本文本着由浅入深原则介绍LSTM模块结构,使用流程图 梳理公式,保证看完过目不忘,神清气爽。
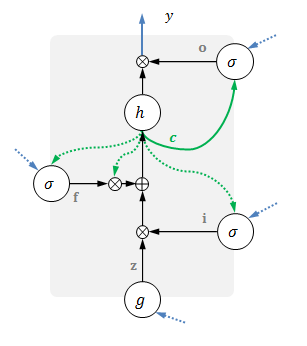
模块结构
核心变量
从宏观上来看,LSTM模块有输入
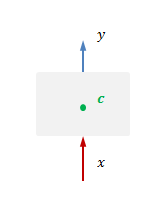
一般用这三个核心变量来描述一个LSTM,记为
入口与门
除了主入口之外,输入
一起进入模块的,还有输出
前一时刻变量用虚线表示。

输入端口和门的结果记为
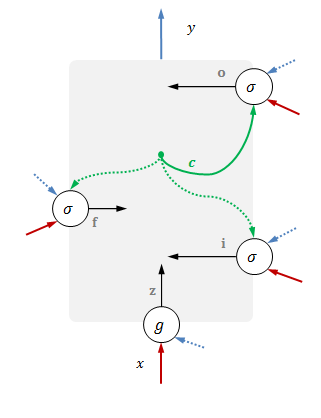
具体表达式如下
| 意义 | 表达式 |
|---|---|
| 数据输入 |
|
| 输入门 |
|
| 遗忘门 |
|
| 输出门 |
|
注意,在需要计算遗忘门时,当前时刻记忆
ct 已经计算完成,所以可以使用最新结果。
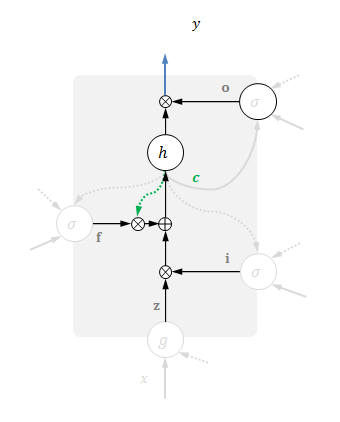
记忆与输出
接下来,可以更新当前记忆:输入门
其中
最后,计算当前输出:当前记忆经过非线性变换
这两步如下图所示,其他部分虚化。
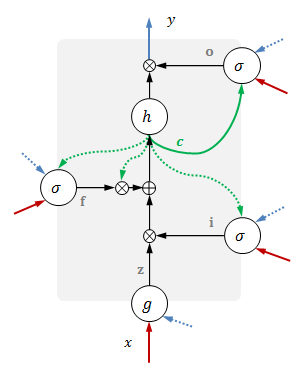
具体实现
完整的LSTM如下图1:
上面提到的非线性激活函数包含如下两种:
方括号
除了输入尺寸为
每个函数具有不同参数
常见变体
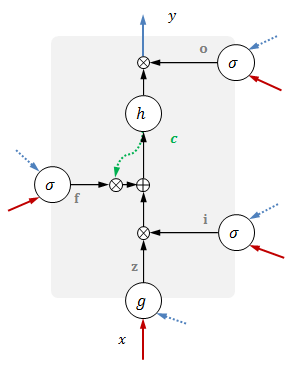
无输入LSTM
可以记做
fast LSTM
记忆
bidirectional LSTM
包含两个输出/隐变量:
其中,前向变量
最终输出往往需要综合两个变量:
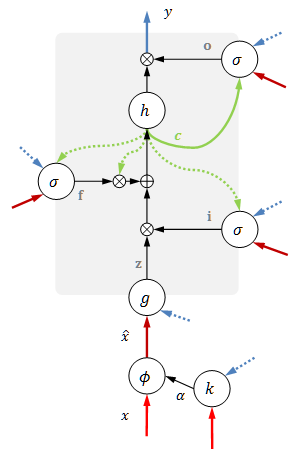
attention LSTM
常简写成
注意力LSTM新增了一个和输入同尺度的注意力权重
其中
用这个权重给原始输入加权:
使用加权的输入替代原来的
- 此图参考了Greff, Klaus, et al. “LSTM: A search space odyssey.” arXiv preprint arXiv:1503.04069 (2015). ↩
- Vinyals, Oriol, Samy Bengio, and Manjunath Kudlur. “Order matters: Sequence to sequence for sets.” arXiv preprint arXiv:1511.06391 (2015). ↩
- Xu, Kelvin, et al. “Show, attend and tell: Neural image caption generation with visual attention.” arXiv preprint arXiv:1502.03044 2.3 (2015): 5. ↩