数据清洗完整代码
import re
#加载正则表达式库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
from sklearn import model_selection
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
#特征工程处理
train_df_org=pd.read_csv('train.csv')
test_df_org=pd.read_csv('test.csv')
test_df_org['Survived']=0
combined_train_test=train_df_org.append(test_df_org,sort=True)
PassengerId=test_df_org['PassengerId']
combined_train_test['Embarked'].fillna(combined_train_test['Embarked'].mode().iloc[0], inplace=True)
# 为了后面的特征分析,这里我们将 Embarked 特征进行facrorizing
combined_train_test['Embarked'] = pd.factorize(combined_train_test['Embarked'])[0]
# 使用 pd.get_dummies 获取one-hot 编码
emb_dummies_df = pd.get_dummies(combined_train_test['Embarked'], prefix=combined_train_test[['Embarked']].columns[0])
combined_train_test = pd.concat([combined_train_test, emb_dummies_df], axis=1)
#提取筛选性别字段并进行Dummy处理
#---Sex---
# Sex Factorizing
print('# Sex_Dummy...')
combined_train_test['Sex']=pd.factorize(combined_train_test['Sex'])[0]
sex_dummies_df=pd.get_dummies(combined_train_test['Sex'],prefix=combined_train_test[['Sex']].columns[0])
combined_train_test=pd.concat([combined_train_test,sex_dummies_df],axis=1)
# print(combined_train_test.head())
#---Name---
#提取称呼 Title
combined_train_test['Title']=combined_train_test['Name'].map(lambda x:re.compile(", (.*?)\.").findall(x)[0])
#称呼统一化
print('# New_Name_Title...')
title_Dict={}
title_Dict.update(dict.fromkeys(['Capt','Col','Major','Dr','Rev'],'Officer'))
title_Dict.update(dict.fromkeys(['Don','Sir','the Countess','Dona','Lady'],'Royalty'))
title_Dict.update(dict.fromkeys(['Mme','Ms','Mrs'],'Mrs'))
title_Dict.update(dict.fromkeys(['Mlle','Miss'],'Miss'))
title_Dict.update(dict.fromkeys(['Mr'],'Mr'))
title_Dict.update(dict.fromkeys(['Master','Jonkheer'],'Master'))
combined_train_test['Title']=combined_train_test['Title'].map(title_Dict)
# print(combined_train_test)
# print(combined_train_test.groupby(['Title','Survived'])['Survived'].count())
#Title factorizing
print('#Title_factorizing...')
combined_train_test['Title']=pd.factorize(combined_train_test['Title'])[0]
title_dummies_df=pd.get_dummies(combined_train_test['Title'],prefix=combined_train_test[['Title']].columns[0])
combined_train_test=pd.concat([combined_train_test,title_dummies_df],axis=1)
# print(combined_train_test.groupby(['Title','Survived'])['Survived'].count())
#增加名字长度:Name_length
print('# New_Name_length...')
combined_train_test['Name_length']=combined_train_test['Name'].apply(len)
#---Fare---
#缺失值处理:均值
print('# Loss Value Processing : Fare...')
combined_train_test['Fare']=combined_train_test[['Fare']].fillna(combined_train_test.groupby('Pclass').transform(np.mean))
# combined_train_test.info()
#重复值处理:平摊
print('#Duplicate Value Processing:Fare...')
combined_train_test['Group_Ticket']=combined_train_test['Fare'].groupby(by=combined_train_test['Ticket']).transform('count')
combined_train_test['Fare']=combined_train_test['Fare']/combined_train_test['Group_Ticket']
combined_train_test.drop(['Group_Ticket'],axis=1,inplace=True)
# print(combined_train_test.info)
#增加票价等级:Fare_bin(分箱)
print('#Box:Fare...')
combined_train_test['Fare_bin']=pd.qcut(combined_train_test['Fare'],5)
# print(combined_train_test.groupby(['Fare_bin','Survived'])['Survived'].count())
combined_train_test['Fare_bin_id']=pd.factorize(combined_train_test['Fare_bin'])[0]
fare_bin_dummies_df=pd.get_dummies((combined_train_test['Fare_bin_id']).rename(columns=lambda x:'Fare_'+str(x)))
combined_train_test=pd.concat([combined_train_test,fare_bin_dummies_df],axis=1)
combined_train_test.drop(['Fare_bin'],axis=1,inplace=True)
#---Pclass字段---建立PCalss Fare Category
def pclass_fare_category(df,pclass1_mean_fare,pclass2_mean_fare,pclass3_mean_fare):
if df['Pclass']==1:
if df['Fare']<=pclass1_mean_fare:
return 'Pclass1_Low'
else:
return 'Pclass1_High'
elif df['Pclass']==2:
if df['Fare']<=pclass2_mean_fare:
return 'Pclass2_Low'
else:
return 'Pclass2_High'
elif df['Pclass']==3:
if df['Fare']<=pclass3_mean_fare:
return 'Pclass3_Low'
else:
return 'Pclass3_High'
Pclass1_mean_fare=combined_train_test['Fare'].groupby(by=combined_train_test['Pclass']).mean().get([1]).values[0]
Pclass2_mean_fare=combined_train_test['Fare'].groupby(by=combined_train_test['Pclass']).mean().get([2]).values[0]
Pclass3_mean_fare=combined_train_test['Fare'].groupby(by=combined_train_test['Pclass']).mean().get([3]).values[0]
combined_train_test['Pclass_Fare_Category']=combined_train_test.apply(pclass_fare_category,args=(Pclass1_mean_fare,Pclass2_mean_fare,Pclass3_mean_fare),axis=1)
print('# Pclass_Fare_Category...')
# print(combined_train_test.groupby(['Pclass_Fare_Category','Survived'])['Survived'].count())
pclass_level=LabelEncoder() #LabelEncoder的方法
pclass_level.fit(np.array(['Pclass1_Low','Pclass1_High','Pclass2_Low','Pclass2_High','Pclass3_Low','Pclass3_High']))
combined_train_test['Pclass_Fare_Category']=pclass_level.transform(combined_train_test['Pclass_Fare_Category'])
pclass_dummies_df=pd.get_dummies(combined_train_test['Pclass_Fare_Category']).rename(columns=lambda x:'Pclass_'+str(x))
combined_train_test=pd.concat([combined_train_test,pclass_dummies_df],axis=1)
# print(combined_train_test)
#新增字段Family_Size
def family_size_category(family_size):
if family_size<=1:
return 'Single'
elif family_size<=4:
return 'Small_Family'
else:
return 'Large_Family'
#Parch和SibSp字段处理
print('# New_Family_Size...')
combined_train_test['Family_Size']=combined_train_test['Parch']+combined_train_test['SibSp']+1
combined_train_test['Family_Size_Category']=combined_train_test['Family_Size'].map(family_size_category)
le_family=LabelEncoder()
le_family.fit(np.array(['Single','Small_Family','Large_Family']))
combined_train_test['Family_Size_Category']=le_family.transform(combined_train_test['Family_Size_Category'])
family_size_dummies_df=pd.get_dummies(combined_train_test['Family_Size_Category'],prefix=combined_train_test[['Family_Size_Category']].columns[0])
combined_train_test=pd.concat([combined_train_test,family_size_dummies_df],axis=1)
# print(combined_train_test)
#缺失值处理:RandomForestRegression模型填充缺失值
print('# Loss Value Processing:Age...')
age_df=combined_train_test[['Age','Embarked','Sex','Title','Name_length','Family_Size','Family_Size_Category','Fare','Fare_bin_id','Pclass']]
age_df_notnull=age_df.loc[(combined_train_test['Age'].notnull())]
age_df_isnull=age_df.loc[(combined_train_test['Age'].isnull())]
X=age_df_notnull.values[:,1:]
Y=age_df_notnull.values[:,0]
#Age字段处理
RFR=RandomForestRegressor(n_estimators=1000,n_jobs=1 ) #1000个决策树
RFR.fit(X,Y)
predictAges=RFR.predict(age_df_isnull.values[:,1:]) #输入age字段为空的,除age字段之外的数据
combined_train_test.loc[combined_train_test['Age'].isnull(),['Age']]=predictAges
# print(age_df_isnull)
# print(combined_train_test)
#Ticket字段处理
print('# factorize:Ticket...')
combined_train_test['Ticket_Letter']=combined_train_test['Ticket'].str.split().str[0]
combined_train_test['Ticket_Letter']=combined_train_test['Ticket_Letter'].apply(lambda x:'0' if x.isnumeric() else x)
combined_train_test['Ticket_Letter']=pd.factorize(combined_train_test['Ticket_Letter'])[0]
print(combined_train_test['Ticket_Letter'])
print(combined_train_test)
#Cabin字段处理
print('# Loss Value Processing:Cabin...')
combined_train_test.loc[combined_train_test.Cabin.isnull(),'Cabin']='0'
combined_train_test['Cabin']=combined_train_test['Cabin'].apply(lambda x:0 if x=='0' else 1)
# print(combined_train_test['Cabin'])
#Age和fare字段值的正则化
print('# Normalization:Age&fare...')
scale_age_fare=preprocessing.StandardScaler().fit(combined_train_test[['Age','Fare','Name_length']])
combined_train_test[['Age','Fare','Name_length']]=scale_age_fare.transform(combined_train_test[['Age','Fare','Name_length']])
#保存清洗组合后数据
print("-"*40)
# combined_train_test.info()
#保存清洗组合后数据
print("-"*40)
print('# save to csv...')
combined_train_test.to_csv('3_combined_train_test.csv',index=False)
sklearn分析建模库
Multiclass classification多类分类器
一个分类任务需要对多余两个类的数据进行分类。多类分类假设每一个样本有且仅有一个标签

Multilabel classification 多标签分类器
给每一个样本分配一系列标签,可以被认为是预测不相互排斥的数据点的属性

Multioutput regress 多输出分类器
为每个样本分配一组目标值,这可以认为是预测每一个样本的多个属性。

示例:船舱等级/性别与生存率的关系
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestRegressor
#源数据
train_data=pd.read_csv('train.csv')
test_data=pd.read_csv('test.csv')
#---性别与是否生存的关系 Sex---
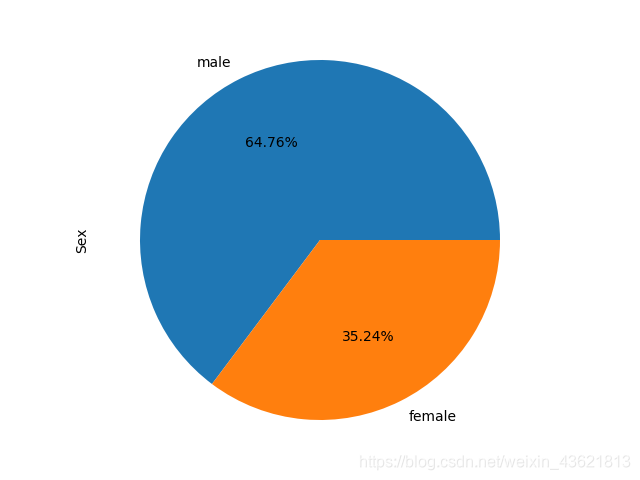
train_data['Sex'].value_counts().plot.pie(autopct='%1.2f%%')
# plt.savefig('images/2_FeatureRelationSex1.png')
print('# 性别与是否生存的关系')
print(train_data.groupby(['Sex','Survived'])['Survived'].count())
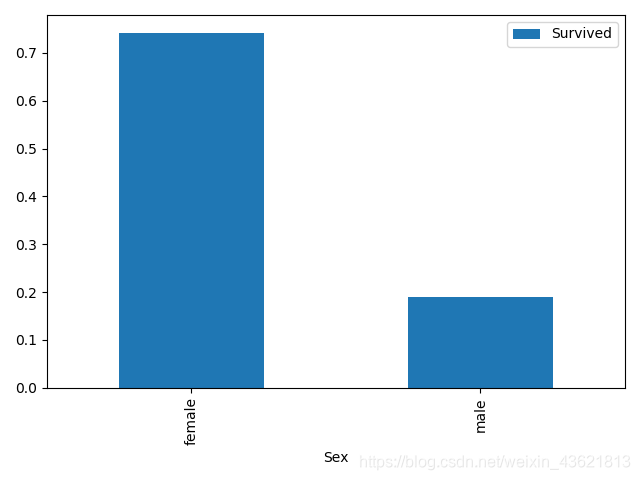
train_data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar()
# plt.savefig('images/2_FeatureRelationSex.png')
train_data.groupby(['Sex','Survived'])['Survived'].describe().reset_index().to_csv('2_FeatureRelationSex.csv')
plt.show()
#---船舱等级和生存与否的关系 Pclass---
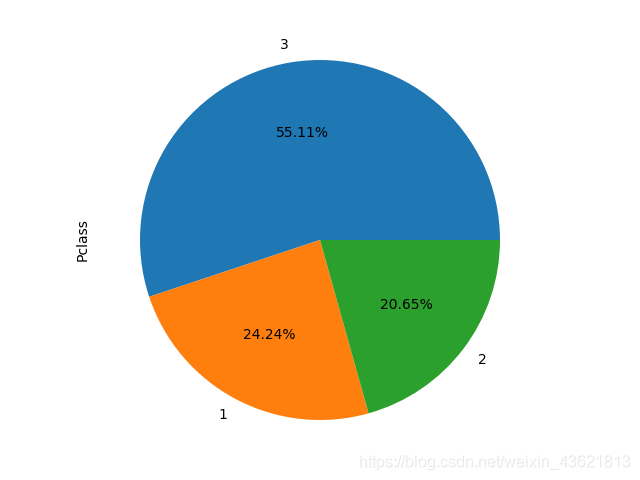
train_data['Pclass'].value_counts().plot.pie(autopct='%1.2f%%')
# plt.savefig('images/2_FeatureRelationPclass1.png')
print('# 船舱等级和生存与否的关系')
print(train_data.groupby(['Pclass','Survived'])['Pclass'].count())
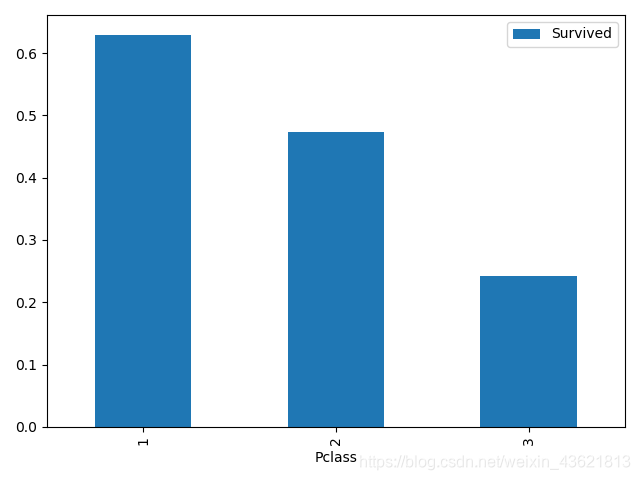
train_data[['Pclass','Survived']].groupby(['Pclass']).mean().plot.bar()
# plt.savefig('images/2_FeatureRelationPclass.png')
plt.show()
plt.close()
结果:
#性别与是否生存的关系
Sex Survived
female 0 81
1 233
male 0 468
1 109
Name: Survived, dtype: int64
#船舱等级和生存与否的关系
Pclass Survived
1 0 80
1 136
2 0 97
1 87
3 0 372
1 119
Name: Pclass, dtype: int64
示例:sklearn决策树分析
DecisionTreeClassifier有两个向量输入:
X,大小为[n_sample,n_feature],存放训练样本
Y,值为整形,大小为[n_sample],存放训练样本的分类标签
tree.data:前面都为X,最后一列为Y
import time
from sklearn import metrics #引入评估
from sklearn import tree #加载树
from sklearn.externals import joblib #保存/还原模型
import numpy as np
raw_data="tree.data"
#load the CSV file as a numpy matrix
dataset=np.loadtxt(raw_data,delimiter=',') #分隔符为逗号
# separate the data from the target attributes
x=dataset[:,0:8]
y=dataset[:,8]
#训练集合
X_train=dataset[0:500,0:8]
y_train=dataset[0:500,8]
#测试集合
X_test=dataset[500:,0:8]
y_test=dataset[500:,8]
print('\n调用scikit的tree.DecisionTreeClassifier()')
model=tree.DecisionTreeClassifier(min_samples_leaf=2) #叶子节点最少样本数为2,超过2个样本才划分
start_time=time.time()
model.fit(X_train,y_train)
print("training took %fs!" % (time.time()-start_time))
joblib.dump(value=model,filename='Decisiontree.model') #保存模型
expected=y_test #真实值
predicted=model.predict(X_test) #预测值
print(metrics.confusion_matrix(expected,predicted)) #混淆矩阵
print(metrics.classification_report(expected,predicted))
结果:
调用scikit的tree.DecisionTreeClassifier()
training took 0.007018s!
[[149 33]
[ 36 50]]
precision recall f1-score support
0.0 0.81 0.82 0.81 182
1.0 0.60 0.58 0.59 86
accuracy 0.74 268
macro avg 0.70 0.70 0.70 268
weighted avg 0.74 0.74 0.74 268
