LSTM:long short term memory networks(长短时记忆模型)
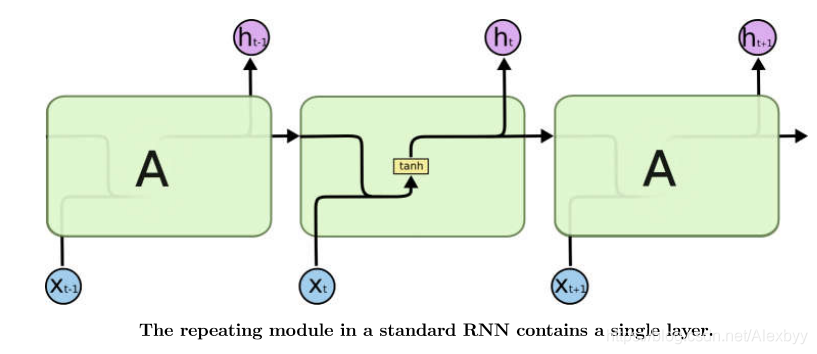
第一幅图是传统的RNN的结构,每个循环单元中只有一层layer。传统的RNN计算公式可以参看此链接
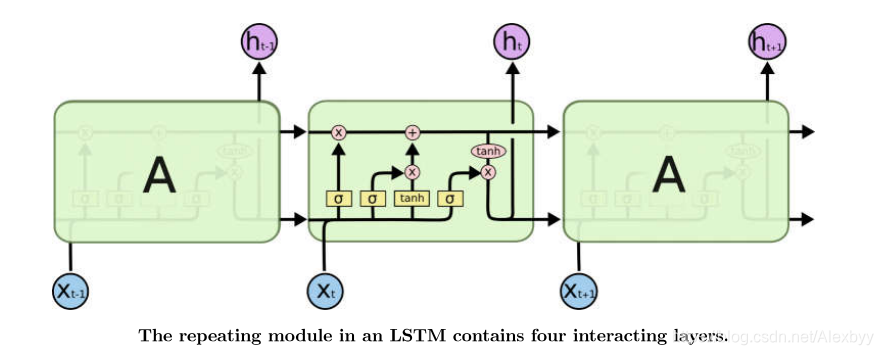
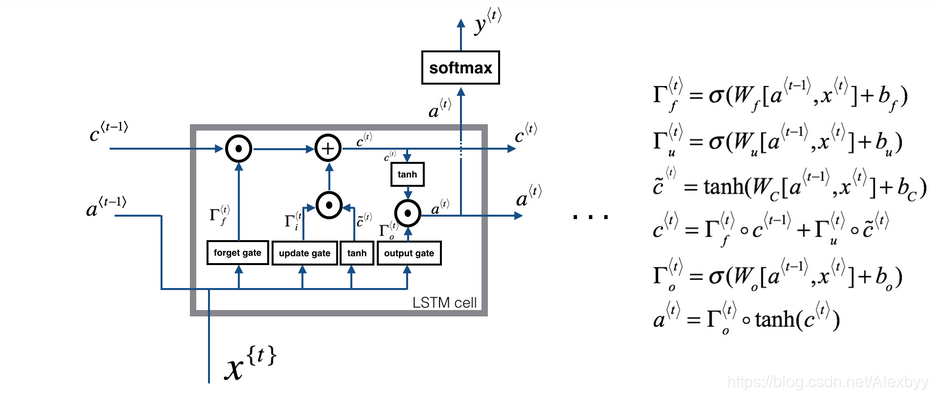
LSTM循环单元包含三个门(gate),分别负责遗忘哪些历史信息(Forget gate)、增加哪些历史信息(updating gate)、以及输出门(Output gate)
第一个门((forget gate layer)):决定我们要扔掉哪些信息
(1)
Γ
f
⟨
t
⟩
=
σ
(
W
f
[
a
⟨
t
−
1
⟩
,
x
⟨
t
⟩
]
+
b
f
)
\Gamma_f^{\langle t \rangle} = \sigma(W_f[a^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_f)\tag{1}
Γ f ⟨ t ⟩ = σ ( W f [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b f ) ( 1 )
c
<
t
−
1
>
c^{<t-1>}
c < t − 1 >
第二个门(updating gate):用来决定我们要增加哪些新的信息
(2)
Γ
u
⟨
t
⟩
=
σ
(
W
u
[
a
⟨
t
−
1
⟩
,
x
{
t
}
]
+
b
u
)
\Gamma_u^{\langle t \rangle} = \sigma(W_u[a^{\langle t-1 \rangle}, x^{\{t\}}] + b_u)\tag{2}
Γ u ⟨ t ⟩ = σ ( W u [ a ⟨ t − 1 ⟩ , x { t } ] + b u ) ( 2 )
(3)
c
~
⟨
t
⟩
=
tanh
(
W
c
[
a
⟨
t
−
1
⟩
,
x
⟨
t
⟩
]
+
b
c
)
\tilde{c}^{\langle t \rangle} = \tanh(W_c[a^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_c)\tag{3}
c ~ ⟨ t ⟩ = tanh ( W c [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b c ) ( 3 )
c
<
t
>
c^{<t>}
c < t >
(4)
c
⟨
t
⟩
=
Γ
f
⟨
t
⟩
∗
c
⟨
t
−
1
⟩
+
Γ
u
⟨
t
⟩
∗
c
~
⟨
t
⟩
c^{\langle t \rangle} = \Gamma_f^{\langle t \rangle}* c^{\langle t-1 \rangle} + \Gamma_u^{\langle t \rangle} *\tilde{c}^{\langle t \rangle} \tag{4}
c ⟨ t ⟩ = Γ f ⟨ t ⟩ ∗ c ⟨ t − 1 ⟩ + Γ u ⟨ t ⟩ ∗ c ~ ⟨ t ⟩ ( 4 )
第三个门(Output gate),该门用来计算
a
<
t
>
a^{<t>}
a < t >
a
<
t
>
a^{<t>}
a < t >
y
y
y
(5)
Γ
o
⟨
t
⟩
=
σ
(
W
o
[
a
⟨
t
−
1
⟩
,
x
⟨
t
⟩
]
+
b
o
)
\Gamma_o^{\langle t \rangle}= \sigma(W_o[a^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_o)\tag{5}
Γ o ⟨ t ⟩ = σ ( W o [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b o ) ( 5 )
(6)
a
⟨
t
⟩
=
Γ
o
⟨
t
⟩
∗
tanh
(
c
⟨
t
⟩
)
a^{\langle t \rangle} = \Gamma_o^{\langle t \rangle}* \tanh(c^{\langle t \rangle})\tag{6}
a ⟨ t ⟩ = Γ o ⟨ t ⟩ ∗ tanh ( c ⟨ t ⟩ ) ( 6 )
参考博客及论文:https://arxiv.org/pdf/1402.1128v1.pdf http://colah.github.io/posts/2015-08-Understanding-LSTMs/