初衷
其实现在评分卡已经深入到我们的生活之中了,在各种小微贷款的申请过程中都可以看到它的身影。对于存在于身边的事自然想要稍微深入了解一下。因此这几篇文章将会对于评分卡建立的整个流程进行一个简单梳理。由于本人是一个初学者,也不是业内人士,很有可能会出现错误,如果大佬发现了问题请指正。
评分卡简介

上图为一个典型评分卡的模型。对于每个变量进行分箱之后给与相应的得分,根据总分来判断放贷。
评分卡一般分为ABC三种。
A卡(Application scorecard)
申请评分卡:对应贷前,利用用户提交的信息,公司掌握的用户信息,第三方信用机构等来进行风险分析。
B卡(Behavior scorecard)
行为评分卡 对应贷中,利用用户拿到贷款后的表现来分析逾期或者违约的概率。
C卡(Collection scorecard)
催收评分卡 对应贷后,对于逾期客户的信息进行分析,从“坏人”中找到可以“商品”。
本次进行A卡分析建模。
数据来源
https://www.lendingclub.com/info/download-data.action
从美国的公司Lending Club提供的数据进行分析。本次分析下载了2018Q1与2018Q2的数据。
数据理解与清洗过程
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
pd.options.display.max_rows = 200
pd.options.display.max_columns = 200
读取数据
#读取数据
df = pd.read_csv('../data/LoanStats_2018Q1.csv', header = 1, low_memory=False)
df1 = pd.read_csv('../data/LoanStats_2018Q2.csv', header = 1, low_memory=False)
df = pd.concat([df,df1],ignore_index = True)
df.info(max_cols = 150)

df.tail()

这里的变量信息十分多,具体在Lending Club官方网站上有相应的解释字典。在这里就不献丑翻译了。
#对于变量类型为obejct的数据进行察看
df.select_dtypes(include = ['O']).info()

#对于变量类型为obejct的数据进行察看
df.select_dtypes(include = ['O']).head()

发现:
1.从这里可以发现,id这一栏数据只有2个非空,而其他的数据最多的只有238636,这两个加起来正好238640也就是总的数据条数,这就说明有可能是这4条变量本身就是空的,需要察看。
2.hardship_flag代表着困难情况,具体里面的数据代表的含义,之后进行分析。
3.verification_status_joint,sec_app_earliest_cr_line,等变量数量太少,不进行分析。(本次分析按照65%的阈值来进行删除)。
4.emp_title,emp_length这两个字段的缺失值较少的字段需要填充。
5.int_rate, revol_util这两个本应该为数字的字段这里是用字符串表示的,为了之后的计算方便,需要更改类型。
6.对于评分卡建立来说,term,grade,sub_grade,issue_d,title均属于贷后数据因此决定删除。但是loan_status对于我们进行数据标记有用处,所以不删除。
#察看id 不为空的字段的信息
df.loc[df.id.notnull()]

可以发现这4条数据中基本没有信息,因此决定删除。
#察看issue_d
df.issue_d.value_counts()
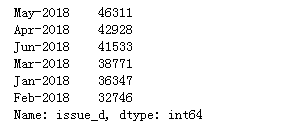
符合本次数据集的时间区段的时间含义,借款发生的时间为1-6月,并且和为238636,说明没有缺失的放贷日期。不过放贷时间对于评分卡构建没有影响,因此决定删除。
#察看hardship字段究竟代表什么意思
df.hardship_flag.value_counts()

从中可以发现,存在困难情况的只有96家,说明数据集中存在困难情况的基本没有,因此可以说明,与困难情况有关系的字段方差过小,在评分卡中毫无区分性,因此不进行分析。
#察看loan_status的内容
df.loan_status.value_counts()

可以看到大部分都是正在还的期限当中或者已经完全付清。在本次评分卡当中,将除了current与fully paid以外的都设置为坏。
#计算样本之比
(sum(df.loan_status == 'Current')+sum(df.loan_status == 'Fully Paid'))/df.shape[0]
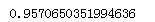
从结果中可以很明显看到数据极度不平衡。
#察看分类数据的情况值
df.select_dtypes(include=['O']).describe().T

发现:(这里截图没法显示完全)
1.职业这一栏的种类有点多,不方便建模,需要进行察看。
2.last_pymnt_d, next_pymnt_d, last_credit_pull_d, initial_list_status, pymnt_plan这几项均属于申请后的信息,与A卡无关,进行删除。
3.application_type, disbursement_method, debt_settlement_flag这几项unique数少,数据分布极度不平衡,并且,对于了解数据集帮助不大,因此决定删除。
4.zip_code与addr_state虽然属于贷前信息,但是按照州地区来进行分类,这对于不了解美国经济的我来说,不现实,决定删除。
5.earliest_cr_line种类过多进行删除。
df.emp_title.value_counts()

emp_title种类实在太多,并且难以分类,因此删除。
#对于变量类型为float的数据进行察看
df.select_dtypes(include = ['float64']).info(max_cols = 150)

其中,loan_amnt, funded_amnt, funded_amnt_inv,int_rate, installment, out_prncp, out_prncp_inv, total_pymnt, total_pymnt_inv, total_rec_prncp, total_rec_int, total_rec_late_fee, last_pymnt_amnt这些变量属于申请后信息(贷中,贷后信息)进行删除。当然loan_amnt也应该属于申请信息,按照金额或许可以分类,本次分析不考虑。
#对于变量类型为float的数据进行察看
df.select_dtypes(include = ['float64']).head()

df.select_dtypes(include = ['float64']).describe().T

发现:
1.member_id,url,desc,mths_since_last_delinq等字段数量较少(小于65%)需要删除。
2.对于其他的数值型变量使用中位数来进行填充。
3.发现delinq_2yrs等变量至少有75%或者以上的数据是相同的,这可能是由于数据是不平衡的,需要查看。
4.policy_code,num_tl_120dpd_2m等变量标准差为零,需要删除。
需要处理的问题归纳
需要处理的问题汇总:
1.有4行的数据毫无意义需要删除。
2.对于困难情况以及其他对于其他的数据量小于65%的字段进行删除。
3.对于term,grade,sub_grade,issue_d,title均属于贷后数据因此决定删除。
4.zip_code,addr_state,earliest_cr_line,emp_title种类过多进行字段进行删除。
5.application_type, disbursement_method, debt_settlement_flag这几项unique数少,数据分布极度不平衡,并且,对于了解数据集帮助不大,因此决定删除。
6.last_pymnt_d, next_pymnt_d, last_credit_pull_d, initial_list_status, pymnt_plan这几项均属于申请后的信息,与A卡无关,进行删除。
7.对于loan_amnt, funded_amnt, funded_amnt_inv, int_rate, installment, out_prncp, out_prncp_inv, total_pymnt, total_pymnt_inv, total_rec_prncp, total_rec_int,total_rec_late_fee,last_pymnt_amnt 这些变量进行删除。
8.emp_length这个字段的缺失值较少的字段的缺失值用unknown来进行填充。
9.int_rate, revol_util这两个本应该为数字的字段这里是用字符串表示的,为了之后的计算方便,需要更改类型。(由于发现int_rate为贷后字段,只对revol_util进行操作)
10.对于缺失较少的字段用中位数进行填充。
11.发现delinq_2yrs等变量至少有75%或者以上的数据是相同的,进行删除。
12.policy_code,num_tl_120dpd_2m等变量标准差为零,需要删除。
13.将loan_status中的类别转化为0和1(1代表不良)。
数据清洗
#复制数据集
df_clean = df.copy()
1.有4行的数据毫无意义需要删除。
#对于无意义的4行进行删除
df_clean = df_clean.loc[df.id.isnull()]
#确认
df_clean.info()
2.对于困难情况以及其他对于其他的数据量小于65%的字段进行删除。
#对于与困难情况相关的字段,以及数据量小于65%的字段进行删除
thr = 0.65
df_clean = df_clean.dropna(thresh = len(df_clean)*thr, axis = 1)
df_clean = df_clean.drop(columns = 'hardship_flag', axis = 1)
3.对于term,grade,sub_grade,issue_d,title均属于贷后数据因此决定删除。
#对于相应字段进行删除
col = ['term','grade','sub_grade','issue_d','title']
df_clean.drop(columns = col, axis = 1, inplace = True)
4.zip_code,addr_state,earliest_cr_line,emp_title种类过多进行字段进行删除。
#对于相应字段进行删除
col = ['zip_code', 'addr_state','earliest_cr_line','emp_title']
df_clean.drop(columns = col, axis = 1, inplace = True)
application_type, disbursement_method, debt_settlement_flag这几项unique数少,数据分布极度不平衡,并且,对于了解数据集帮助不大,因此决定删除。
#对于相应字段进行删除
col = ['application_type', 'disbursement_method', 'debt_settlement_flag']
df_clean.drop(columns = col, axis = 1, inplace = True)
6.last_pymnt_d, next_pymnt_d, last_credit_pull_d, initial_list_status, pymnt_plan这几项均属于申请后的信息,与A卡无关,进行删除。
#对于相应字段进行删除
col = ['last_pymnt_d', 'next_pymnt_d', 'last_credit_pull_d', 'initial_list_status', 'pymnt_plan']
df_clean.drop(columns = col, axis = 1, inplace = True)
7.对于loan_amnt, funded_amnt, funded_amnt_inv, int_rate, installment, out_prncp, out_prncp_inv, total_pymnt, total_pymnt_inv, total_rec_prncp, total_rec_int,total_rec_late_fee,last_pymnt_amnt 这些变量进行删除。
col = ['loan_amnt', 'funded_amnt', 'funded_amnt_inv', 'int_rate', 'installment', 'out_prncp', 'out_prncp_inv', 'total_pymnt', 'total_pymnt_inv', 'total_rec_prncp', 'total_rec_int','total_rec_late_fee','last_pymnt_amnt']
df_clean.drop(columns = col, axis = 1, inplace = True)
8.emp_length这个字段的缺失值较少的字段的缺失值用unknown来进行填充。
#对于emp_title, emp_length的缺失值进行填充
df_clean.emp_length.loc[df_clean.emp_length.isnull()] = 'unknown'
#确认
print(sum(df_clean.emp_length.isnull()))
9.int_rate, revol_util这两个本应该为数字的字段这里是用字符串表示的,为了之后的计算方便,需要更改类型。(由于发现int_rate为贷后字段,只对revol_util进行操作)
#用正则表达式提取数字部分,并且赋值
df_clean.revol_util = df_clean.revol_util.str.extract(r'(\d+\.\d+)')
df_clean.revol_util = df_clean.revol_util.astype('float64')
#确认
print(df_clean.revol_util.dtype)
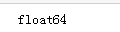
10.对于缺失较少的字段用中位数进行填充。
#用中位数进行填充
for col in df_clean.columns:
if df_clean[col].isnull().any():
df_clean[col].fillna(df_clean[col].median(),inplace=True)
#确认
for col in df_clean.columns:
if df_clean[col].isnull().any():
print('失败')
11.发现delinq_2yrs等变量至少有75%或者以上的数据是相同的,进行删除。
#删除信息量过少的数据(这里按照第三四分位叔等于最小值来判断)
col = []
for i in df_clean.select_dtypes(include=['float64']).columns:
if df_clean[i].quantile(.75) == df_clean[i].min():
col.append(i)
col

df_clean.drop(columns=col,inplace=True)
12.policy_code,num_tl_120dpd_2m等变量标准差为零,需要删除。(发现在11中已经完成)
13.将loan_status中的类别转化为0和1(1代表不良)。
df_clean = df_clean.reset_index(drop = True)
count = 0
df_clean['class'] = df_clean.loan_status.apply(lambda x: '0' if x in ('Current', 'Fully Paid') else '1')
#确认
df_clean['class'].value_counts()

#删除loan_status字段
df_clean.drop(columns = 'loan_status', inplace = True)
df_clean.info()

#写入
df_clean.to_csv('../data/rough_clean_data.csv',index = False)
参考资料:
https://www.experian.co.uk/analytics/risk-analytics/credit-scorecards-custom-analytics/collections-scorecards.html
http://www.statsoft.com/textbook/credit-scoring