行为识别阅读笔记(paper+code):Real-time Action Recognition with Enhanced Motion VectorCNNs
这篇文章是发表在CVPR2016上的一篇文章,这篇文章主要是对双流法进行了改进,双流法的诟病就是采用optimal flow作为temporal network的输入,因此速度巨慢,无法达到实时的目的,而这篇文章使用motion vector 替代optimal flow,极大地提高了双流法的速度,从UCF101和THUMOS14数据集上的测试效果来看准确率虽有点不及双流法,但速度却是得到巨大的提高。废话少说,先附上代码链接再说文章内容。
代码链接:https://github.com/zbwglory/MV-release
一、 大致算法框架
从网络框架开始介绍能快速了解文章算法思路,以及创新之处或者改进之处。
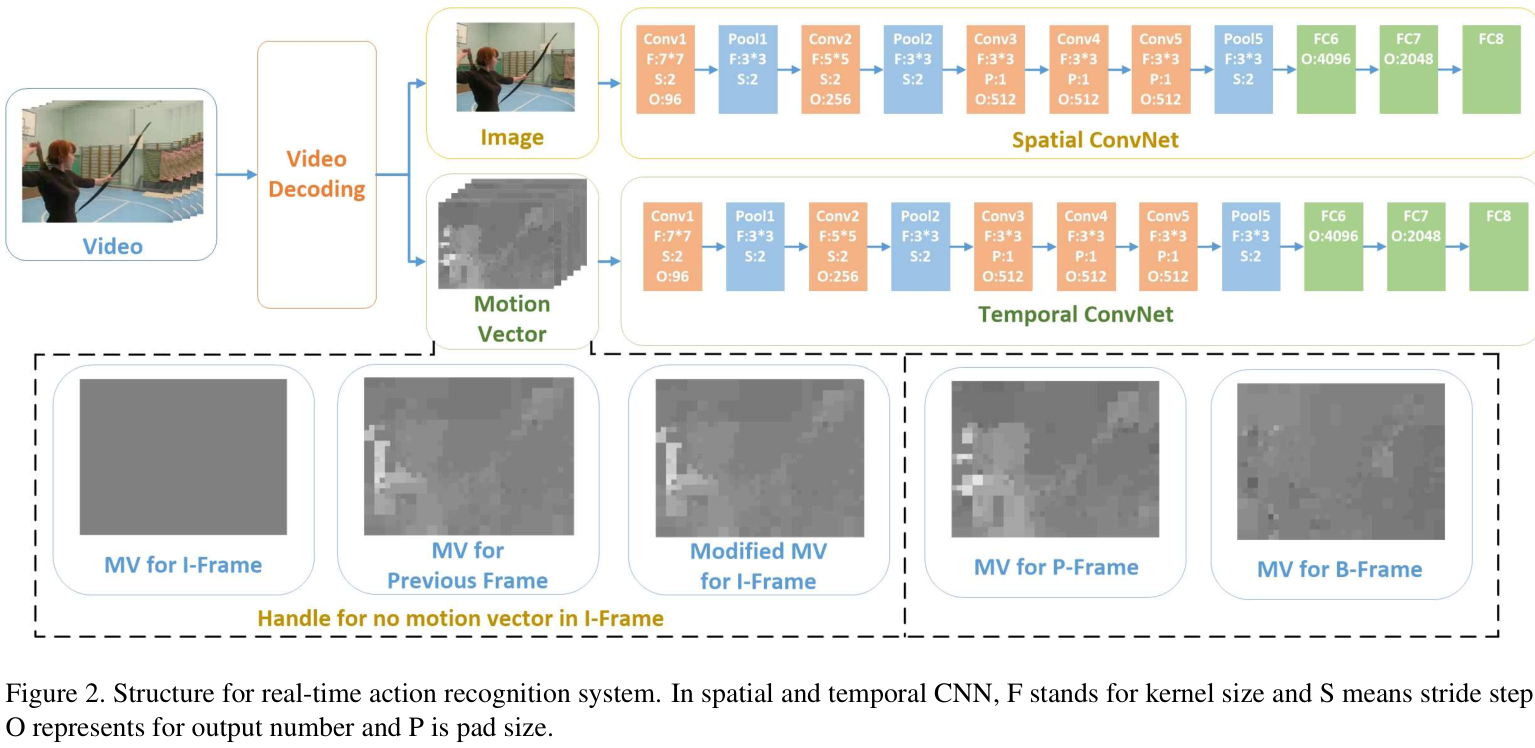
对比双流法,比较大的改进之处有两点:
(1)利用视频编码提取motion vectors,以motion vectors代替optimal flow;
(2)由于提取的motion vector存在大量的噪声,所以data输入质量肯定不及optimal flow,由于motion vector和optimal flow是内在相关的,因此为了达到与optimal flow同样的效果,在对temporalnetwork训练的时候,使用光流辅助训练temporal network,具体的训练策略文章给出了有三种:

下面具体讲解一些文章比较重要的内容。
二、 Motion vector
运动向量用于表示image block的运动模式,在描述局部运动是类似于optimal flow。然而运动向量的目的并不是用于尽可能准确的描述两个macro blocks的temporal 关系,而是利用相邻帧之间的temporal redundancy来对视频进行视频压缩。运动向量是block-level的,而光流是pixel-level的,因此运动向量包含的运动信息都是比较粗糙的,缺乏像素级的精细运动信息。此外,运动向量中包含着大量的噪声运动信息,这是因为视频压缩算法在压缩视频需要来考虑到编码速率和压缩率,所以信息难免粗糙,包含大量噪声信息。下图是运动向量与光流的对比,可以看出,运动向量包含噪声运动信息,而且比光流要粗糙的多。直接将运动向量代替光流,那效果肯定蹭蹭的往下降,作者实验发现,直接使用运动向量在UCF101上测试,准确率下降了7%。

此外,并不是所有帧图像中都包含运动向量。一个视频可以看作是一组图片(groupof pictures,GOP),一个典型的GOP包含三类帧:I-frame,P-frame和B-frame。I-frame是基于自身编码的帧内编码帧,不包含运动信息。而其他两类帧包含运动信息,I-frame会影响CNN训练效果,作者使用上一帧的运动向量替代I-frame。
三、EnhancedMotion Vector CNNs
作者认为运动向量和光流存在着某种共性。两者都可以在单帧图像上提取,而且都包含局部区域的运动信息。只不过两者包含的运动信息的粗糙程度不同而已。因此作者认为可以使用optical flow CNN (OF-CNN)上学习的特征或知识迁移到motion vectors (MV-CNN)。OF-CNN和MV-CNN具有相同的网络结构。在训练的阶段,使用光流来提高运动向量的效果,在测试阶段不使用。作者给出了三种knowledge transferring的训练策略,如上图示。
Teacher Initialization:使用OF-CNN训练好的权重初始化MV-CNN,然后训练MV-CNN;

最后网络训练的损失函数是:

值得注意的是,Teacher CNN是已经训练好的,因此在对Teacher CNN监督训练的时候,其网络权值是不变的。
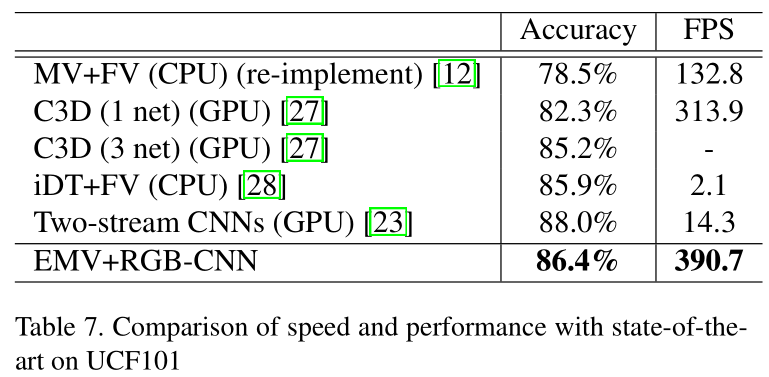
整篇文章的思路就是这样的,最后贴一下文章在UCF101上的实验结果。