作者:翁松秀
大数据技术——Spark
Spark简介
Spark是一种通用的大规模数据分析引擎,由于Spark是基于内存的分析引擎,所以它比基于硬盘的MapReduce效率要高许多。
Spark的优势:
- 高效性:基于内存的计算比MapReduce快差不多100多倍,而基于硬盘的计算也比MapReduce快10多倍。
- 易使用性:开发Spark可以采用两种方式,一种是内置的spark-shell,另一种是独立应用开发。Spark独立应用开发支持的语言有Scala、Java、R和Python四门编程语言。
- 通用性:Spark提供了Spark Streaming、SparkSQL、Spark MLlib和GraphX用于处理实时计算、结构化数据的交互式查询、机器学习和图计算等解决方案。
- 多样性:Spark可以运行在Hadoop、内置的standalone、Apache Mesos上、也可以运行在云端。能够处理的数据源包括:HDFS、Hive、HBase、Cassandra等多种数据源。
Spark架构

- Spark Core:是Spark的核心组件、包括:spark-shell(交互式工具)、SparkContext(Spark上下文)、RDD(弹性分布式数据集)。
- Spark SQL:交互式查询。
- Spark Streaming:实时流计算。
- Spark Mllib:机器学习库。
- GraphXML:图计算算法。
- 调度和资源管理器:Spark的资源管理和调度器可以用内置的Standalone,也可以用外部的资源管理和调度器,如Hadoop YARN,Apache Mesos和Kubernetes。
编程语言:Spark支持的编程语言有Scala、Java、Python和R四门语言。
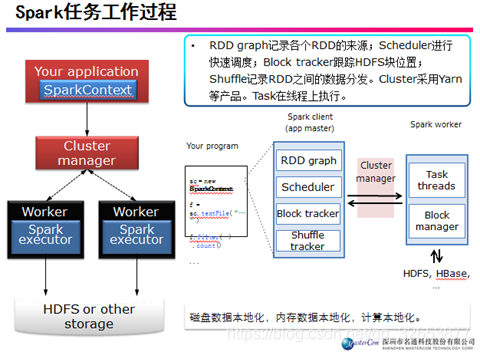
Spark任务工作过程
SparkContext是spark应用程序的入口,SparkContext允许Spark Driver通过调度和资源管理器来访问集群,获取spark的配置信息,并且通过SparkConf来配置应用程序的属性,比如worker节点运行的executors个数, 内存的大小以及核数。集群上的Executors会根据配置参数来分配每个内存和核数。
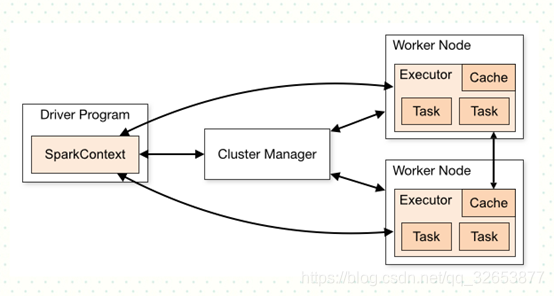
Executors进行计算和缓存,最后将计算结果写到HDFS或者其他地方。
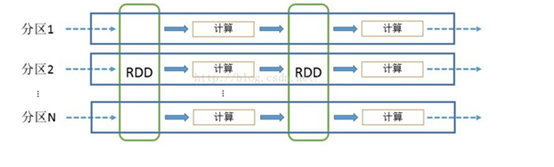
RDD可以看做是对各种数据计算模型的统一抽象,Spark的计算过程主要是RDD的迭代计算过程,如下图,RDD的迭代计算过程非常类似于管道。分区数量取决于partition数量的设定,每个分区的数据只会在一个Task中计算。所有分区可以在多个机器节点的Executor上并行执行。
Spark搭建本地开发环境
安装Spark
到官网http://spark.apache.org/downloads.html选择相应版本,下载安装包。我这里下的是2.3.1版本,后面安装的Hadoop版本需要跟Spark版本对应。下载后找个合适的文件夹解压即可。我是新建了一个home文件夹,底下放了三个文件夹,分别是spark, hadoop, scala。
解压之后配置环境变量,将Spark底下的bin文件所在的目录添加到环境变量的Path变量中,后面Hadoop也一样。
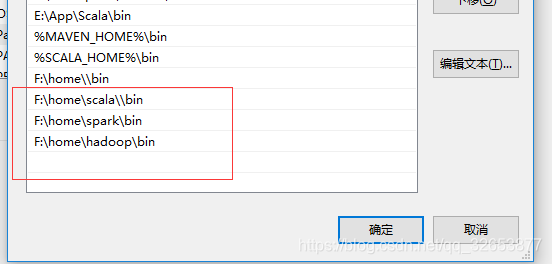
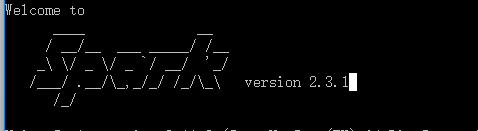
然后打开cmd进行测试,输入spark-shell,如果出现如下的”Spark”说明安装成功。
安装Hadoop
到http://mirrors.hust.edu.cn/apache/hadoop/common/下载相应版本的Hadoop安装包,我下的是2.7.7。具体的Spark和Hadoop版本对应可以到网上查,Spark和Hadoop版本不一致可能会导致出问题。

将下载好的安装好进行解压,然后将Hadoop底下的bin目录配置到Path变量中。为了防止运行程序的时候出现nullpoint异常,到github https://github.com/steveloughran/winutils 找到对应的hadoop版本,然后进入bin目录下,下载hadoop.dll和winutils.exe, 然后复制到所安装hadoop目录下。
安装Scala
到官网https://www.scala-lang.org/download/下载镜像,然后安装即可。一般默认会自动配置好环境变量。安装好之后打开cmd测试,输入scala,如果出现以下内容则安装成功。

如果没有成功,检查以下Path环境变量,如果安装之后没有自动配置,则手动配置,参照Spark的环境配置。
安装IDEA
Spark开发支持用内置的spark-shell,也支持用独立应用开发,独立应用开发支持的语言有Java、Scala、Python和R语言。如果采用Java语言进行Spark开发,需要配置Maven,最新版的Eclipse和IntelliJ都内置Maven,所以采用Eclipse和IntelliJ来开发Spark是比较方便的。
IntelliJ安装参考教程
https://blog.csdn.net/qq_35246620/article/details/61200815
Eclipse安装参考教程
https://jingyan.baidu.com/article/d7130635194f1513fcf47557.html
Spark应用程序集群测试
用Maven打包应用程序到Jar包
到应用程序所在目录,对maven工程进行编译和打包
编译命令:mvn compile
打包命令:mvn compile
本地测试spark应用程序
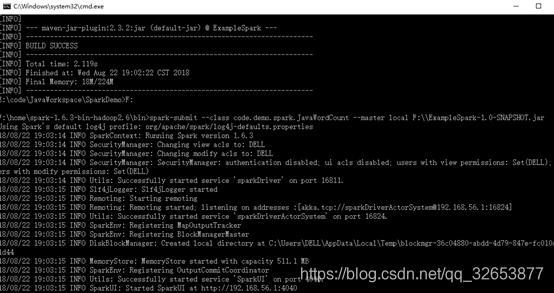
Jar包上传到服务器集群
通过winSCP将Jar包上传到Linux服务器。

集群上提交Jar包
提交命令:
.bin/spark-submint --class code.demo.spark.JavaWordCount --master spark://hadoop-mn01:7077 /home/hmaster/WordCount.jar
命令解释:
.bin/spark-submint :提交命令,提交应用程序
–class code.demo.spark.JavaWordCount:应用程序的主类
–master spark://hadoop-mn01:7077 :运行的master
/home/hmaster/WordCount.jar:jar包所在路径
集群测试结果
能顺利跑通wordcount程序,并且应用程序的HDFS读取没有问题,从HDFS读取待统计文件进行统计,结果如上。
Spark UI
可以在Spark UI中直观地监控spark的状态以及应用程序的运行状况。
Spark集群master主节点的WEBUI:http://192.168.1.xxx:8099/
Master WEBUI中可以查看spark的核数、内存、驱动和状态以及各个Worker字节点的具体信息、正在跑的应用程序、已经跑完的应用程序。
Spark集群worker子节点的WEBUI:http://192.168.1.xxx:8081/
Worker WebUI中可以查看子节点的核数、内存、运行中的Executors、还有已经结束了的Executors。
Spark集群 Jobs的WEBUI:http://192.168.1.xxx:18080/
Jobs的WEBUI记录了应用程序的运行日志,记录了所有运行过的应用程序的运行情况,以及未完成的应用程序,在每运行过的应用程序日志UI中都能看到应用程序执行的具体情况。
Hadoop WEBUI:http://192.168.1.xxx:8088/node
Hadoop Application WEBUI:http://192.168.1.xxx:8089
Spark启动和提交命令
用hmaster用户进入Spark安装的目录
启动master:sbin/start-master.sh
启动slaves:sbin/start-slaves.sh