前言
要理解什么是生成对抗网络,先解释一下有监督学习以及无监督学习:
有监督学习:基于大量带有标签的训练集与测试集的机器学习过程,比如图片分类器需要一系列图片和对应的标签(“猫”,“狗”…)。MNIST手写数字集就是一堆带有标签的训练集与测试集的数据集。
无监督学习:根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题。这就是无监督学习与有监督学习的最大的差别。无监督学习不需要耗费大量的人力去标注训练集,它可以自己从训练集中学习到特征。K-means聚类算法就是其中比较出名的算法之一。
概念——GAN
Ian J. Goodfellow等人于2014年10月在Generative Adversarial Networks中提出了一个通过对抗过程估计生成模型的新框架。框架中同时训练两个模型:捕获数据分布的生成模型G,和估计样本来自训练数据的概率的判别模型D。G的训练程序是将D错误的概率最大化。这个框架对应一个最大值集下限的双方对抗游戏。可以证明在任意函数G和D的空间中,存在唯一的解决方案,使得G重现训练数据分布,而D=0.5。在G和D由多层感知器定义的情况下,整个系统可以用反向传播进行训练。在训练或生成样本期间,不需要任何马尔可夫链或展开的近似推理网络。

该框架就是生成对抗网络(Generative Adversarial Networks,GAN),简单理解就是生成对抗网络中有两个模型——生成器、鉴别器,在训练过程中两个模型相互博弈训练,最后训练成一个能够生成接近真实图片的生成器与一个能够识别真实图片与虚拟图片的鉴别器。
GAN变种——DCGAN
DCGAN是对GAN比较好的改进,其主要的改进是在网络结构上,到目前为,DCGAN极大的提升了GAN训练的稳定性以及生成结果质量。
原始的GAN使用的是多层感知机作为生成器和鉴别器的基本模型(当然,从理论上来说,使用其他模型也可以,只要能完成对应任务),而DCGAN使用卷积神经网络作为生成器和鉴别器的基本模型。当然,这里使用的卷积神经网络不同于平常的卷积神经网络。主要有以下几点改变:

1、取消所有的池化层,G中用转置卷积完成上采样,D中使用跨步卷积代替;
2、生成器和判决器都使用批归一化;
3、去除全连接隐藏层;
4、G中使用ReLU作为激活函数,但输出采用Tanh;
5、鉴别器采用LeakyReLU作为激活函数。
训练过程

如图所示,在训练鉴别器的时候,直接使用D模型进行训练,并为真实数据和生成数据设置不同标签。训练生成器的时候,直接通过整个生成对抗网络来训练,但此时D模型是不可训练的,同时应该将标签设置为1,因为我们希望最终的输出结果是鉴别器将生成的图片识别为真实的图片。
两个模型并不是分别训练的即等D完全训练好后再训练G,他们是同时训练的即D训练完一个batch,G开始训练,G训练完一个batch,D又开始训练,如此往复。
这里只对训练过程做一个简单的概述,详细的训练过程可以参考详解生成对抗网络(GAN)。
代码实现
GAN
首先导入相应的库
import tensorflow as tf
import keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential,Model
from tensorflow.keras.layers import Input,Dense,Dropout,Activation,Flatten
from tensorflow.keras.optimizers import Adam,RMSprop
import numpy as np
import matplotlib.pyplot as plt
import random
然后,导入数据并预处理,这里直接使用MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000,784)
x_test = x_test.reshape(10000,784)
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/255
设置一下噪声的大小
z_dim = 100
设置一下优化器,这里参考的DCGAN论文里所设置的参数
adam = Adam(lr=0.0002,beta_1=0.5)
搭建生成器模型
g = Sequential()
g.add(Dense(256,input_dim=z_dim,activation='relu'))
g.add(Dense(512,activation='relu'))
g.add(Dense(1024,activation='relu'))
g.add(Dense(2048,activation='relu'))
g.add(Dense(784,activation='sigmoid'))
g.compile(loss='binary_crossentropy',optimizer=adam,metrics=['accuracy'])
搭建鉴别器模型,这里先把D模型设置为不可训练,因为我们需要先训练G
d = Sequential()
d.add(Dense(1024,input_dim=784,activation='relu'))
d.add(Dropout(0.3))
d.add(Dense(512,activation='relu'))
d.add(Dropout(0.3))
d.add(Dense(256,activation='relu'))
d.add(Dropout(0.3))
d.add(Dense(64,activation='relu'))
d.add(Dropout(0.3))
d.add(Dense(1,activation='sigmoid'))
d.compile(loss='binary_crossentropy',optimizer=adam,metrics=['accuracy'])
d.trainable = False
把两个模型连接起来组成生成对抗网络
inputs = Input(shape=(z_dim,))
hidden = g(inputs)
output = d(hidden)
gan = Model(inputs,output)
gan.compile(loss='binary_crossentropy',optimizer=adam,metrics=['accuracy'])
写两个函数用于最后输出损失值和生成器生成的图片
def plot_loss(losses):
d_loss = [v[0] for v in losses["D"]]
g_loss = [v[0] for v in losses["G"]]
plt.figure(figsize=(10,8))
plt.plot(d_loss,label="Discriminator_loss")
plt.plot(g_loss,label="Generator_loss")
plt.legend()
plt.show()
def plot_generatored(n_ex=10,dim=(1,10),figsize=(12,2)):
#####
#np.random.seed(time.time())
noise = np.random.normal(0,1,size=(n_ex,z_dim))
generatored_images = g.predict(noise)
generatored_images = generatored_images.reshape(n_ex,28,28)
plt.figure(figsize = figsize)
for i in range(generatored_images.shape[0]):
plt.subplot(dim[0],dim[1],i+1)
plt.imshow(generatored_images[i],interpolation='nearest',cmap='gray_r')
plt.axis('off')
plt.tight_layout()
plt.show()
设置一个字典用于保存损失值
losses = {
"D":[],"G":[]}
下面是train函数
def train(epochs=1,plt_frq=1,BATCH_SIZE=128):
batchCount = int(x_train.shape[0]/BATCH_SIZE)
print("Epochs:",epochs)
print("Batch size:",BATCH_SIZE)
print("Batches per epoch:",batchCount)
for e in range(1,epochs+1):
if e == 1 or e%plt_frq == 0:
print('-'*15,'Epoch %d' %e,'-'*15)
for _ in range(batchCount):
image_batch = x_train[np.random.randint(0,x_train.shape[0],size=BATCH_SIZE)]
########
#np.random.seed(time.time())
noise = np.random.normal(0,1,size=(BATCH_SIZE,z_dim))
generatored_images = g.predict(noise)
#train d
#set data set which is composed of 2 parts
x = np.concatenate((image_batch, generatored_images))
#y are labels
y = np.zeros(2*BATCH_SIZE)
y[:BATCH_SIZE] = 0.9
d.trainable = True
d_loss = d.train_on_batch(x,y)
#train g
#set up data set
noise = np.random.normal(0,1,size=(BATCH_SIZE,z_dim))
y2 = np.ones(BATCH_SIZE)
d.trainable = False
g_loss = gan.train_on_batch(noise,y2)
losses["D"].append(d_loss)
losses["G"].append(g_loss)
if e==1 or e%plt_frq==0:
plot_generatored()
plot_loss(losses)
然后就可以开始训练了
train(200,20,128)
由于我之前的训练数据丢失了,所以这里就不展示GAN的结果了。
DCGAN
我这里没办法完全复制论文的结果,仅通过论文中提到的几点然后改造自己之前使用的卷积神经网络来替换上面代码里面使用的神经网络。
首先依旧是导入相关库,但这里相对于上面有些层不需要了
import tensorflow as tf
import keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential,Model
from tensorflow.keras.layers import Input,Dense,Dropout,Activation,Flatten,Conv2D,Conv2DTranspose,BatchNormalization,LeakyReLU
from tensorflow.keras.optimizers import Adam,RMSprop
import numpy as np
import matplotlib.pyplot as plt
然后同样是导入数据,并预处理
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000,784)
x_test = x_test.reshape(10000,784)
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/255
设置噪声维度,这里使用的噪声维度与上面不同,我在之前学习自编码器的时候发现数据集中使用4*4*8的维度对手写数字图片的还原程度挺好的,所以在这里也设置成这个维度。
z_dim = (4,4,8)
设置优化器,同上
adam = Adam(lr=0.0002,beta_1=0.5)
搭建生成器模型
g = Sequential()
g.add(Conv2DTranspose(8,(5,5),activation='relu',input_shape=z_dim))
g.add(BatchNormalization())
g.add(Conv2DTranspose(8,(5,5),activation='relu',strides=2,padding='same'))
g.add(BatchNormalization())
g.add(Conv2DTranspose(32,(5,5),activation='relu'))
g.add(BatchNormalization())
g.add(Conv2DTranspose(64,(5,5),activation='relu'))
g.add(Conv2DTranspose(1,(5,5),activation='tanh'))
g.compile(loss='binary_crossentropy',optimizer=adam,metrics=['accuracy'])
g.summary()
:这是G模型的结构

搭建鉴别器
d = Sequential()
d.add(Conv2D(32, (5,5),input_shape=(28, 28, 1)))
d.add(LeakyReLU(alpha=0.2))
d.add(BatchNormalization())
d.add(Conv2D(64, (5,5)))
d.add(LeakyReLU(alpha=0.2))
d.add(Flatten())
d.add(Dense(128))
d.add(LeakyReLU(alpha=0.2))
d.add(BatchNormalization())
d.add(Dense(1, activation='softmax'))
d.compile(loss='categorical_crossentropy', optimizer=adam, metrics = ['accuracy'])#定义损失值、优化器
d.trainable=False
d.summary()
:这是鉴别器的结构

同样,组合两模型成生成对抗网络
inputs = Input(shape=(z_dim[0],z_dim[1],z_dim[2],))
hidden = g(inputs)
output = d(hidden)
gan = Model(inputs,output)
gan.compile(loss='binary_crossentropy',optimizer=adam,metrics=['accuracy'])
gan.summary()
两个函数,绘制损失值和生成器图像
def plot_loss(losses):
d_loss = [v[0] for v in losses["D"]]
g_loss = [v[0] for v in losses["G"]]
plt.figure(figsize=(10,8))
plt.plot(d_loss,label="Discriminator_loss")
plt.plot(g_loss,label="Generator_loss")
plt.legend()
plt.show()
def plot_generatored(n_ex=10,dim=(1,10),figsize=(12,2)):
noise = np.random.normal(0,1,size=(n_ex,z_dim[0],z_dim[1],z_dim[2]))
generatored_images = g.predict(noise)
generatored_images = generatored_images.reshape(n_ex,28,28)
plt.figure(figsize = figsize)
for i in range(generatored_images.shape[0]):
plt.subplot(dim[0],dim[1],i+1)
plt.imshow(generatored_images[i],interpolation='nearest',cmap='gray_r')
plt.axis('off')
plt.tight_layout()
plt.show()
设置一个字典,同上
losses = {
"D":[],"G":[]}
train函数,同上
def train(epochs=1,plt_frq=1,BATCH_SIZE=128):
batchCount = int(x_train.shape[0]/BATCH_SIZE)
print("Epochs:",epochs)
print("Batch size:",BATCH_SIZE)
print("Batches per epoch:",batchCount)
for e in range(1,epochs+1):
if e == 1 or e%plt_frq == 0:
print('-'*15,'Epoch %d' %e,'-'*15)
for _ in range(batchCount):
image_batch = x_train[np.random.randint(0,x_train.shape[0],size=BATCH_SIZE)]
noise = np.random.normal(0,1,size=(BATCH_SIZE,z_dim[0],z_dim[1],z_dim[2]))
generatored_images = g.predict(noise)
#train d
#set data set which is composed of 2 parts
x = np.concatenate((np.reshape(image_batch,(-1,28,28,1)), generatored_images))
#y are labels
y = np.zeros(2*BATCH_SIZE)
y[:BATCH_SIZE] = 0.9
d.trainable = True
d_loss = d.train_on_batch(x,y)
#train g
#set up data set
noise = np.random.normal(0,1,size=(BATCH_SIZE,z_dim[0],z_dim[1],z_dim[2]))
y2 = np.ones(BATCH_SIZE)
d.trainable = False
g_loss = gan.train_on_batch(noise,y2)
losses["D"].append(d_loss)
losses["G"].append(g_loss)
if e==1 or e%plt_frq==0:
plot_generatored()
plot_loss(losses)
然后就可以开始训练了
train(100,10,128)
结果展示
这是第一轮生成的图像:

挺乱的,看不出啥,可能是我的网络模型设置的不好。
10轮之后
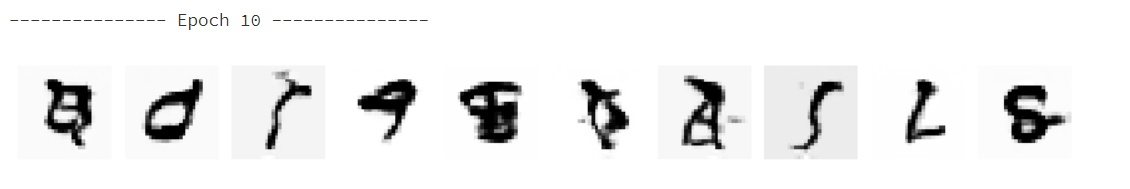
现在稍微能看出点啥了,但还是很乱
100轮

这下基本能够看出点东西了,9、7、6、5都有比较强的辨识度了。
总结
我最开始训练DCGAN的时候,直接使用了平常常用的卷积神经网络,包括卷积池化等等,生成器也是用的上采样而不是转置卷积。那时候电脑不仅训练时间非常长容易崩溃,而且结果非常的不理想。
所有代码已经发布在和鲸社区点击直达,可以在上面直接运行。
写博客的时候参考了很多大佬的博客以及GAN和DCGAN的原始论文部分贴在下面:
博客里的图片也来自于此。
详解生成对抗网络(GAN)
GAN生成对抗网络
论文:
GAN
DCGAN