向量范数
在G.H.Golub和C.F.Van_Loan所著的《矩阵计算》一书中,对向量范数的定义如下:


正则化
在机器学习中,正则化主要用于解决在训练模型的过程中出现的过拟合问题。常见的正则化方法有两种,即L1正则化和L2正则化。其中L1正则化除了可以抑制过拟合现象,还兼有特征选择和增加模型可解释性的作用;L2正则化除了可以抑制过拟合现象,在某些情况下还同时有助于后续的优化计算。L1正则化和L2正则化又被称为L1范数和L2范数,虽然L1范数和L2范数与向量范数中的1范数和2范数类似,但并不完全相同。下面分别对L1正则化和L2正则化进行简单介绍:
L1正则化:
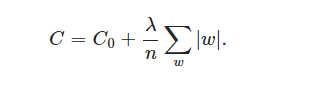
其中,C0代表原始的代价函数,后面那一项就是L1正则化项,它表示权重向量中所有元素绝对值的和除以训练集的样本大小,然后乘以正则项系数λ。λ被称为超参(hyper-parameter),用于平衡模型在训练集上和测试集上的适用性,但一个合适的λ值需要手动调整。关于L1正则化兼有特征选择和增加模型的可解释性的作用,及L2正则化有助于后续的优化计算这两方面的具体内容,可以参考这两篇博文:
https://blog.csdn.net/jinping_shi/article/details/52433975、https://blog.csdn.net/zouxy09/article/details/24971995
L2正则化:
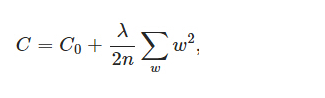
L2正则化即在原始代价函数的基础上L2正则化项,L2正则化项表示权重向量中所有元素的平方和除以两倍训练集的样本大小(除两倍是为了方便后续计算),然后乘以正则项系数λ,与L1正则化项中的λ相同,L2正则化项中的λ也是用于平衡模型在训练集上和测试集上的适用性。
正则化为什么可以抑制过拟合现象?
用下面这张图来说明:
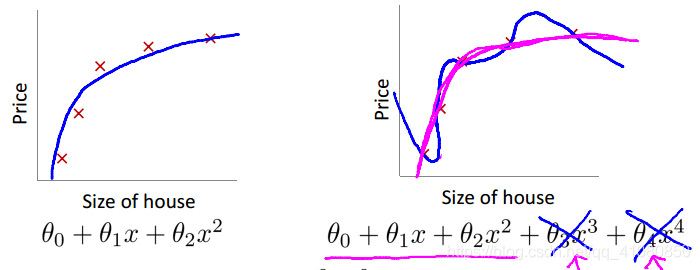
上图右半部分中的蓝色曲线是对训练数据的过拟合。假设theta3和theta4远大于theta0和theta1,当我们给原始代价函数加上正则化项后,可以通过调节参数λ的值,使得最后求解出的参数theta3和theta4接近甚至等于0,从而达到抑制过拟合现象的目的。
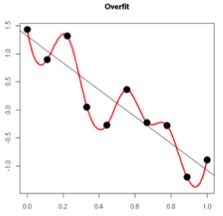
补充说明:出现过拟合现象的时候,拟合函数的系数往往非常大,为什么?答案引自知乎:如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
其他参考:
《矩阵计算》G.H.Golub&C.F.Van_Loan
Andrew Ng机器学习公开课
https://blog.csdn.net/u012162613/article/details/44261657
https://blog.csdn.net/zouxy09/article/details/24972869
https://towardsdatascience.com/regularization-in-machine-learning-76441ddcf99a