版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_32653877/article/details/86299167
作者:翁松秀
初识大数据——大数据技术家族
随着技术的不断演进以及新兴技术的不断完善,需要根据平台的数据模型和业务逻辑对平台的技术体系进行更新。为了更好地与大数据组进行某些方面的对接,以及运用大数据技术的优势,计划将平台的主要技术体系C# ,SQLServer演进为Java ,MySQL ,SparkSQL ,Redis。存储结构方面由原来的C#演进为MySQL和HDFS,业务方面以前主要由存储过程来实现,现在演进为用程序实现,解决存储过程的分布式计算需要借助连接服务器的瓶颈。大数据技术一方面用于存储我们平台的某些特殊数据,以便和大数据组进行对接,另一方面运用大数据在实时计算,基于内存的计算等优势来处理我们的某些业务逻辑。现在的目标是用Spark来实现性能数据统计入库和MRO数据统计入库。其他的业务模块由Java程序实现。
Hadoop是一个分布式存储和计算框架,利用计算机集群对大规模数据集进行存储和计算。Hadoop框架最核心的技术是HDFS(Hadoop Distributed File System)和MapReduce,HDFS负责大规模数据的存储,而MapReduce负责大规模数据的计算。所以Hadoop最原始的技术体系是这样的:
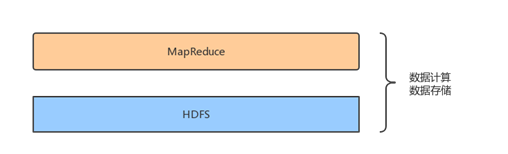
现在的Hadoop框架满足了数据的存储和数据的计算,为了提高在分析处理大规模数据的效率,充分利用SQL在处理数据时的便捷和高效,所以出现了数据库仓库工具Hive,提供了SQL接口,负责将SQL语句翻译成MapReduce。所以现在的体系大概是这样的:
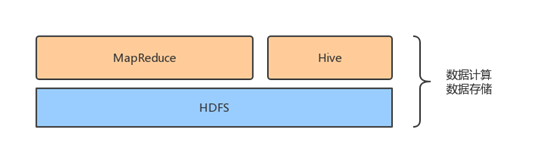
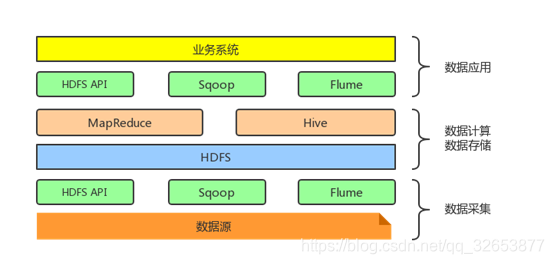
HDFS为大规模数据提供了存储方案,那我们应该如何将大规模数据采集到Hadoop的文件系统上?也就是采用什么方案来解决从大规模数据到HDFS的数据采集问题。
- HDFS API:HDFS提供了写数据的API,可以支持用户用编程语言调用API将自己的数据写入HDFS,但是在实际开发中很少用原生的API,都是采用封装好的框架,比如说Hive中的Insert语句,Spark中的saveAsTextFile。
- Sqoop框架:Sqoop是一个用于在HDFS文件系统和传统关系型数据库MySQL/SQLserver/Oracle进行数据同步的一个开源框架。
- Flume框架:Flume是一个分布式的海量日志采集和传输框架。
同理,也可以用HDFS API、Sqoop框架和Flume框架将HDFS上的数据传输我们的应用服务器中去。现在的Hadoop技术体系应该是这样的:
后来人们发现Hive后台使用MapReduce作为执行引擎处理速度确实有点慢,为了解决这个问题,出现了很多SQL On Hadoop框架,最常用的框架依次为:SparkSQL、Impala和Presto框架。这三个框架都是基于内存的大数据分析引擎。现在的Hadoop体系是这样的:
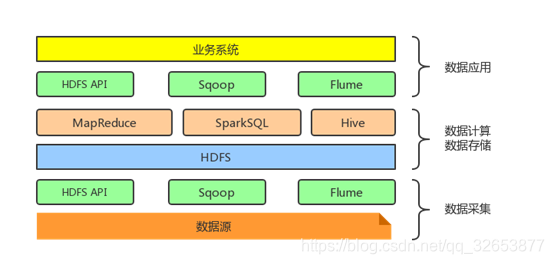
随着数据采集、分析和计算等任务越来越多,单纯地靠Hadoop的资源分配和任务调度器AppMaster远远不够,所以需要一个调度监控系统来完成对系统资源的分配、任务的调度和运行情况的监控。此时的Hadoop体系是这样的:
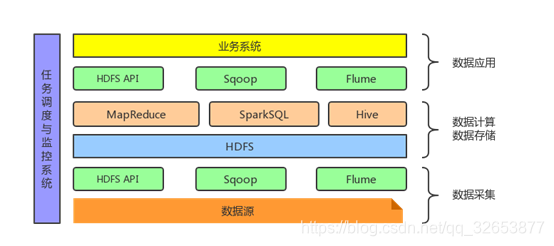
以上就是调研Hadoop大数据技术体系的雏形,鉴于现在Hadoop的各种框架多如牛毛,不可能在短时间内全部了解完。所以根据我们平台演进的需求,对Hadoop大数据从数据采集、数据存储、数据计算到数据应用的核心技术线对每个阶段的主要代表框架进行了调查和研究。后面会根据需要对Hadoop的实时计算,离线计算以及其他方面的优化进行学习和研究。SparkSQL能够从HDFS读取数据进行处理和计算,比如说数据统计,然后采用HDFS API或者Sqoop框架将统计结果同步到应用服务器中。如果有需要可以采用Flume框架对日志进行同步。