1.Sqoop是什么
Sqoop:SQL-to-Hadoop,传统数据库与Hadoop间数据同步工具。(MySQL、Oracle <==> HDFS、HBase、Hive)
Sqoop 的核心设计思想是利用 MapReduce 分布式批处理,加快了数据传输速度,保证了容错性。也就是说 Sqoop 的导入和导出功能是通过 MapReduce 作业实现的。
2.Sqoop1和Sqoop2两个版本
这两个版本是完全不兼容的,其具体的版本号区别为1.4.x为sqoop1(最高版本1.4.6),1.99x为sqoop2。sqoop1和sqoop2在架构和用法上已经完全不同。
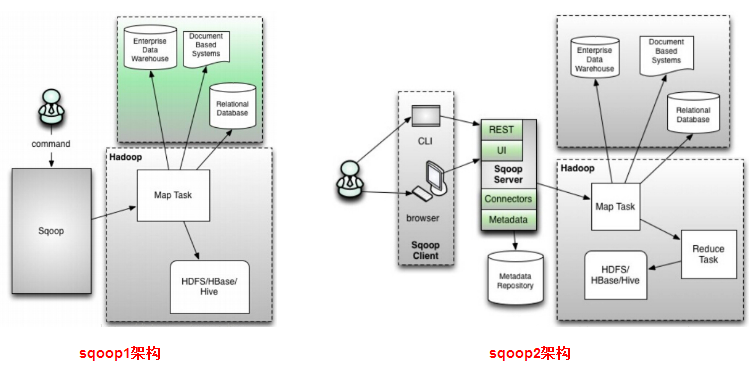
(1)sqoop2优势:
在架构上,sqoop2引入了sqoop server(具体服务器为tomcat),对connector实现了集中的管理。访问方式也变得多样化了,其可以通过REST API、JAVA API、WEB UI以及CLI控制台方式进行访问。
安全性能方面也有一定的改善,sqoop1需要显示指定数据库的用户名和密码。sqoop2中,如果是通过CLI方式访问的话,会有一个交互过程界面,你输入的密码信息不被看到。
(2) sqoop2缺点:
sqoop2的部署相比于sqoop1复杂的多。
sqoop2不兼容sqoop1,sqoop1中的import和export脚本实现的功能用JAVA API去重新编写。
3.Sqoop原理
(1)sqoop import原理:
从传统数据库获取元数据信息(schema、table、field、field type),把导入功能转换为只有Map的Mapreduce作业,在mapreduce中有很多map,每个map读一片数据,进而并行的完成数据的拷贝。
- 在导入前,Sqoop使用JDBC来检查将要导入的数据表。
- Sqoop检索出表中所有的列以及列的SQL数据类型。
- 把这些SQL类型的映射到java数据类型,例如(VARCHAR、INTEGER)———>(String,Integer)。
- 在MapReduce应用中将使用这些对应的java类型来保存字段的值。
- Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。
(2)sqoop export原理:
获取导出表的schema、meta信息,和Hadoop中的字段match;多个map only作业同时运行,完成hdfs中数据导出到关系型数据库中。
- 在导出前,sqoop会根据数据库连接字符串来选择一个导出方法 ————>对于大部分系统来说,sqoop会选择JDBC。
- Sqoop会根据目标表的定义生成一个java类。
- 这个生成的类能够从文本中解析出记录,并能够向表中插入类型合适的值(除了能够读取ResultSet中的列)。
- 然后启动一个MapReduce作业,从HDFS中读取源数据文件。
- 使用生成的类解析出记录,并且执行选定的导出方法。
参考文档: