基本概念
概述
GAN是一种深度学习模型,它是一种无监督学习算法,用于从随机噪声中生成逼真的数据,比如图像、音频、文本等。GAN的结构由两个神经网络组成:生成器(Generator)和判别器(Discriminator),它们彼此竞争,从而推动整个模型学习。
两个主要组件:
1.生成器(Generator):
生成器的目标是将随机噪声(通常是从正态分布或均匀分布中采样的向量)转换成逼真的数据样本。这个过程可以理解为生成器学习了数据的分布,并尝试创建与真实数据相似的新样本。初始阶段,生成器的输出可能是随机的,但随着训练的进行,它会逐渐生成更逼真的数据,以欺骗判别器。
2.判别器(Discriminator):
判别器的任务是对输入的数据样本进行分类,即判断它是真实数据还是由生成器产生的假数据。判别器是一个二元分类器,它的目标是尽可能准确地区分真实数据和生成器生成的假数据。
训练过程
1.在训练开始时,生成器随机产生一些假数据样本,并与真实数据一起提供给判别器。
2.判别器根据输入的数据对其进行分类,并输出概率估计(0代表假数据,1代表真实数据)。
3.根据判别器的输出,计算生成器生成数据被判别为真实数据的概率,并将这个概率作为生成器的“损失”(loss)。
4.接下来,根据生成器的损失,更新生成器的参数,使生成器能够生成更逼真的数据样本。
5.然后,再次随机产生一批假数据样本,并将它们与真实数据一起提供给判别器,重复以上过程。
通过这种竞争和博弈的过程,生成器和判别器逐渐优化自己的能力,直到生成器可以生成高度逼真的数据样本,而判别器无法准确区分真假。
代码与注释
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# Hyper Parameters
BATCH_SIZE = 64
# 生成器学习率
LR_G = 0.0001 # learning rate for generator
# 判别器学习率
LR_D = 0.0001 # learning rate for discriminator
N_IDEAS = 5 # think of this as number of ideas for generating an art work (Generator)
ART_COMPONENTS = 15 # it could be total point G can draw in the canvas
PAINT_POINTS = np.vstack([np.linspace(-1, 1, ART_COMPONENTS) for _ in range(BATCH_SIZE)])
# 定义函数artist_works,用于生成来自著名艺术家的真实画作数据
def artist_works():
a = np.random.uniform(1, 2, size=BATCH_SIZE)[:, np.newaxis]
paintings = a * np.power(PAINT_POINTS, 2) + (a - 1)
paintings = torch.from_numpy(paintings).float()
return paintings
# 定义生成器(Generator)和判别器(Discriminator)
# 初级画家
G = nn.Sequential(
nn.Linear(N_IDEAS, 128), # 生成器输入为随机噪声数据
nn.ReLU(),
nn.Linear(128, ART_COMPONENTS), # 生成器输出为生成的艺术作品
)
# 初级鉴赏家
D = nn.Sequential(
nn.Linear(ART_COMPONENTS, 128), # 判别器输入为艺术作品数据
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid(), # 判别器输出为对艺术作品的真假概率
)
# 定义两个优化器,分别用于优化生成器和判别器的参数
opt_D = torch.optim.Adam(D.parameters(), lr=LR_D)
opt_G = torch.optim.Adam(G.parameters(), lr=LR_G)
# 开始GAN的训练
plt.ion() # 打开交互式绘图
for step in range(10000):
# 获取来自艺术家的真实画作数据
artist_paintings = artist_works()
# 生成随机的噪声数据
G_ideas = torch.randn(BATCH_SIZE, N_IDEAS, requires_grad=True)
# 生成器生成假的艺术画作
G_paintings = G(G_ideas)
# 判别器对生成的画作进行判断,试图减小判别器对生成画作的概率
prob_artist1 = D(G_paintings)
# 计算生成器的损失
G_loss = torch.mean(torch.log(1. - prob_artist1))
opt_G.zero_grad() # 清空生成器的梯度
G_loss.backward() # 反向传播计算生成器的梯度
opt_G.step() # 优化生成器的参数
# 判别器对真实画作进行判断,试图增大判别器对真实画作的概率
prob_artist0 = D(artist_paintings)
# 判别器对生成的画作进行判断,试图减小判别器对生成画作的概率
prob_artist1 = D(G_paintings.detach())
# 计算判别器的损失
D_loss = - torch.mean(torch.log(prob_artist0) + torch.log(1. - prob_artist1))
opt_D.zero_grad() # 清空判别器的梯度
D_loss.backward(retain_graph=True) # 反向传播计算判别器的梯度(保留计算图以供下一次计算)
opt_D.step() # 优化判别器的参数
if step % 50 == 0: # 每隔一段时间进行绘图显示
# 绘制生成的画作、上界和下界
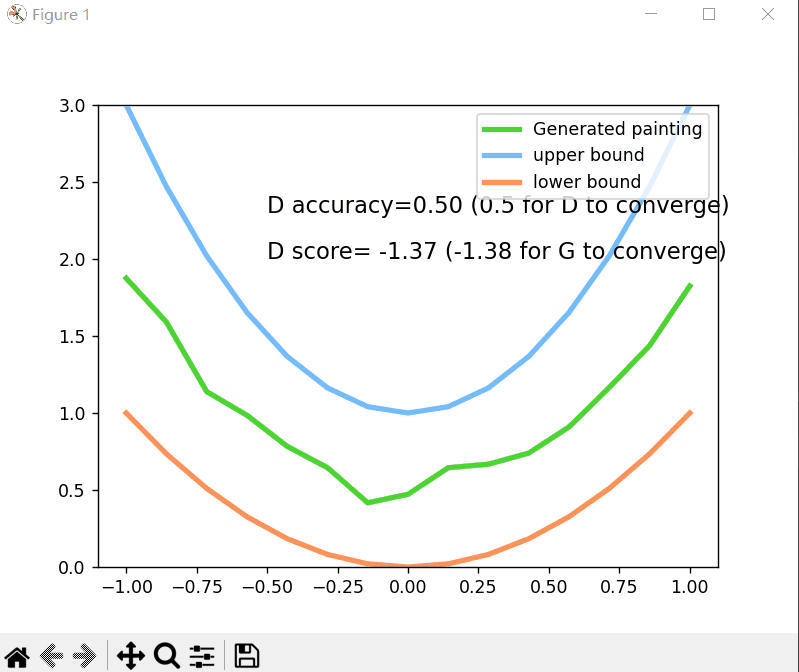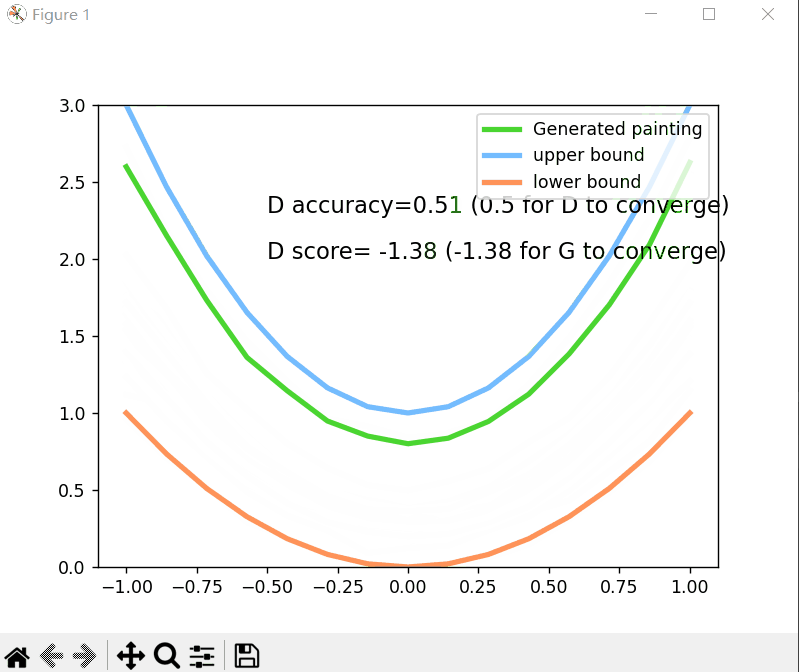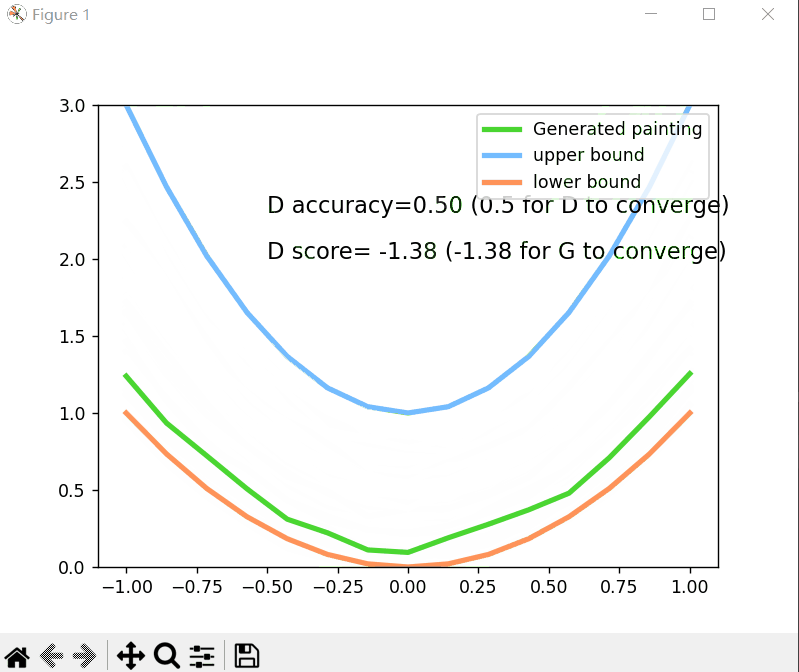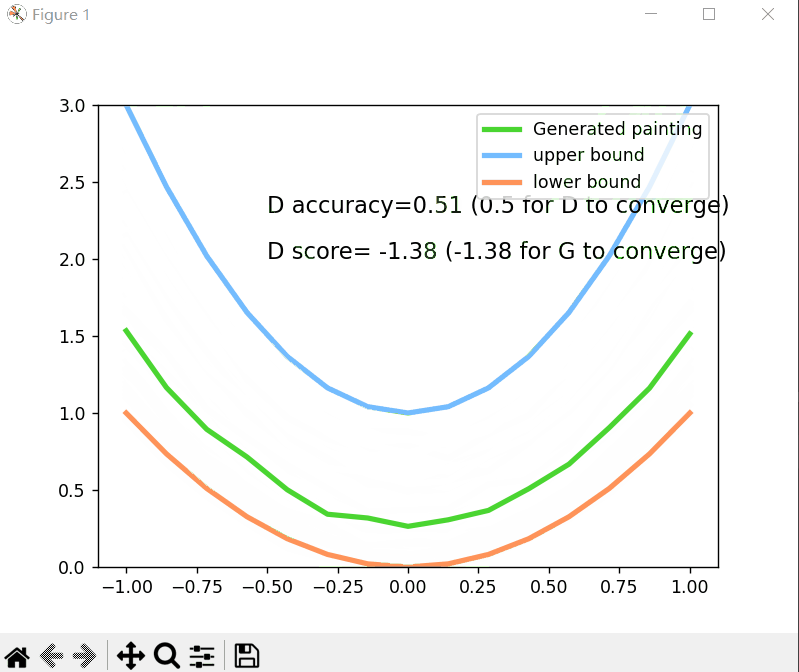
plt.cla()
plt.plot(PAINT_POINTS[0], G_paintings.data.numpy()[0], c='#4AD631', lw=3, label='Generated painting')
plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + 1, c='#74BCFF', lw=3, label='upper bound')
plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + 0, c='#FF9359', lw=3, label='lower bound')
plt.text(-.5, 2.3, 'D accuracy=%.2f (0.5 for D to converge)' % prob_artist0.data.numpy().mean(), fontdict={
'size': 13})
plt.text(-.5, 2, 'D score= %.2f (-1.38 for G to converge)' % -D_loss.data.numpy(), fontdict={
'size': 13})
plt.ylim((0, 3))
plt.legend(loc='upper right', fontsize=10)
plt.draw()
plt.pause(0.01)
plt.ioff() # 关闭交互式绘图
plt.show() # 展示绘制的图像
运行结果