在学习LSTM的过程中,一直对lstm的内部机制一知半解,网上查找的资料大多千篇一律的翻译稿,大多列列公式了事,并没有做细致深入的解释。于是乎自己最近仔细debug了一遍tensorflow的seq2seq源码,总算是彻底搞清了LSTM的计算流程,下面通过一个图来对LSTM内部的计算流程进行详细解析,先上图:
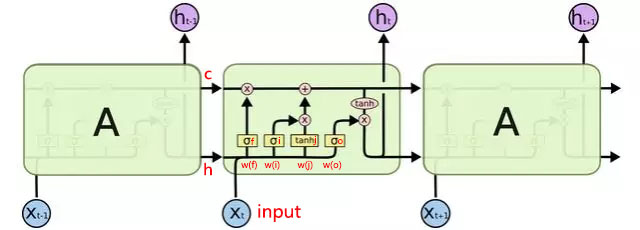
首先看这个广为流传的图,我做了一些注释,大体流程是:
1.input与h进行concat操作,记结果为x
2.x分别于权重矩阵w(f),w(i),w(j),w(o)进行矩阵点乘操作,分别得到结果矩阵f、i、j、o,其中w(f),w(i),w(j),w(o)就是该LSTM细胞的核心权重参数,训练的目的也就是训练这四个权重矩阵参数,至于权重的维度,下面有图能够解释
3.对矩阵f进行sigmod操作即sigmod(f),对矩阵i也进行sigmod操作,即sigmod(i),对矩阵j进行tanh操作,即tanh(j),对矩阵o进行sigmod操作即sigmod(o)
4.计算新的c ,新c=老c*sigmod(f)+(sigmod(i)*tanh(j))
5.计算新的h ,新h=tanh(新c)*sigmod(o)
经过这5个步骤,一次cell计算完毕 得到新的c和新的h,然后将h作为本次的output,将元组(c,h)作为本次的细胞state保存作为下次cell计算的原料。
基于对LSTM大体框架的了解,下面我们通过一个具体的图,来对计算过程中数据的维度变化进行了解,上图:
这个图有点大,可以放大查看,在这里我们对几个参数做预先说明,本图中,embedding_size为512,num_units即隐层的神经个数(决定w(f),w(i),w(j),w(o)等权重参数矩阵的维度)必须与embedding_size一致为512。batch_size设为64。下面对整个图的流程进行解释:
1.首先要将单词经过embedding转换为词向量,即每个单词对应一个1*512的向量,因此最终inputs的维度为(sequence_length,batch_size,512)
2.每次拿出一个单词进行计算,就是拿出inputs(sequence_length)的第一个元素input,维度为[64,512],即一个batch的第一个单词
3.设置初始的state,这个state可以自己初始化,其值为元组形式 (c,h),维度为【64,512】 64为batch_size
4.拿出state中的h,维度为【64,512】与input 【64,512】进行concat得到一个维度为【64,1024】的输入矩阵x
5.x分别与w(f),w(i),w(j),w(o)进行计算,计算的结果必须是512维(num_units),故w(f),w(i),w(j),w(o)四个权重矩阵的维度都必须是【1024,512】的,【64,1024】dot 【1024,512】=【64,512】如下图:
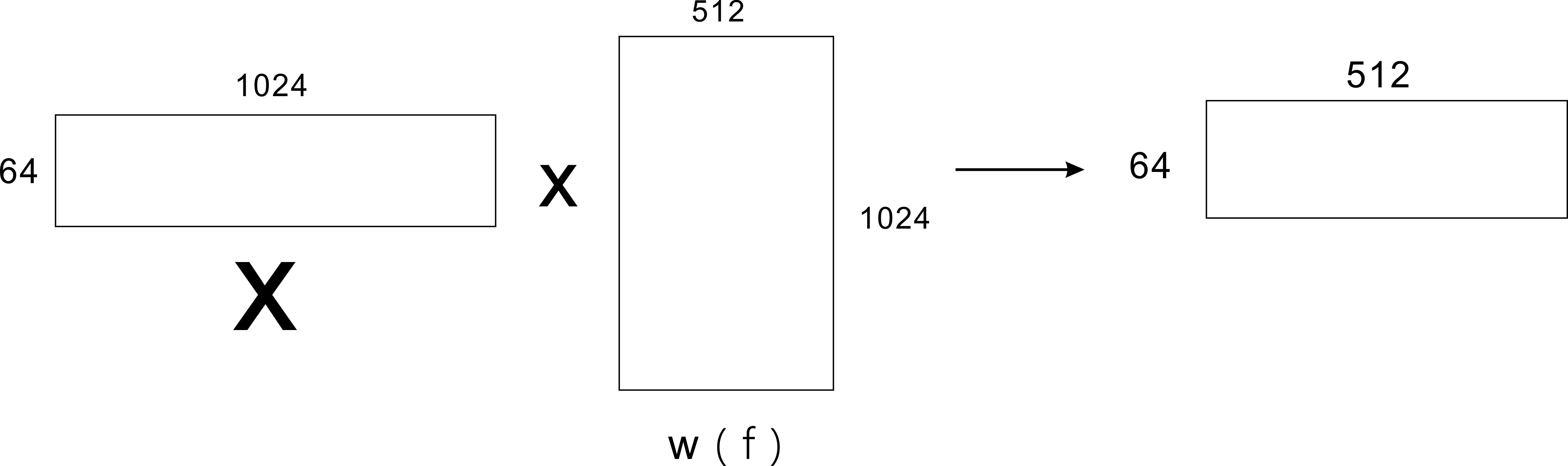
计算的结果f、i、j、o的维度均为【64,512】
6,进行激活操作sigmod(f+b) sigmod(i) tanh(j) sigmod(o),激活操作不改变维度,故而维度都是【64,512】,注意这里对f进行了一个偏置,源码中b=1.0。其作用应该是避免忘记太多内容
7,忘记门,old_c*sigmod(f+b) 对一些信息进行忘记,multiply操作就是矩阵对应元素相乘,由于sigmod操作的结果是大部分值为0,所以起到忘记的作用。结果维度依然是【64,512】
8.记忆门,记忆门采用add操作,结果得到新的c,即new_c=multiply(old_c,sigmod(f+b)) +multiply(sigmod(i),tanh(j)) ,维度依然不改变 【64,512】
9.输出,计算新的h new_h=multiply(sigmod(o),tanh(multiply(c,sigmod(f+b)) +multiply(sigmod(i),tanh(j))) ) 维度【64,512】
至此,一次cell计算完毕。
可以看出,一个LSTM_CELL中最重要的就是四个权重参数矩阵,四个矩阵的维度均为【1024,512】,此处的512就是embedding_size也是num_units,而1024为2*512,即权重参数维度只跟num_units有关 【2*unm_units,num_units】。
这是一层LSTM结构,如果是多层的,就将输出ouput作为下一层的input,其他一样计算。
公式在此就不列出了,网上一片一片。下一篇将对tensorflow的attention机制源码进行解读,tensorflow的attention机制源码与中国blog翻译稿所述略微不同,下篇再做详解