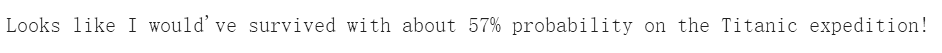版权声明:本文版权归作者所有,未经允许不得转载! https://blog.csdn.net/m0_37827994/article/details/86575877
逻辑回归
一、理论

1、二分类(logistic regression)
二项逻辑回归的主要思想是将输出的线性方程( )通过使用Simoid(Logistic)函数 限制在值(0,1)之间。
其中,
- 是预测值,N行1列(N是样本数)
- 是输入值,N行D列(D是特征数)
- 是权重,D行1列
目标:在给定输入X的情况下,预测y类的概率。
2、多分类(softmax regression)
当我们有两个以上的类时,我们需要使用多项式逻辑回归(softmax分类器)。softmax分类器将使用线性方程(z=XW)并对其进行标准化,以在给定输入的情况下输出y类的概率。
其中,
- 是预测值,N行1列(N是样本数)
- 是输入值,N行D列(D是特征数)
- 是权重,D行1列
目标:对线性输出进行规范化,以确定类的概率。
训练步骤:
1、随机初始化模型的权重
2、向模型中喂入数据
,获得逻辑KaTeX parse error: Expected 'EOF', got '}' at position 5: z=XW}̲,在逻辑上作用softmax运算得到分类的概率
。例如,如果现在有三个分类,预测出来的分类概率为[0.3,0.3,0.4]
3、将预测值
(eg.[0.3,0.3,0.4])与真实目标值
(eg.[0,0,1])进行比较,通过目标函数来决定损失函数
。对于逻辑回归,常用的目标函数是交叉损失(cross-entropy loss)。
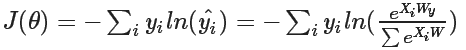
在本题中,
=[0,0,1],
=[0.3,0.3,0.4],所以
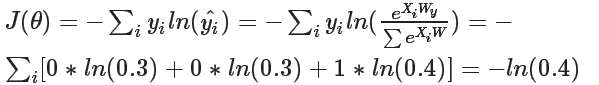
4、计算损失函数的梯度:
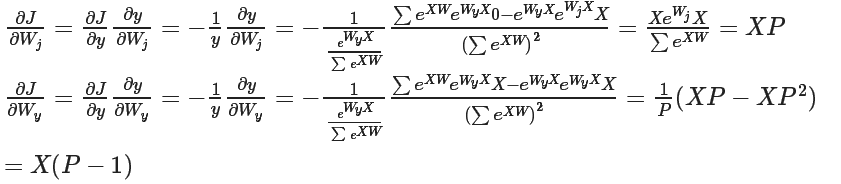
5、根据后向传播,更新权重

6、重复步骤2~4直到模型训练的很好。
二、代码实现
1、数据输入
from argparse import Namespace
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import urllib
# Arguments
args = Namespace(
seed=1234,
data_file="titanic.csv",
train_size=0.75,
test_size=0.25,
num_epochs=100,
)
# Set seed for reproducability
np.random.seed(args.seed)
# Upload data from GitHub to notebook's local drive
url = "https://raw.githubusercontent.com/GokuMohandas/practicalAI/master/data/titanic.csv"
response = urllib.request.urlopen(url)
html = response.read()
with open(args.data_file, 'wb') as f:
f.write(html)
# Read from CSV to Pandas DataFrame
df = pd.read_csv(args.data_file, header=0)
df.head()
输出结果:

2、使用Scikit-learn实现训练
# Import packages
from sklearn.linear_model import SGDClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Preprocessing
def preprocess(df):
# Drop rows with NaN values
df = df.dropna()
# Drop text based features (we'll learn how to use them in later lessons)
features_to_drop = ["name", "cabin", "ticket"]
df = df.drop(features_to_drop, axis=1)
# pclass, sex, and embarked are categorical features
categorical_features = ["pclass","embarked","sex"]
df = pd.get_dummies(df, columns=categorical_features)
return df
# Preprocess the dataset
df = preprocess(df)
df.head()
输出结果:

# Split the data
mask = np.random.rand(len(df)) < args.train_size
train_df = df[mask]
test_df = df[~mask]
print ("Train size: {0}, test size: {1}".format(len(train_df), len(test_df)))
# Separate X and y
X_train = train_df.drop(["survived"], axis=1)
y_train = train_df["survived"]
X_test = test_df.drop(["survived"], axis=1)
y_test = test_df["survived"]
# Standardize the data (mean=0, std=1) using training data
X_scaler = StandardScaler().fit(X_train)
# Apply scaler on training and test data (don't standardize outputs for classification)
standardized_X_train = X_scaler.transform(X_train)
standardized_X_test = X_scaler.transform(X_test)
# Check
print ("mean:", np.mean(standardized_X_train, axis=0)) # mean should be ~0
print ("std:", np.std(standardized_X_train, axis=0)) # std should be 1
输出结果:

# Initialize the model
log_reg = SGDClassifier(loss="log", penalty="none", max_iter=args.num_epochs,
random_state=args.seed)
# Train
log_reg.fit(X=standardized_X_train, y=y_train)
输出结果:

# Probabilities
pred_test = log_reg.predict_proba(standardized_X_test)
print (pred_test[:5])
输出结果:

# Predictions (unstandardize them)
pred_train = log_reg.predict(standardized_X_train)
pred_test = log_reg.predict(standardized_X_test)
print (pred_test)
输出结果:

3、评估
from sklearn.metrics import accuracy_score
# Accuracy
train_acc = accuracy_score(y_train, pred_train)
test_acc = accuracy_score(y_test, pred_test)
print ("train acc: {0:.2f}, test acc: {1:.2f}".format(train_acc, test_acc))
输出结果:
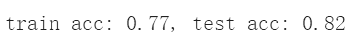
- 混淆矩阵(confusion matrix)
- 理论:

- 代码
import itertools
from sklearn.metrics import classification_report, confusion_matrix
# Plot confusion matrix
def plot_confusion_matrix(cm, classes):
cmap=plt.cm.Blues
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title("Confusion Matrix")
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
plt.grid(False)
fmt = 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], 'd'),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
# Confusion matrix
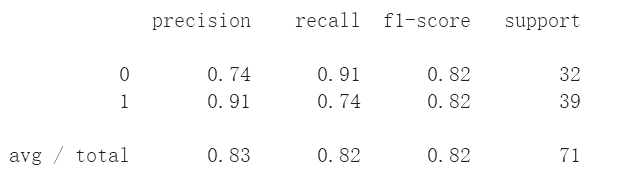
cm = confusion_matrix(y_test, pred_test)
plot_confusion_matrix(cm=cm, classes=["died", "survived"])
print (classification_report(y_test, pred_test))
输出结果:
4、运用在新样本上
# Input your information
X_infer = pd.DataFrame([{"name": "Goku Mohandas", "cabin": "E", "ticket": "E44",
"pclass": 1, "age": 24, "sibsp": 1, "parch": 2,
"fare": 100, "embarked": "C", "sex": "male"}])
X_infer.head()
输出结果:

# Apply preprocessing
X_infer = preprocess(X_infer)
X_infer.head()
输出结果:

# Add missing columns
missing_features = set(X_test.columns) - set(X_infer.columns)
for feature in missing_features:
X_infer[feature] = 0
# Reorganize header
X_infer = X_infer[X_train.columns]
X_infer.head()
输出结果:

# Standardize
standardized_X_infer = X_scaler.transform(X_infer)
# Predict
y_infer = log_reg.predict_proba(standardized_X_infer)
classes = {0: "died", 1: "survived"}
_class = np.argmax(y_infer)
print ("Looks like I would've {0} with about {1:.0f}% probability on the Titanic expedition!".format(
classes[_class], y_infer[0][_class]*100.0))
输出结果: