一、训练集、测试集以及交叉验证集
1、训练集(模型训练)
2、测试集(模型评估)
- 测试集的主要目的是正确评估分类器的性能,一般我们要确保
测试集和交叉验证集的数据来自同一分布
3、交叉验证集(模型选择)
不直接使用测试集的原因:确保我们选择出来的模型没有见过测试数据,即测试数据集没有参与模型选择的过程。
交叉验证的基本思想:重复的使用数据(许多实际应用中数据是不充足的),把给定的数据进行切分,将切分的数据集分为训练集和验证集,在此基础上反复进行训练、测试以及模型选择
(I)、简单交叉验证(又称 hold-out)
- 随机的将数据集按比例(eg:7:3)分为训练集和验证集,然后用训练集在各种条件下(例如,
不同超参数)训练模型,从而得到不同模型,在验证集上评价各个模型的测试误差,选出测试误差最小的模型 - 主要缺陷:由于只使用了 70% 数据训练模型,原数据中一些重要的信息可能被忽略。
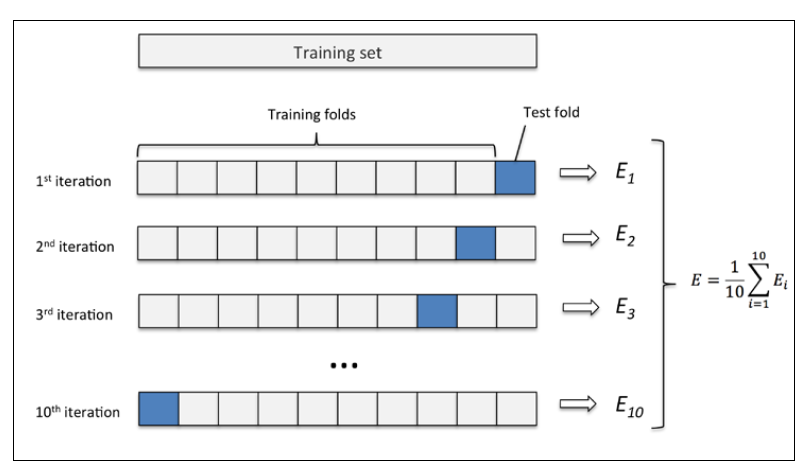
(II)、k 折交叉验证( k-fold cross validation)
- 首先,随机的将数据集分为 (通常取10)个大小相同的子集,每个子集尽可能保持数据分布的一致性(对于分类问题可采用分层采样,保持原始数据集的类别比例)
- 然后,每次用 个子集的并集作为训练集,余下的那个子集作为测试集,这样就可以得到 组训练/测试集,从而进行 次训练和测试,返回的是这 个测试结果的均值
- 最后,将这一过程对所有可能的 种选择(不同的模型)重复进行,选出 次测评中平均测试误差最小的模型
- 10 折交叉验证示意图如下所示,注意:
次
折交叉验证总共进行了
次训练/测试。
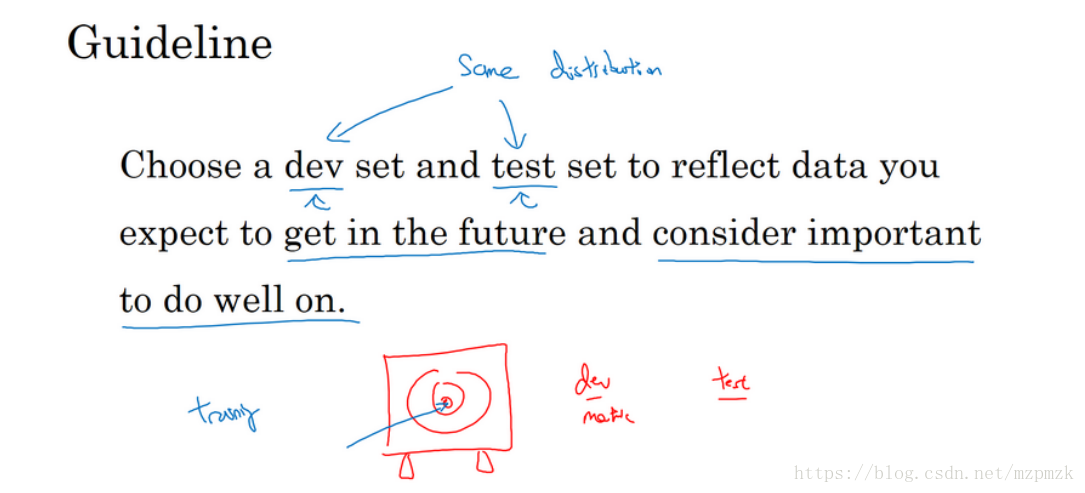
4、验证集和测试集大小的选择
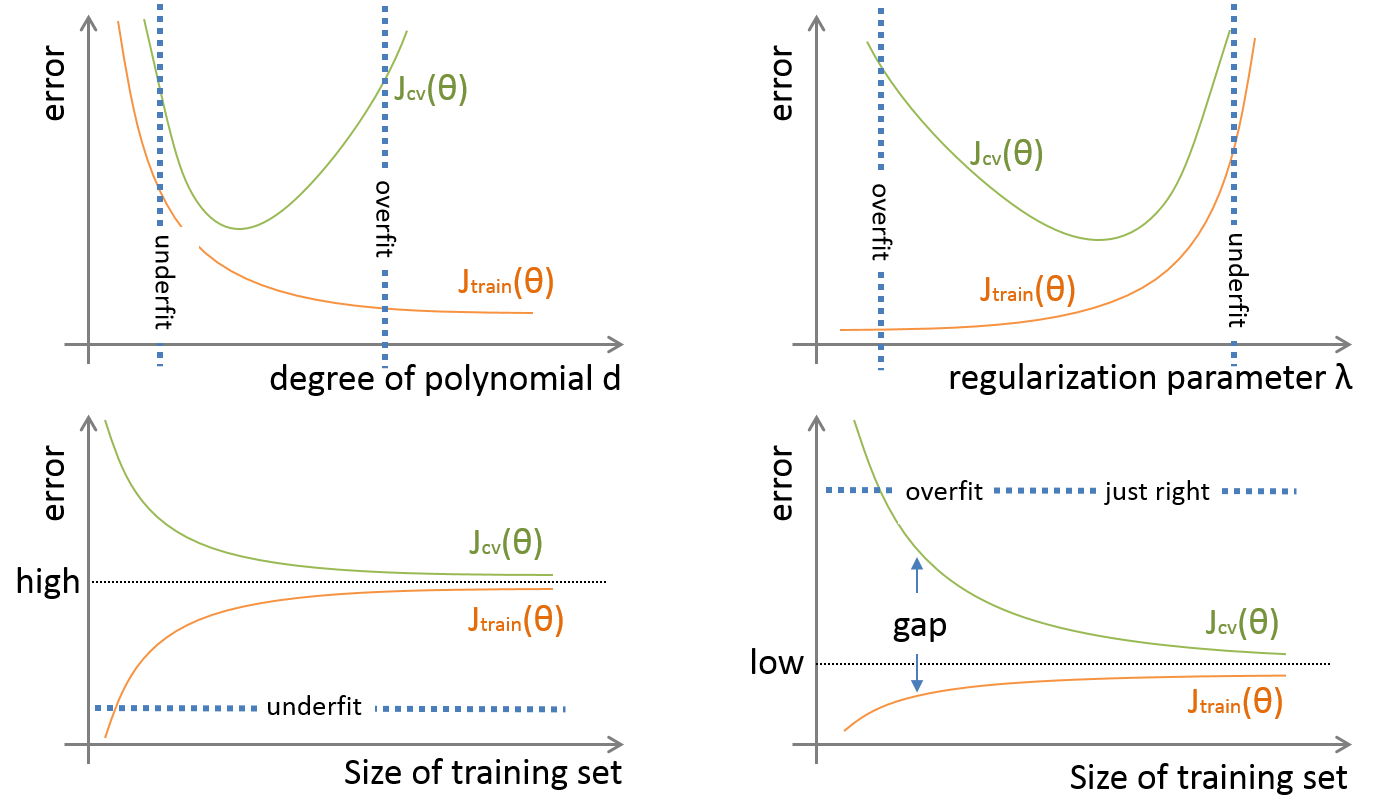
二、如何判断一个模型是过拟合还是欠拟合?
- 特征变量只有一个的时候,可以通过画出决策函数的图像,然后观察拟合的效果
- 通过画出
training error和cross validation error关于模型超参数的 error 曲线图来判断 - 通过画出学习曲线(error-VS-training set size)来识别过拟合 or 欠拟合 (考量增加数据量会不会改善模型效果)
- 以上分析的前提都是假设
基本误差很小,训练集和验证集数据来自相同分布
三、过拟合和欠拟合的解决方案
1、解决过拟合问题:降低模型的复杂度
- 获取更多训练数据,(
过拟合的主要原因是:模型太努力地去记住训练样本的分布状况,而加大样本量,可以使得训练集的分布更加具备普适性,噪声对整体的影响下降) - 增加正则化程度 (在不损失信息的情况下,最有效的缓解过拟合现象的方法)
Dropout & BN(Batch Normalization)Early Stopping
2、解决欠拟合问题:增加模型的复杂度
- 使用更复杂的模型(比如:使用非线性的核函数,增加模型的拟合能力),此时增加数据可能就没有什么用了
- 减少正则化程度
3、经验风险最小化和结构风险最小化
- 经验风险最小化(empirical risk minimization,ERM):我们计算的是在训练集上的经验风险,因此我们的学习准则是
找到一组参数使得经验风险最小。 - 结构风险最小化(structure risk minimization,SRM):为了解决过拟合问题,在经验风险最小化的基础上
加入正则化来限制模型能力,使其不要过度的最小化经验风险。这种准则就是结构风险最小化准则。
四、L1&L2 正则化
- 正则化是为了降低模型的复杂度(主要通过降低参数绝对值的大小),从而避免模型过分拟合训练数据(包括
噪声与异常点)。模型复杂体现在两个方面,一是参数过多,二是参数值过大。参数值过大会导致导数非常大,那么拟合的函数波动就会非常大。 -
正则化
- 让特征获得的权重稀疏化(W 向 0 靠),也就是对结果影响不那么大的特征,干脆就拿不着权重,非零那部分权重可起到选择重要特征的作用。
L2_regularization_cost = (np.sum(np.square(W1)) + np.sum(np.square(W2)) + ...) * lambd
cost = cross_entropy_cost + L2_regularization_cost-
正则化
- 尽量打散权重到每个特征维度上,不让权重集中在某些维度上,出现权重特别高的特征。
- It relies on the assumption that a model with small weights is simpler than a model with large weights. This leads to a smoother model in which the output changes more slowly as the input changes.
# 在机器学习中被称为岭回归(ridge regression)
L2_regularization_cost = (np.sum(np.square(W1)) + np.sum(np.square(W2)) + ...) * lambd / (2 * m)
cost = cross_entropy_cost + L2_regularization_cost关于正则化为什么能够防止过拟合?可以参考博文 1 和 2。
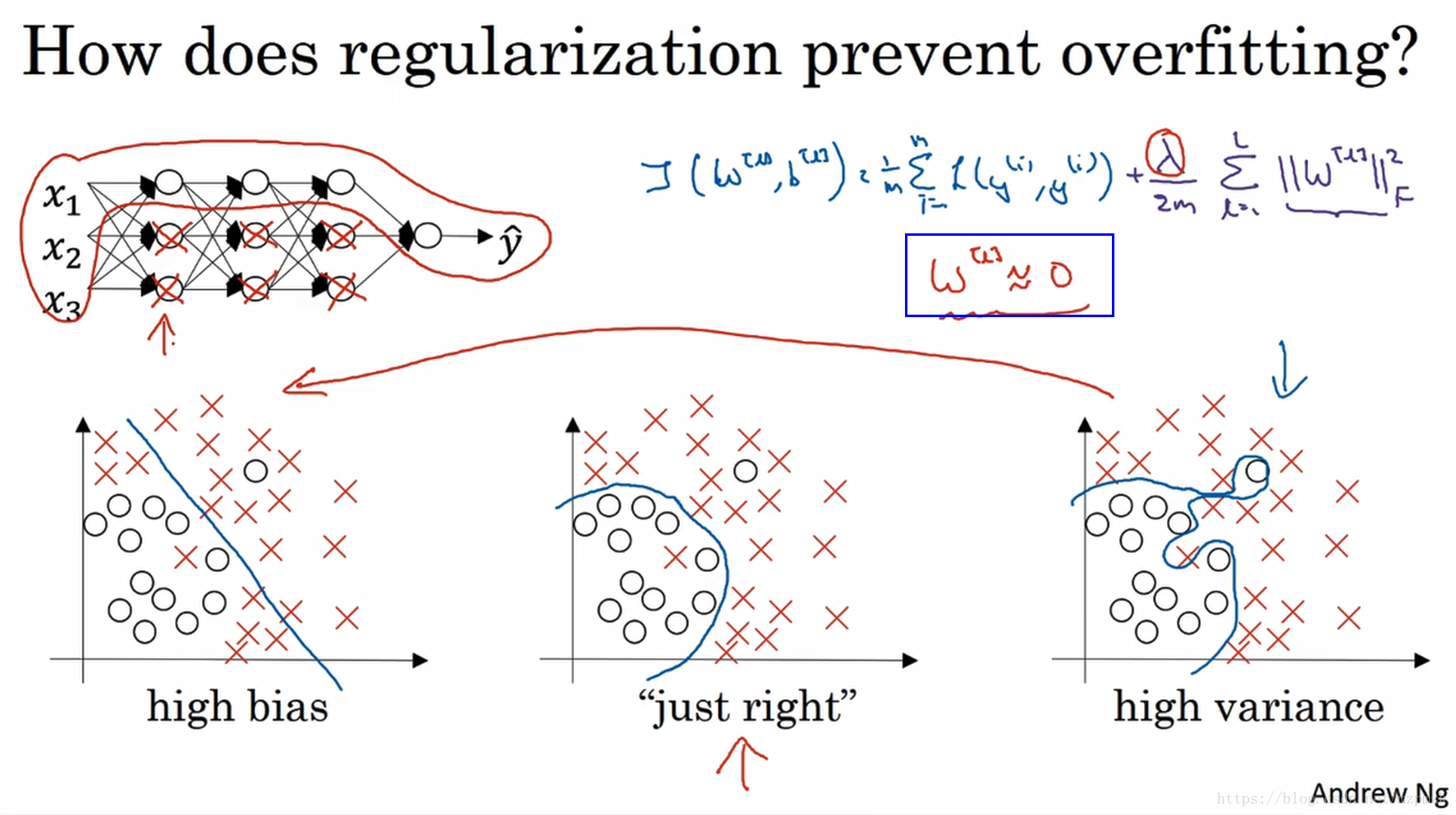
- 神经元随机失活的角度进行解释:如果正则化
设置得足够大,权重矩阵
被设置为接近于 0 的值,直观理解就是把多隐藏单元的权重设为 0,于是基本上消除了这些隐藏单元的许多影响。这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,可是深度却很大,它会使这个网络从过度拟合的状态更接近左图的高偏差状态。
- 神经元随机失活的角度进行解释:如果正则化
设置得足够大,权重矩阵
被设置为接近于 0 的值,直观理解就是把多隐藏单元的权重设为 0,于是基本上消除了这些隐藏单元的许多影响。这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,可是深度却很大,它会使这个网络从过度拟合的状态更接近左图的高偏差状态。
权重衰减(Weight Decay)的由来
- A regularization technique (such as L2 regularization) that results in gradient descent
shrinking the weights on every iteration.
- A regularization technique (such as L2 regularization) that results in gradient descent

五、Inverted Dropout
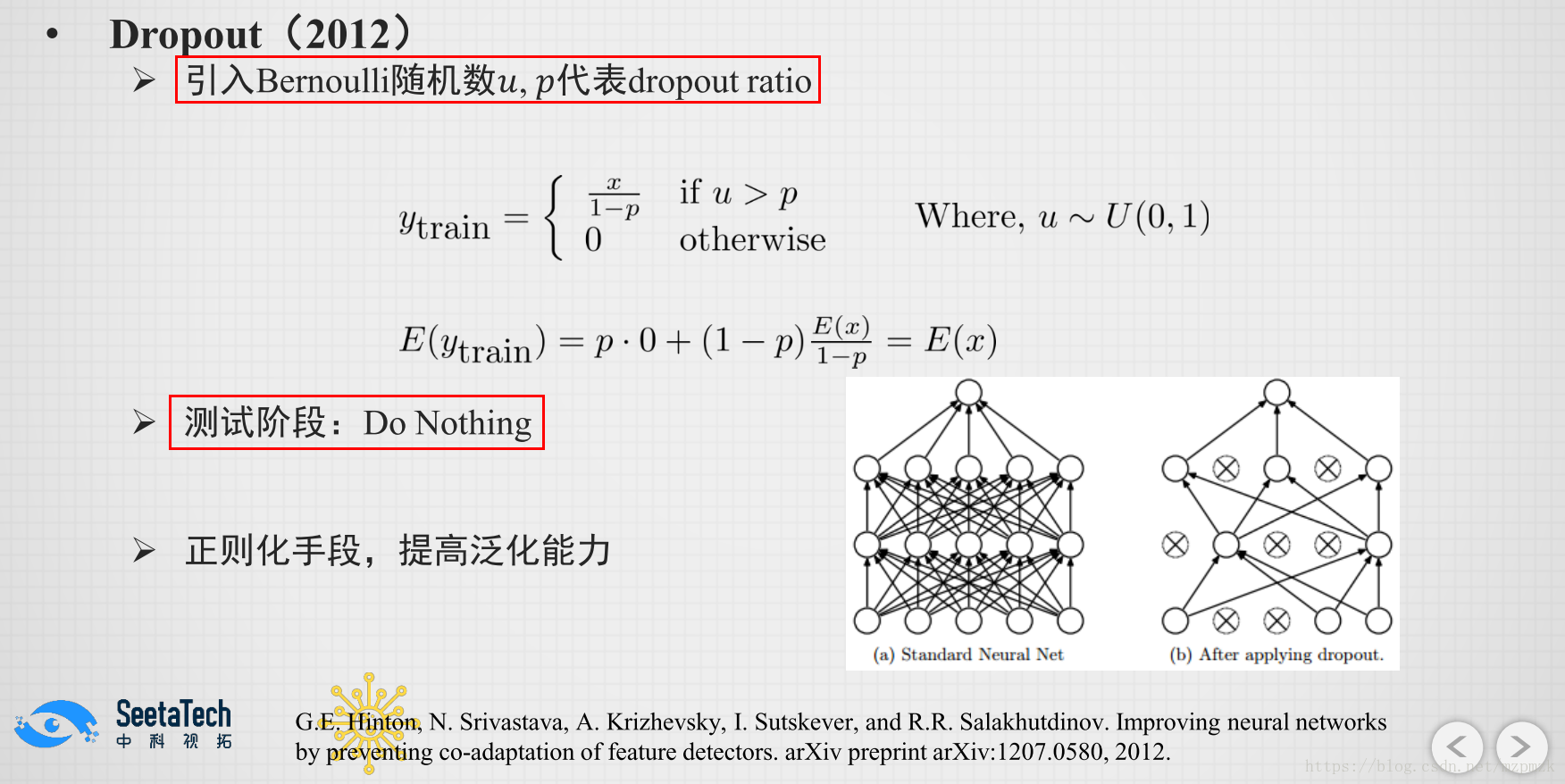
1、原理
- At each iteration, you randomly shut down (= set to zero) each neuron of a layer with probability or keep it with probability . The dropped neurons don’t contribute to the training in both the forward and backward propagations of the iteration(但是这部分神经元是实际存在的,只不过其值被设置为 0 了)
- During training time,
divideeach dropout layerby keep_probto keep the same expected value for the activations.
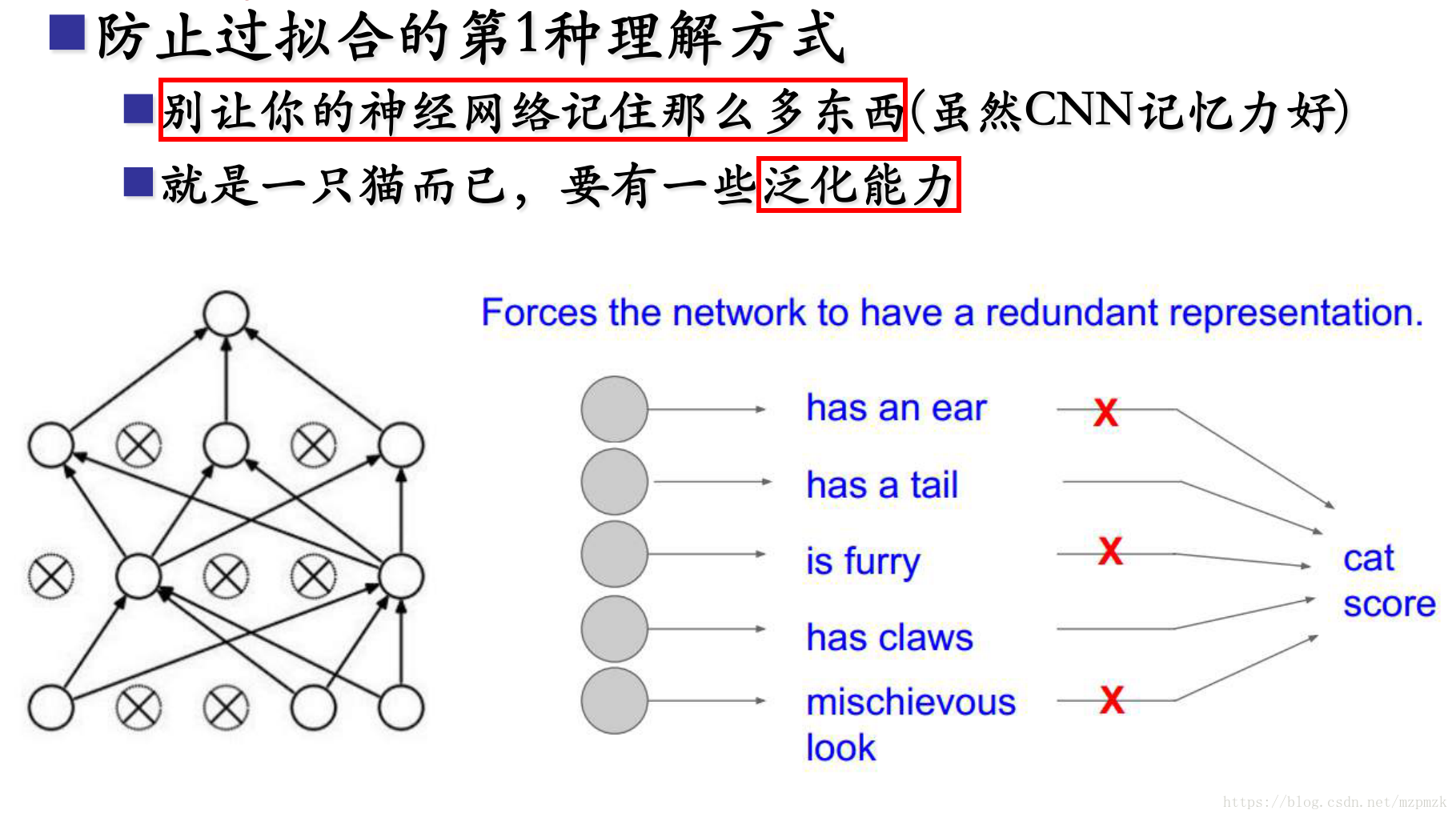
2、防止过拟合的理解
- When you shut some neurons down, you actually modify your model. The idea behind dropout is that at each iteration, you train a different model that uses only a subset of your neurons. With dropout, your neurons thus become less sensitive to the activation of one other specific neuron, because that other neuron might be shut down at any time.
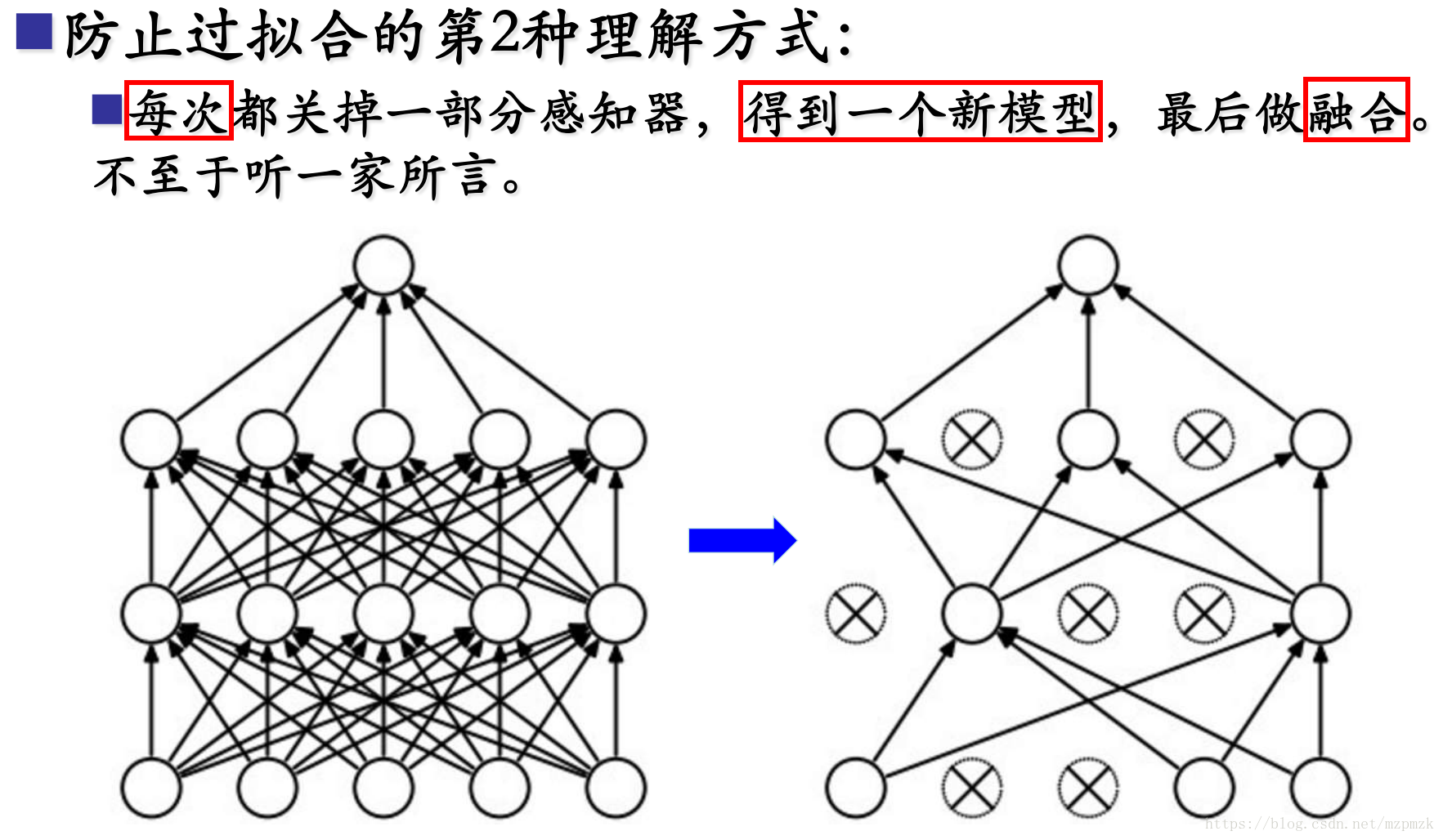
2、使用注意事项
- We will not apply dropout to the input layer or output layer.
- You only use dropout during training. Don’t use dropout (randomly eliminate nodes) during test time.
- Apply dropout both during forward and backward propagation.
- 可以对
某些隐藏层神经元或者每一隐藏层神经元进行随机丢弃,每一层都可以设置不同的丢保留概率。
3、代码
# 正向过程
# Step 1: initialize matrix D1 = np.random.rand(..., ...) to randomly get numbers between 0 and 1.
D1 = np.random.rand(A1.shape[0], A1.shape[1])
# Step 2: convert entries of D1 to 0 or 1 (using keep_prob as the threshold),D1 is a mask.
D1 = (D1 < keep_prob)
# Step 3: shut down(=set to zero) some neurons of A1
A1 = A1 * D1
# Step 4: scale the value of neurons that haven't been shut down.
# By doing this you are assuring that the result of the cost will still have the same expected value as without dropout.
A1 = A1 / keep_prob
# 反向过程
dA1 = np.dot(W2.T, dZ2)
# Step 1: Apply mask D1 to shut down the same neurons as during the forward propagation
dA1 = dA1 * D1
# Step 2: Scale the value of neurons that haven't been shut down
dA1 = dA1 / keep_prob 六、批量标准化(BN)
- 由于在训练的过程中批量标准化所用到的均值和方差是在一小批样本(mini-batch)上计算的,而不是在整个数据集上,所以均值和方差会有一些小噪声产生,同时缩放过程由于用到了含噪声的标准化后的值,所以也会有一点噪声产生,这迫使后面的神经元单元不过分依赖前面的神经元单元。所以,BN 也可以看作是一种
正则化手段,提高了网络的泛化能力,使得我们可以减少或者取消 Dropout,优化网络结构。- BN 的 详细内容参见博客:批量标准化(BN)、实例标准化(IN)、特征标准化(FN)