【深度学习】生成对抗网络(GAN)的tensorflow实现
GAN( Generative Adversarial Nets)是Goodfellow I. J.大神在2014年提出的(参考资料【1】),在近几年成为人工智能领域研究的热点。本博文讲解最简单的生成对抗网络GAN原理并实现一个简单化GAN的tensorflow代码,可以作为大家入门GAN的参考资料。
一、GAN原理
原论文中给出这样一个例子:GAN由生成器(
)和判别器(
)构成。生成器就像是一个假钞制造团伙,它试图制造出完美的假钞;判别器就像是警察,试图正确分辨出所有的真钞和假钞。GAN模型就是在这种博弈的过程中训练出来的,如果最终生成器制造的假钞判别器都无法正确辨别出真假,此时的生成器就达到最优性能;如果任何生成器制造的假钞,判别器都可以准确判别,判别器就达到最优性能。
GAN的网络模型如下图所示:
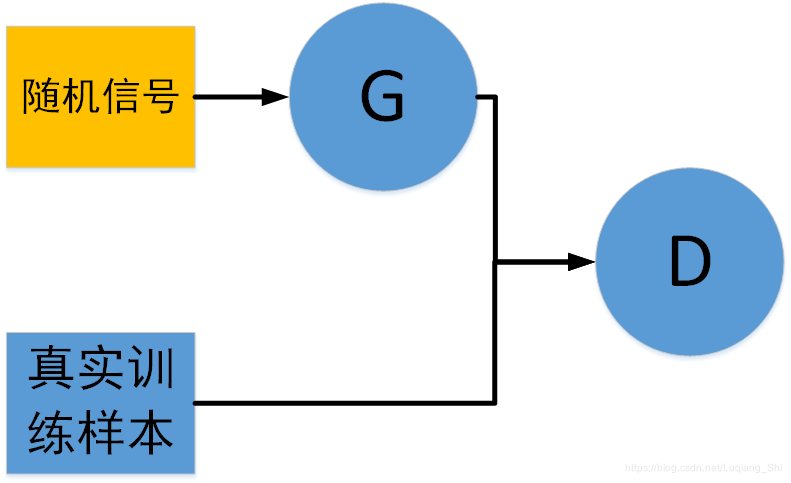
假设真实训练样本为
随机信号为
则GAN的最优化问题为:
在判别器 中,当输入数据为真实的训练数据,对应标签为 ;当输入数据为生成器 生成的数据,对应标签为 。
二、GAN的应用
GAN有三个最主要的应用(参考资料【2】):
数据生成:训练GAN的训练样本为 ,使生成器 具有模仿训练样本的能力,利用训练好的生成器生成与训练样本具有相同分布的数据。
图片去燥:训练GAN的训练样本为 ,其中 为带噪音的数据, 为无噪音的数据,使生成器 具有数据去燥的能力。
图片风格转换:训练GAN的训练样本为 ,其中 为原始风格数据, 为另一种风格的数据,使生成器 具有风格转换的能力。
三、GAN的tensorflow实现
完整的tensorflow代码与训练样本地址:https://github.com/shiluqiang/Simple_GAN_tensorflow
本博文GAN的tensorflow实现(参考资料【3】),采用10个手写图片(数值为0,维度为32×32)当做训练样本,训练生成器
的学习能力,生成器
生成4个手写图片。
第一步,导入训练样本:
## 1.导入训练数据
def img2vector(filename):
'''将32*32的训练数据转换为1*1024的训练数据
input:filename(str):训练数据存储文件名
output:returnVect(array):1*1024的训练数据
'''
returnVect = np.zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def load_train_data(file_name):
'''导入训练数据
input:file_name(str):训练数据存储文件夹
output:trainMat(array):训练数据
'''
trainingFileList = os.listdir(file_name) #训练数据存储文件的名称的列表
m = len(trainingFileList)
trainMat = np.zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
trainMat[i,:] = img2vector(file_name + '/%s'%fileNameStr)
return trainMat
trainMat = load_train_data('train_data') ##导入的训练数据[10,1024]
第二步,声明训练样本和生成器输入的占位符、生成器与判别器的变量:
## 2. 声明训练样本和生成器输入的占位符/生成器与判别器的变量
def xavier_init(size): #初始化参数时使用的xavier_init函数
in_dim = size[0]
xavier_stddev = 1. / tf.sqrt(in_dim / 2.) #初始化标准差
return tf.random_normal(shape=size, stddev=xavier_stddev) #返回初始化的结果
X = tf.placeholder(tf.float32, shape=[None, 1024]) #X表示真的样本(即真实的手写数字)
D_W1 = tf.Variable(xavier_init([1024, 128])) #表示使用xavier方式初始化的判别器的D_W1参数,是一个1024行128列的矩阵
D_b1 = tf.Variable(tf.zeros(shape=[128])) #表示全零方式初始化的判别器的D_1参数,是一个长度为128的向量
D_W2 = tf.Variable(xavier_init([128, 1])) #表示使用xavier方式初始化的判别器的D_W2参数,是一个128行1列的矩阵
D_b2 = tf.Variable(tf.zeros(shape=[1])) ##表示全零方式初始化的判别器的D_1参数,是一个长度为1的向量
theta_D = [D_W1, D_W2, D_b1, D_b2] #theta_D表示判别器的可训练参数集合
Z = tf.placeholder(tf.float32, shape=[None, 100]) #Z表示生成器的输入(在这里是噪声),是一个N列100行的矩阵
G_W1 = tf.Variable(xavier_init([100, 128])) #表示使用xavier方式初始化的生成器的G_W1参数,是一个100行128列的矩阵
G_b1 = tf.Variable(tf.zeros(shape=[128])) #表示全零方式初始化的生成器的G_b1参数,是一个长度为128的向量
G_W2 = tf.Variable(xavier_init([128, 1024])) #表示使用xavier方式初始化的生成器的G_W2参数,是一个128行1024列的矩阵
G_b2 = tf.Variable(tf.zeros(shape=[1024])) #表示全零方式初始化的生成器的G_b2参数,是一个长度为1024的向量
theta_G = [G_W1, G_W2, G_b1, G_b2] #theta_G表示生成器的可训练参数集合
第三步, 构造前向计算图(生成器与判别器):
def sample_Z(m, n): #生成维度为[m, n]的随机噪声作为生成器G的输入
return np.random.uniform(-1., 1., size=[m, n])
def generator(z): #生成器,z的维度为[N, 100]
G_h1 = tf.nn.relu(tf.matmul(z, G_W1) + G_b1) #输入的随机噪声乘以G_W1矩阵加上偏置G_b1,G_h1维度为[N, 128]
G_log_prob = tf.matmul(G_h1, G_W2) + G_b2 #G_h1乘以G_W2矩阵加上偏置G_b2,G_log_prob维度为[N, 1024]
G_prob = tf.nn.sigmoid(G_log_prob) #G_log_prob经过一个sigmoid函数,G_prob维度为[N, 1024]
return G_prob #返回G_prob
def discriminator(x): #判别器,x的维度为[N, 1024]
D_h1 = tf.nn.relu(tf.matmul(x, D_W1) + D_b1) #输入乘以D_W1矩阵加上偏置D_b1,D_h1维度为[N, 128]
D_logit = tf.matmul(D_h1, D_W2) + D_b2 #D_h1乘以D_W2矩阵加上偏置D_b2,D_logit维度为[N, 1]
D_prob = tf.nn.sigmoid(D_logit) #D_logit经过一个sigmoid函数,D_prob维度为[N, 1]
return D_prob, D_logit #返回D_prob, D_logit
def plot(samples): #保存图片时使用的plot函数
fig = plt.figure(figsize=(2, 2)) #初始化一个2行2列包含4张子图像的图片
gs = gridspec.GridSpec(2, 2) #调整子图的位置
gs.update(wspace=0.05, hspace=0.05) #置子图间的间距
for i, sample in enumerate(samples): #依次将16张子图填充进需要保存的图像
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(sample.reshape(32, 32), cmap='Greys_r')
return fig
第四步, 声明代价函数与优化算法:
G_sample = generator(Z) #取得生成器的生成结果
D_real, D_logit_real = discriminator(X) #取得判别器判别的真实手写数字的结果
D_fake, D_logit_fake = discriminator(G_sample) #取得判别器判别的生成的手写数字的结果
D_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_real, labels=tf.ones_like(D_logit_real))) #对判别器对真实样本的判别结果计算误差(将结果与1比较)
D_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_fake, labels=tf.zeros_like(D_logit_fake))) #对判别器对虚假样本(即生成器生成的手写数字)的判别结果计算误差(将结果与0比较)
D_loss = D_loss_real + D_loss_fake #判别器的误差
G_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_fake, labels=tf.ones_like(D_logit_fake))) #生成器的误差(将判别器返回的对虚假样本的判别结果与1比较)
D_solver = tf.train.AdamOptimizer().minimize(D_loss, var_list=theta_D) #判别器的训练器
G_solver = tf.train.AdamOptimizer().minimize(G_loss, var_list=theta_G) #生成器的训练器
第五步,构造tf.Session()会话,反向传播训练模型:
mb_size = 10 #训练的batch_size
Z_dim = 100 #生成器输入的随机噪声的列的维度
sess = tf.Session() #会话层
sess.run(tf.global_variables_initializer()) #初始化所有可训练参数
i = 0 #训练过程中保存的可视化结果的索引
for it in range(100000): #训练10万次
if it % 1000 == 0: #每训练1000次就保存一下结果
samples = sess.run(G_sample, feed_dict={Z: sample_Z(4, Z_dim)})
fig = plot(samples) #通过plot函数生成可视化结果
plt.savefig('out/{}.png'.format(str(i).zfill(3)), bbox_inches='tight') #保存可视化结果
i += 1
plt.close(fig)
X_mb = trainMat ## 训练数据
#下面是得到训练一次的结果,通过sess来run出来
_, D_loss_curr = sess.run([D_solver, D_loss], feed_dict={X: X_mb, Z: sample_Z(mb_size, Z_dim)})
_, G_loss_curr = sess.run([G_solver, G_loss], feed_dict={Z: sample_Z(mb_size, Z_dim)})
if it % 1000 == 0: #每训练1000次输出一下结果
print('Iter: {}'.format(it))
print('D loss: {:.4}'. format(D_loss_curr))
print('G_loss: {:.4}'.format(G_loss_curr))
print()
第1000次训练后,生成器
生成的数据:

第10000次训练后,生成器
生成的数据:

第90000次训练后,生成器
生成的数据:

参考资料
1、Goodfellow I J , Pouget-Abadie J , Mirza M , et al. Generative Adversarial Nets[C]// International Conference on Neural Information Processing Systems. MIT Press, 2014.
2、https://blog.csdn.net/maqunfi/article/details/82220297
3、https://blog.csdn.net/jiongnima/article/details/80033169