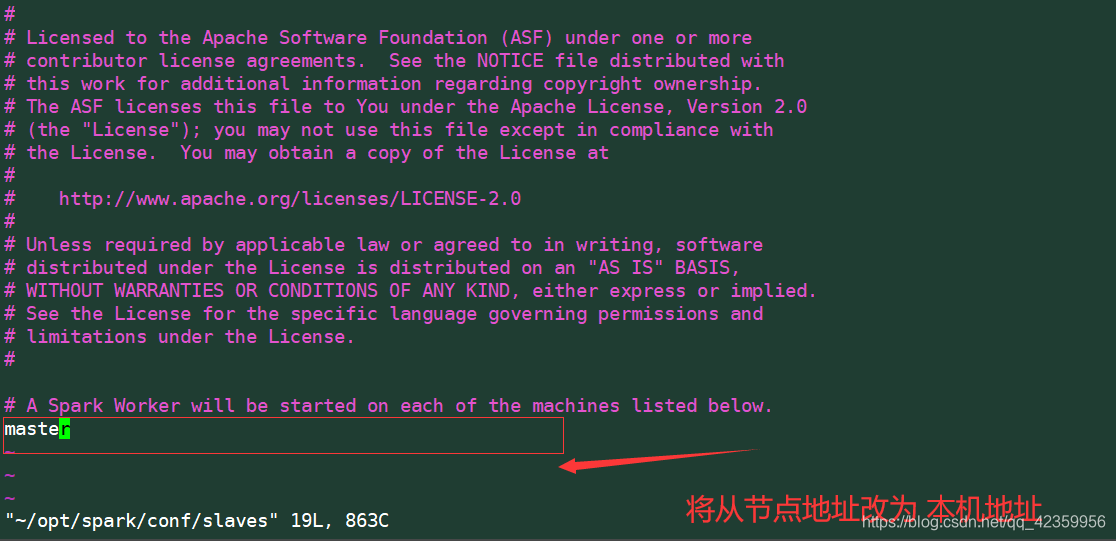
编辑slaves文件
修改slave节点地址
!!!注意笔者这里写的是master 它隐射的IP地址是本机的IP地址(192.168.96.185)
大家如果没有进行配置映射这里是会地址解析错误的
读者在配置这里的时候需要查看/etc/hosts 文件的映射表进行查看配置
三、启动测试spark
- 首先需要先启动hadoop
命令: start-all.sh
- 启动spark
因为这里没有配置spark/sbin目录的环境变量 所以需要cd到spark的sbin目录下再进行启动(没配置此目录的环境变量是因为spark的启动文件 start-all.sh与hadoop的启动文件名重名,配了会发生冲突,解决办法可以将两个文件中的其中一个重命名即可,这里读者就没有进行相关的操作了,是直接全路径指定执行启动的)
至此spark的伪分布式安装配置就结束了
