生成对抗网络的tensorflow实现
原文地址:http://blog.evjang.com/2016/06/generative-adversarial-nets-in.html
这是关于使用tensorflow来实现Goodfellow的生成对抗网络论文的教程。对抗网络是一个可以使用大约80行的python代码就可以实现的一个有趣的小深度学习练习,这将使你进入深度学习的一个活跃领域:生成式模型。
Github上的源码
情景:假币
为了更好地解释这篇论文的动机,这里提供一个假设场景:
Danielle是一个银行的出纳员,她的工作职责之一就是辨别真币与假币。George是一个制造假币的骗子,因为免费的钱相当激进。
让我们简化一下:假定货币的唯一显著特征就是印在每个钞票上的唯一编号
George的目标是从
我们可以在不知道真实的潜在生成过程的情况下制造出计算不可区分的样例[1]。这个潜在的生成过程是财政部所使用的生成样例
我们可以将这种算法看做“自然(函数)基”,财政部将使用这种直接的方法来印制我们假设的钞票。然而,一个(连续)函数可以用一系列不同的基函数来表征;George 可以使用“神经网络基”,“傅里叶基”或者其它的能用来构建近似器的基来表示相同的抽样算法。从局外人的角度来看,这些抽样器是计算上不可区分的,然而 George的模型并没有将
背景:判别模型 vs 生成模型
我们使用
一个判别式模型可以用来评估条件概率
另外一方面,一个生成式模型可以用来估计联合分布

当然,生成模型比判别模型更难构建,这两者都是统计学与机器学习研究的热点领域。
生成对抗网络
Goodfellow的论文提出了一个优雅的方式来将神经网络训练成一个可以表示任何(连续)概率密度函数的生成模型。我们构建两个神经网络,分别是
对抗网络已经成功地用来凭空合成下列类型的图片:


在这个教程里,我们不会做任何很神奇的东西,但是希望你将会对对抗网络有一个更基本的了解。
实现
我们将训练一个神经网络用来从简单的一维正态分布
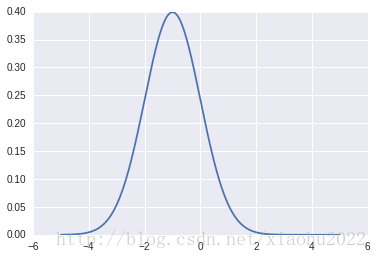
这里
同时,判别器
这里是Python代码:
batch = tf.Variable(0)
obj_d = tf.reduce_mean(tf.log(D1)+tf.log(1-D2))
opt_d = tf.train.GradientDescentOptimizer(0.01)
.minimize(1-obj_d,global_step=batch,var_list=theta_d)我们之所以要不厌其烦地指定
当优化
batch=tf.Variable(0)
obj_g=tf.reduce_mean(tf.log(D2))
opt_g=tf.train.GradientDescentOptimizer(0.01)
.minimize(1-obj_g,global_step=batch,var_list=theta_g)在优化时我们不是仅在某一刻输入一个值对
训练的循环过程是非常简单的:
# Algorithm 1, GoodFellow et al. 2014
for i in range(TRAIN_ITERS):
x= np.random.normal(mu,sigma,M) # sample minibatch from p_data
z= np.random.random(M) # sample minibatch from noise prior
sess.run(opt_d, {x_node: x, z_node: z}) # update discriminator D
z= np.random.random(M) # sample noise prior
sess.run(opt_g, {z_node: z}) # update generator G流形对齐
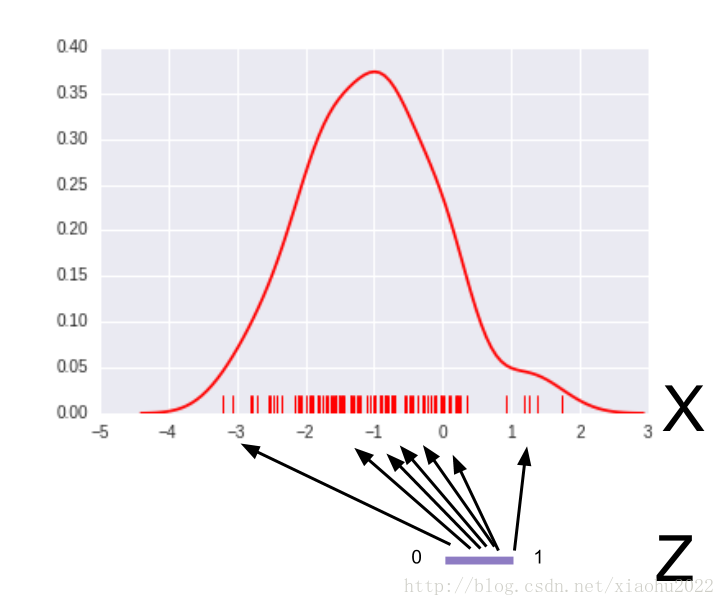
简单地用上面的方法并不能得到好结果,因为每次迭代中我们是独立地从
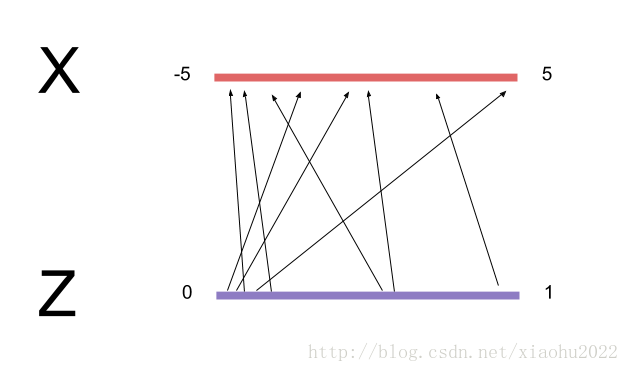
为了解决这个问题,我们想最小化从
首先,我们将
这里我们不是采用 np.random.random.sort()的方法来抽样
当然,对于高维问题,由于在二维或者更高维空间里面对点排序并无意义,所以对其输入空间
修改的算法如下:
for i in range(TRAIN_ITERS):
x= np.random.normal(mu,sigma,M).sort()
z= np.linspace(-5.,5.,M)+np.random.random(M)*.01 # stratified
sess.run(opt_d, {x_node: x, z_node: z})
z= np.linspace(-5.,5.,M)+np.random.random(M)*.01
sess.run(opt_g, {z_node: z})这是使这个例子有效的很关键一步:当使用随机噪音作为输入时,未能正确地对齐转化映射线将会产生一系列其它问题,如过大的梯度很早地关闭ReLU神经元,目标函数停滞,或者性能不能随着批量大小缩放。
预处理判别模型
在原始的算法中,GAN是每次通过梯度下降训练
这里是初始的决定边界:
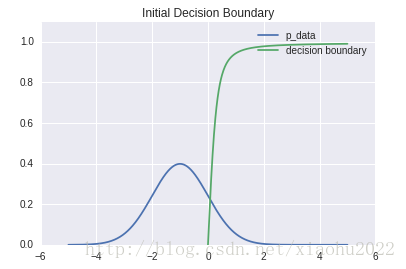
预训练之后:
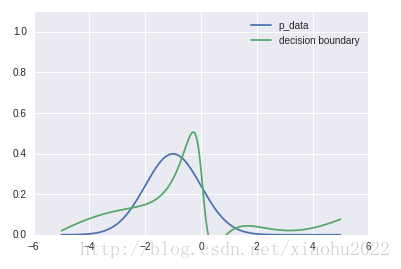
已经非常接近了,窃喜!
其它的棘手问题建议
- 模型过大容易导致过拟合,但是在这个例子中,网络过大在极小极大目标下甚至不会收敛-神经元在很大的梯度下很快达到饱和。从浅层的小网络开始,除非你觉得有必要再去增加额外的神经元或者隐含层。
- 刚开始我使用的是ReLU神经元,但是这种神经元一直处于饱和状态(也许由于流形对齐问题)。Tanh激活函数好像更有效。
- 我必须要调整学习速率才能得到很好的结果。
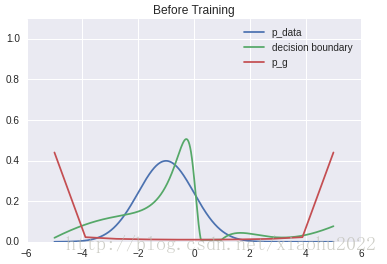
结果
下面是训练之前的
这是代价函数在训练迭代过程中的变化曲线:
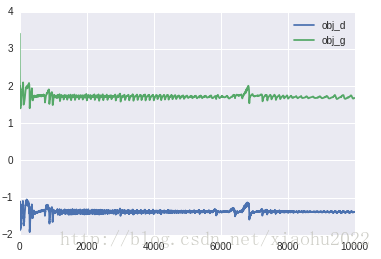
训练之后,
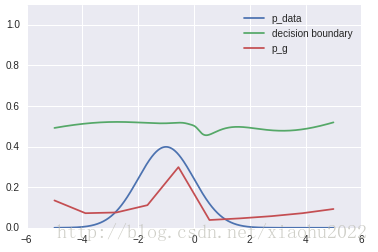
这事就完成了训练过程。
附录
- 这里是一个关于计算不可分性的更生动例子:假设我们在训练一个超级大的神经网络来从猫脸分布中抽样。真实猫脸的隐含(生成)数据分布包含:1)一只正在出生的猫,2)某人最终拍下了这个猫的照片。显然,我们的神经网络并不是要学习这个特殊的生成过程,因为这个过程并没有涉及真实的猫。然而,如果我们的网络能够产生无法与真实的猫图片相区分的图片(在多项式时间计算资源内)那么从某种意义上说这些照片与正常的猫照片一样合法。在图灵测试,密码学与假劳力士的背景下,这值得深思。
- 可以从过拟合的角度看待过量的映射线交叉,学习到的预测或者判别函数已经被样本数据以一种“矛盾”的方式扭曲了(例如,一张猫的照片被分类为狗)。正则化方法可以间接地防止过多的“映射交叉”,但是没有显式地使用排序算法来确保学习到的从
Z 空间到X 空间的映射转化是连续或者对齐的。这种排序机制也许对于提升训练速度非常有效。。。