一、大数据的概论
1.1 大数据概念
大数据(BigData) :指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
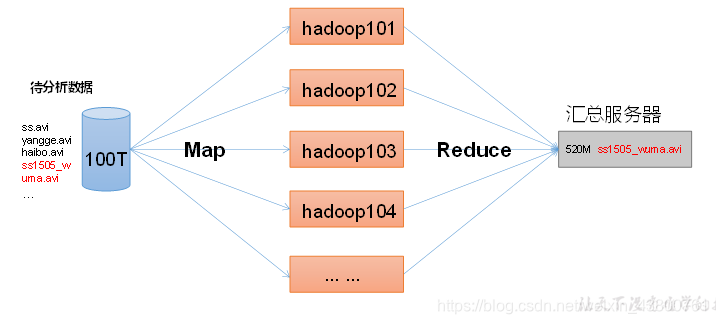
主要解决:海量数据的存储和海量数据的分析计算问题。PB,EB级别的数据存储单位。
1.2 大数据的特点(5V)
- Volume(大量)
数量巨大,通常在1PB(1024TB)以上,各行业标准不同。 - Velocity(高速)
数据增长速度快,读写、处理速度快、时效性高。 - Variety(多样)
结构多样化或非结构化。 - Value(低价值密度)
通过大量的数据才能刻画出有用信息,如深度学习中需要海量的样本数据。 - Veracity(真实性)
数据的准确性和可信赖度高。
传统的数据存储方式
- 关系型数据库
- 优点:
1.使用关系表保存数据,可表现复杂的数据关系并方便查询
2.最大限度的消除了数据冗余,节省存储空间
3.数据持久化存储在磁盘上可靠性高
4.SQL功能强大,便于编程 - 缺点:
1.频繁的约束性检查及索引维护导致写入效率低
2.数据的持久化存储,使得磁盘的IO读写速度成为瓶颈,导致读写效率低
3.SQL功能过于强大导致执行规则复杂,进而影响效率
- 优点:
分布式技术
将独立的具备不同功能和数据的主机连接起来,协同完成指定任务。
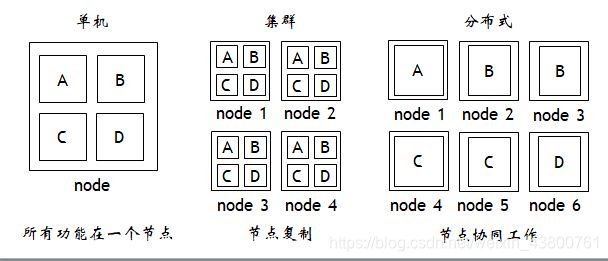
单机、集群和分布式的区别
- 单机:系统所有功能和资源在同一个节点上
- 集群:将单机中的功能复制到多个节点上,每个节点都是相同的
- 分布式:各节点功能不同,多个节点协同工作
新兴的数据处理技术——云技术
一种可以通过网络方便地接入共享资源池,按需获取计算资源的服务模型。共享资源池中的资源可以通过较少的管理代价和简单业务交互过程而快速部署和发布。
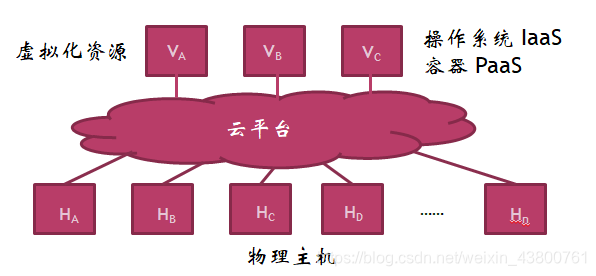
云计算类型
- 基础设施即服务(Infrastructure as a Service, IaaS)
利用虚拟化技术将硬件设备等基础资源封装成服务提供给用户使用,如:阿里云、腾讯云等 - 平台即服务(Platform as a Service, PaaS)
对资源进一步抽象,提供应用程序应用环境,用户只需上传自己的应用程序即可,类似以前的虚拟主机,如:微信小程序 - 软件即服务(Software as a Service, SaaS)
将应用软件功能封装成服务,如:病毒云查杀、百度网盘、iCloud
1.3 大数据应用场景
- 物流仓储:大数据分析系统助力商家精细化运营、提升销量、节约成本。

- 零售:分析用户消费习惯,为用户购买商品提供方便,从而提升商品销量。经典案例,子尿布+啤酒。

- 旅游:深度结合大数据能力与旅游行业需求,共建旅游广业智慧管理、智慧服务和智慧营销的未来。
- 商品广告推荐:给用户推荐可能喜欢的商品
- 保险:海量数据挖掘及风险预测,助力保险行业精准营销,提升精细化定价能力。
- 金融:多维度体现用户特征,帮助金融机构推荐优质客户,防范欺诈风险。
- 房产:大数据全面助力房地产行业,打造精准投策与营销,选出更合适的地,建造更合适的楼,卖给更合适的人
- 人工智能

二、大数据生态
2.1 Hadoop是什么
- Hadoop是 -个由Apache基金会所开发的分布式系统基础架构。
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
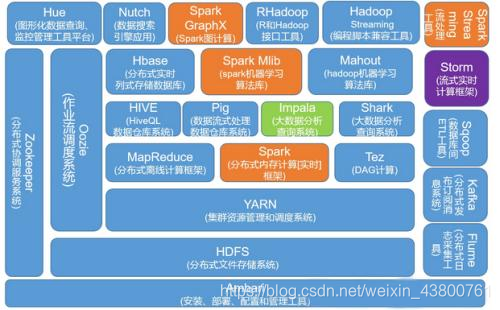
更细致的分层结构:
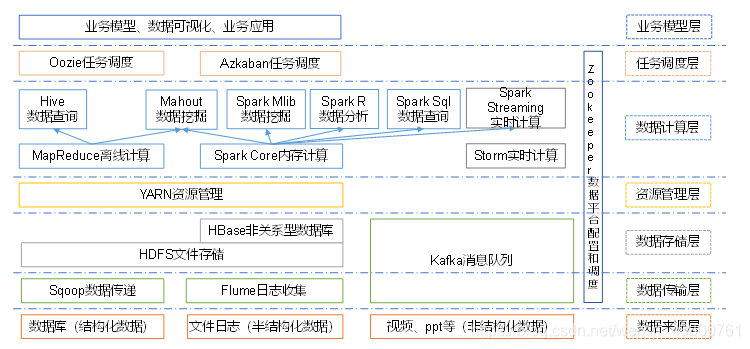
基于上图,对分层及其中的一些技术做了解释,其思维导图如下:

2.2 Hadoop发展历史
Google的伟大之处,不仅因为它建立了一个很好很强大的搜索引擎,而且还在于它创造了3项革命性的大数据技术:GFS、MapReduce和BigTable,即所谓的Google三驾马车。
Google三篇论文影响深远,“山寨”产品如潮水般涌现……
Cutting和Cafarella根据其前两篇论文完善其开源搜索引擎项目Nutch
2006年,Yahoo!聘请Cutting将Nutch搜索引擎中的存储和处理部分抽象成为Hadoop,Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理,逐渐成为行业主流。这样,Google以一种独特的方式,影响了大数据处理的潮流。
2.3 Hadoop的优势(4高)
- 可靠性: Hoqp店层准护多个数据副本,所以即使Hdo某个计算元素或存储出现故障,也不会导致数据的丢失。
- 高扩展性:在集群间分配任务数据,可方便的扩展数以干计的节点
- 高效性:在IMece思想下,Haoop是并行工作的,以加快任务处理速度。
- 高容错性:能够自动将失败的任务重新分配
2.4 Hadoop的组成
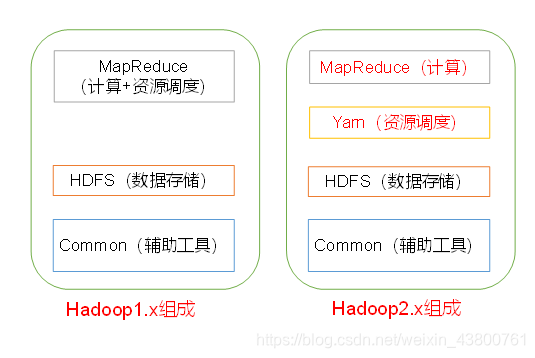
在Hadoop1x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
在Hadoop2.x时代,增加了Yamn。Yarn只负责资源的调度,MapReduce只负责运算。
2.4.1 HDFS架构概述
- NarneNode (nn) : 存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限)以及每个文件的块列表和块所在的DataNode等。
- DataNode(dn): 在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NamneNode(2n):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
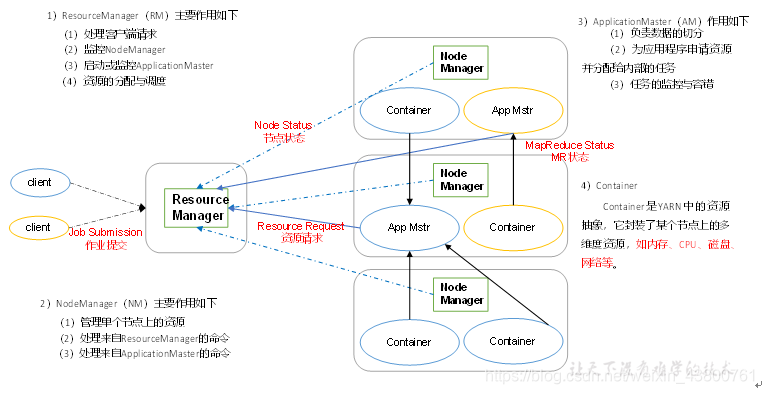
2.4.2 YARN架构概述
2.4.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段: Map 和Reduce.
- Map阶段并行处理输入数据。
- Reduce阶段对Map结果进行汇总。