通过SegNet 来实现图片的分割
TensorRT下载地址:https://developer.nvidia.com/nvidia-tensorrt-download
TesnsoRT介绍文档:https://devblogs.nvidia.com/tensorrt-3-faster-tensorflow-inference/
TensorRT开发者指南:http://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html
TensorRT样例代码:http://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#samples
本教程重点提到的深度学习的功能是图像的分割。图像分割的最基本原理也是图像识别,但是它是基于像素级别的图像识别而不是对于整张图片的识别。它是通过一个对已经训练好的ImageNet识别模型的卷积化来实现的,他将其转化成一个能将每一个像素都标记的全卷积分割模型。分割对于环境感知和避碰非常有用,它可以对每个场景中的许多不同的潜在对象进行密集的每像素分类,包括场景前景和背景。

segNet 实例可以接受一个2维图像的输入,并且输出一个每一个像素都分类过得图像。每个像素都对应一个识别的目标类别。
注意:您可以查看semantic segmentation来获取更多地关于图像分割的背景知识。
Downloading Aerial Drone Dataset
作为图像分割的一个例子,我们将使用一个将地面与天空分开的空中无人驾驶飞机数据集。该数据集在第一人称视角(FPV)中模拟无人机的位置,并训练一个网络,作为一个自动驾驶仪,引导其感知的地形。
要下载和解压缩数据集,请从运行DIGITS服务器的主机PC上运行以下命令:
-
$ wget --no-check-certificate https://nvidia.box.com/shared/static/ft9cc5yjvrbhkh07wcivu5ji9zola6i1.gz -O NVIDIA-Aerial-Drone-Dataset.tar.gz扫描二维码关注公众号,回复: 5012815 查看本文章
-
HTTP request sent, awaiting response... 200 OK -
Length: 7140413391 (6.6G) [application/octet-stream] -
Saving to: ‘NVIDIA-Aerial-Drone-Dataset.tar.gz’ -
NVIDIA-Aerial-Drone-Datase 100%[======================================>] 6.65G 3.33MB/s in 44m 44s -
2017-04-17 14:11:54 (2.54 MB/s) - ‘NVIDIA-Aerial-Drone-Dataset.tar.gz’ saved [7140413391/7140413391] -
$ tar -xzvf NVIDIA-Aerial-Drone-Dataset.tar.gz
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
数据集包括从无人机平台飞行中捕获的剪辑,但是我们将在本教程中关注的片段是FPV/SFWA。接下来,我们会为之后的训练模型在DIGITS上创建一个数据集。
Importing the Aerial Dataset into DIGITS
首先,用浏览器连接到你的DIGITS服务器,然后在右上角的New Dataset中选择Segmentation:
在数据创建界面,按照下面的内容设置您的变量
• Feature image folder: NVIDIA-Aerial-Drone-Dataset/FPV/SFWA/720p/images
• Label image folder: NVIDIA-Aerial-Drone-Dataset/FPV/SFWA/720p/labels
• set % for validation to 1%
• Class labels: NVIDIA-Aerial-Drone-Dataset/FPV/SFWA/fpv-labels.txt
• Color map: From text file
• Feature Encoding: None
• Label Encoding: None
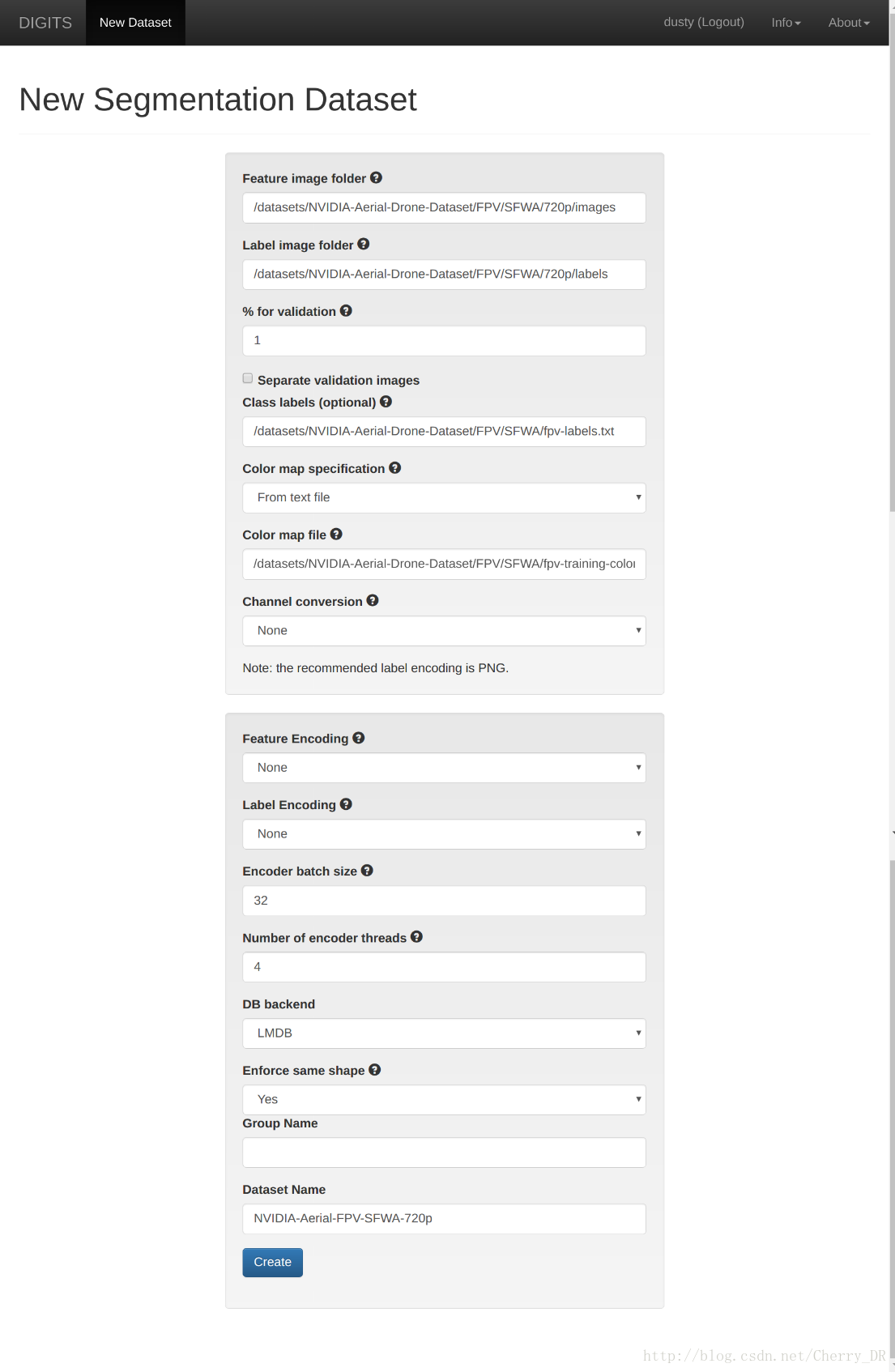
给您的数据库起个名字,然后点击Create按钮。接下来我们就要创建新的模型然后训练了。
Generating Pretrained FCN-Alexnet
全卷积网络(Fully Convolutional Network,FCN)AlexNet是我们接下来要利用DIGITS和TensorRT使用的网络模型。查看Parallel ForAll 您可以了解到更多关于卷积的细节。DIGITS5当中的新的特性就是支持图像分割的数据创建和模型训练。DIGITS中包含了一个脚本,它将Alexnet模型转换为FCN-Alexnet。然后将该基础模型用作在自定义数据集上训练新的FCN-Alexnet分割模型的预先训练的基础
在DIGITS/examples/semantic-segmentation文件夹下面,执行net_surgery 来获得预训练的FCN-Alexnet模型:
-
$ cd DIGITS/examples/semantic-segmentation -
$ ./net_surgery.py -
Downloading files (this might take a few minutes)... -
Downloading https://raw.githubusercontent.com/BVLC/caffe/rc3/models/bvlc_alexnet/deploy.prototxt... -
Downloading http://dl.caffe.berkeleyvision.org/bvlc_alexnet.caffemodel... -
Loading Alexnet model... -
... -
Saving FCN-Alexnet model to fcn_alexnet.caffemodel
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Training FCN-Alexnet with DIGITS
当之前的数据集导入成功后,返回到DIGITS的主页。选择Models里面右上角的New Model下面的Segmentation:
When the previous data import job is complete, return to the DIGITS home screen. Select the Models tab and choose to create a new Segmentation Model from the drop-down:
在模型创建的页面,选择之前我们创建好的数据集。
• Subtract Mean 设置为None
• Base learning Rate 设置为0.0001
• 选择Custom Network,并选用Caffe平台
• 复制FCN-Alexnet prototxt中的内容到文本框内。
• 最后设置net_surgery 生成的预训练的模型DIGITS/examples/semantic-segmentation/fcn_alexnet.caffemodel
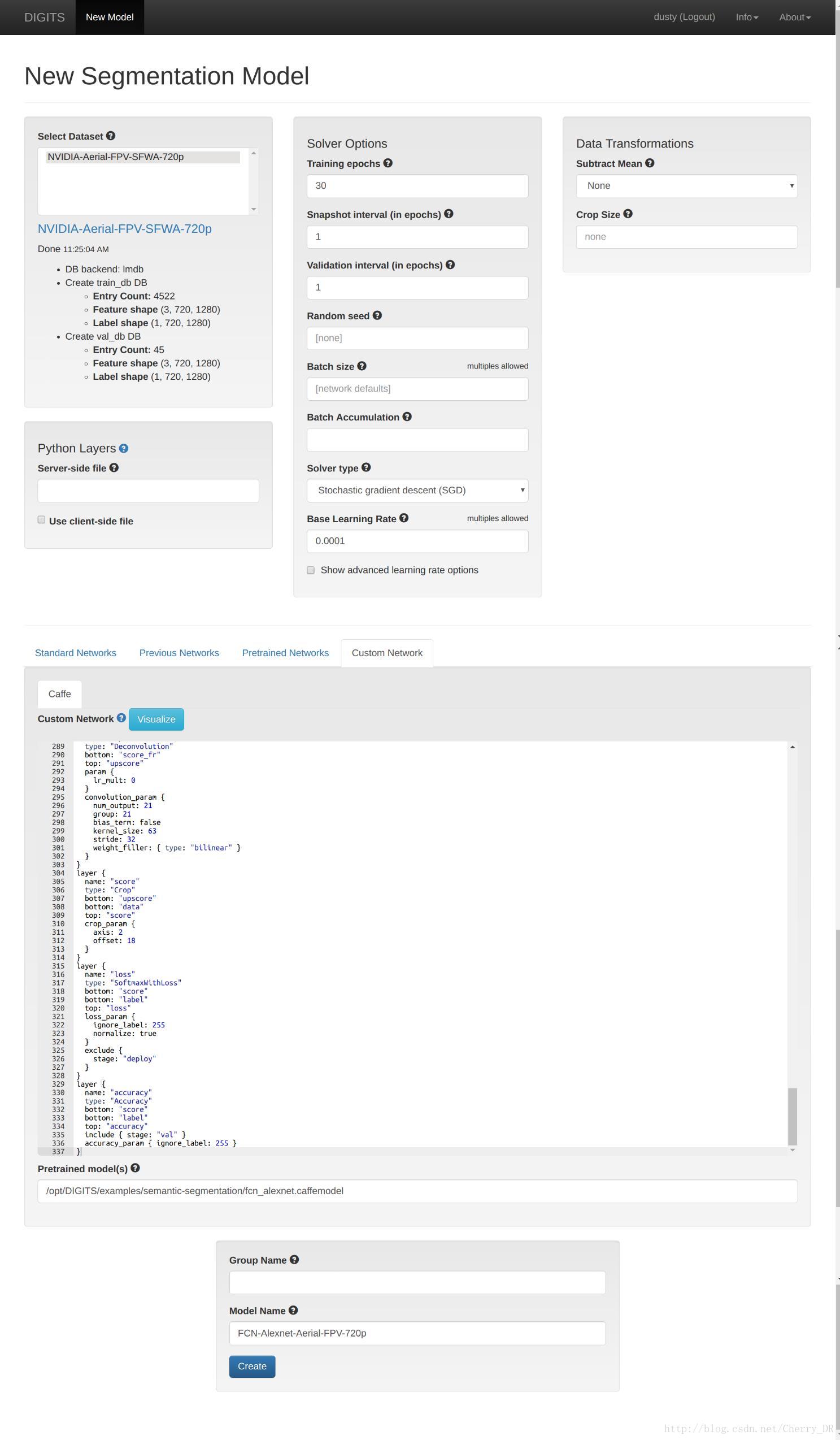
最后,给你训练的模型起一个名字并点击下面的Create按钮。在5个epochs之后,准确率的曲线开始慢慢上升,你的模型也就可以用了(当然,准确率越高,最后的效果越好):
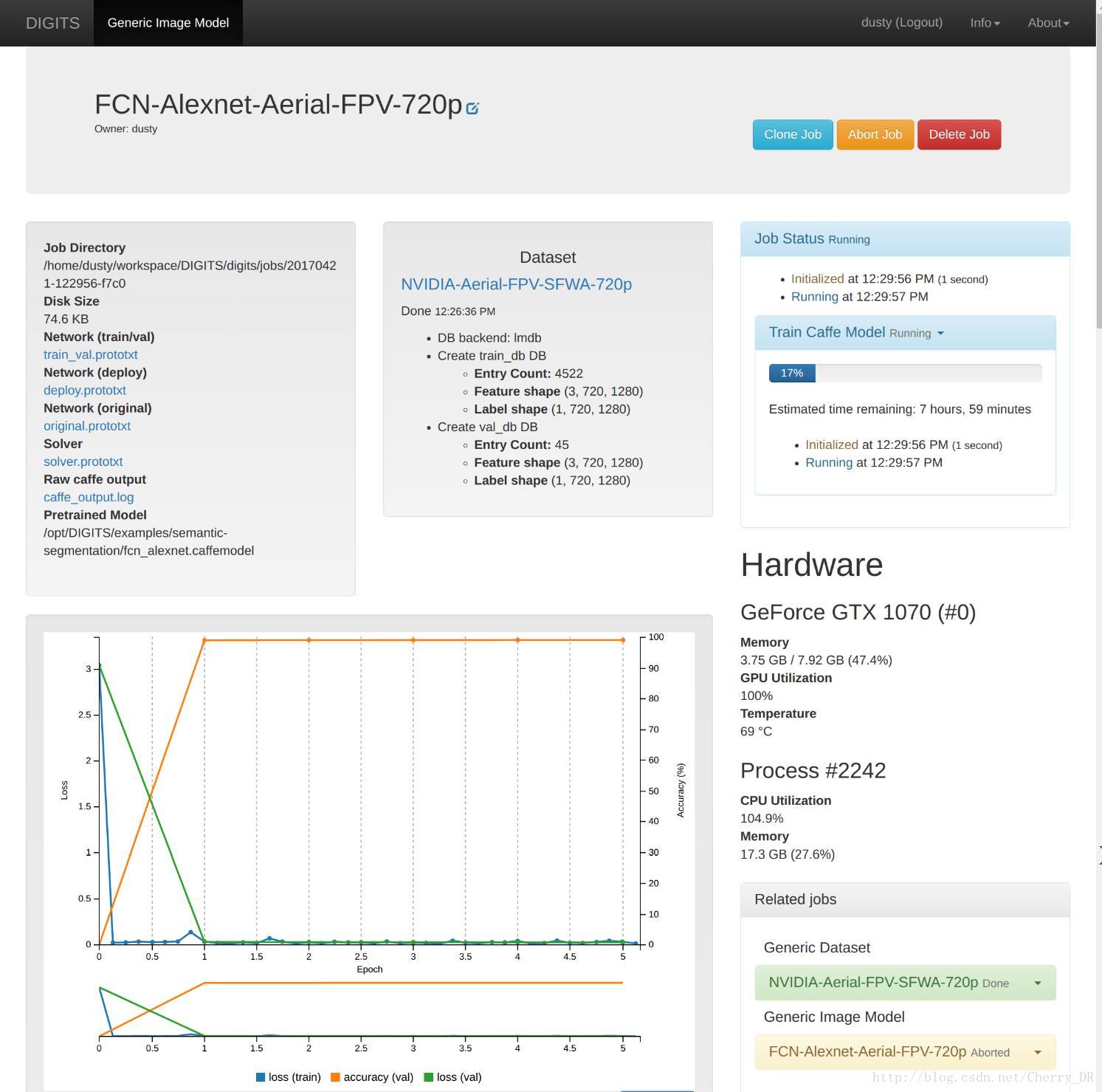
这是,我们就可以测试一下我们的模型了。
Testing Inference Model in DIGITS
在把训练好的模型传到Jetson上前,我们可以再DIGITS里面测试一下,就像之前的一样,在Select Visualization Method下面选择Image Segmentation。然后在下面的Image Path里面输入你想要测试的图片的路径(在本例中我们用的是example /NVIDIA-Aerial-Drone-Dataset/FPV/SFWA/720p/images/0428.png):
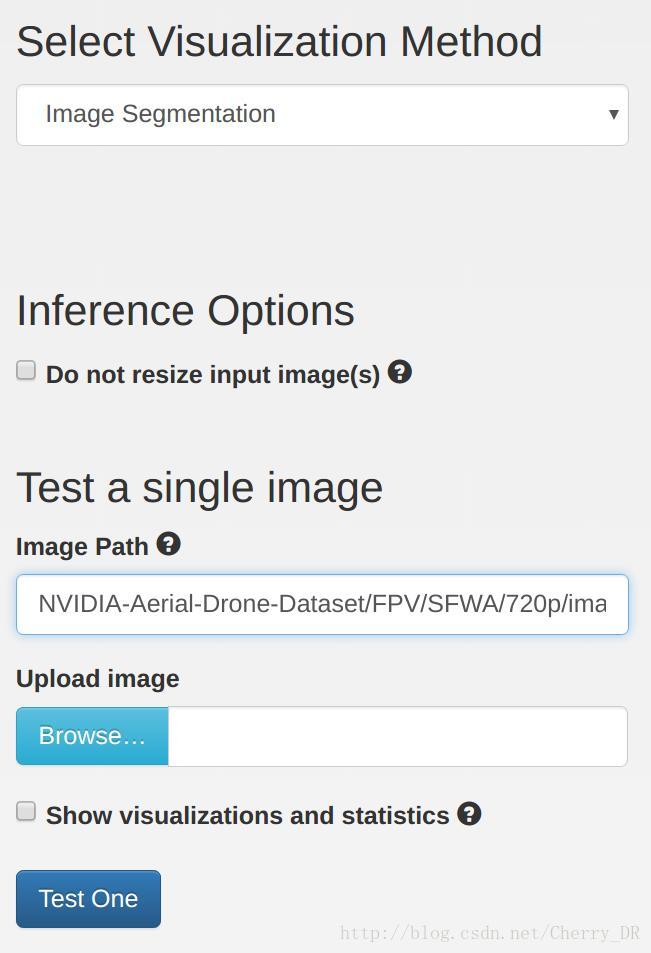
然后单击Test one 你就会看到下面的效果
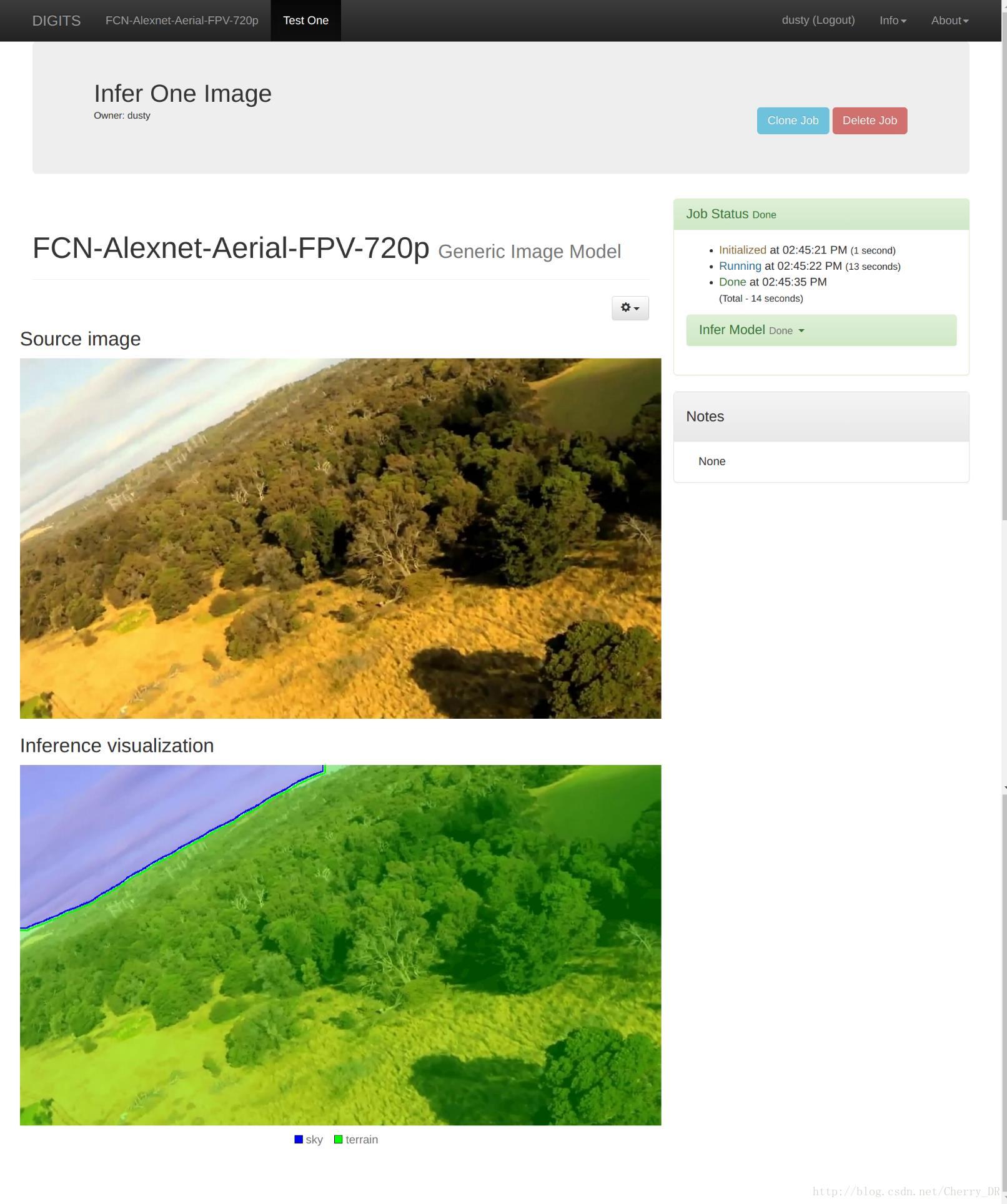
接下来,下载并解压训练好的模型到Jetson
FCN-Alexnet Patches for TensorRT
在FCN-Alexnet里面存在一些不太重要的网络层,而且TensorRT不支持它们,所以我们需要将这些网络层从deploy.prototxt
在deploy.prototxt 的末尾处,删除deconv 和 crop层:
-
layer { -
name: "upscore" -
type: "Deconvolution" -
bottom: "score_fr" -
top: "upscore" -
param { -
lr_mult: 0.0 -
} -
convolution_param { -
num_output: 21 -
bias_term: false -
kernel_size: 63 -
group: 21 -
stride: 32 -
weight_filler { -
type: "bilinear" -
} -
} -
} -
layer { -
name: "score" -
type: "Crop" -
bottom: "upscore" -
bottom: "data" -
top: "score" -
crop_param { -
axis: 2 -
offset: 18 -
} -
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
还有,在deploy.prototxt的第24行将pad: 100 改成pad: 0。最后从航空数据集中复制fpv-labels.txt 和fpv-deploy-colors.txt 到你的Jetson中模型的文件夹。你的FCN-Alexnet模型就在TensorRT中配置完成了。这样,我们就可以在Jetson中运行一下试试了。
Running Segmentation Models on Jetson
您可以运行下面的命令行程序来测试一下您的分割网络模型。
首先,为了方便起见,您最好把模型路径设置到$NET 变量中:
-
$ NET=20170421-122956-f7c0_epoch_5.0 -
$ ./segnet-console drone_0428.png output_0428.png \ -
--prototxt=$NET/deploy.prototxt \ -
--model=$NET/snapshot_iter_22610.caffemodel \ -
--labels=$NET/fpv-labels.txt \ -
--colors=$NET/fpv-deploy-colors.txt \ -
--input_blob=data \ -
--output_blob=score_fr
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这些命令将会运行repo中下载好的我们训练好的模型。

除了本教程提到的数据集之外,您还可以利用其他的数据集来训练Cityscapes, SYNTHIA, 和 Pascal-VOC.