原文:Factorization Machines
地址:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.393.8529&rep=rep1&type=pdf
一、问题由来
在计算广告和推荐系统中,CTR预估(click-through rate)是非常重要的一个环节,判断一个商品的是否进行推荐需要根据CTR预估的点击率来进行。传统的逻辑回归模型是一种广义线性模型,非常容易实现大规模实时并行处理,因此在工业界获得了广泛应用,但是线性模型的学习能力有限,不能捕获高阶特征(非线性信息),而在进行CTR预估时,除了单特征外,往往要对特征进行组合。对于特征组合来说,业界现在通用的做法主要有两大类:FM系列与DNN系列。今天,我们就来分享下FM算法。
二、为什么需要FM
1、特征组合是许多机器学习建模过程中遇到的问题,如果对特征直接建模,很有可能会忽略掉特征与特征之间的关联信息,因此,可以通过构建新的交叉特征这一特征组合方式提高模型的效果。
2、高维的稀疏矩阵是实际工程中常见的问题,并直接会导致计算量过大,特征权值更新缓慢。试想一个10000*100的表,每一列都有8种元素,经过one-hot独热编码之后,会产生一个10000*800的表。因此表中每行元素只有100个值为1,700个值为0。特征空间急剧变大,以淘宝上的item为例,将item进行one-hot编码以后,样本空间有一个categorical变为了百万维的数值特征,特征空间一下子暴增一百万。所以大厂动不动上亿维度,就是这么来的。
而FM的优势就在于对这两方面问题的处理。首先是特征组合,通过对两两特征组合,引入交叉项特征,提高模型得分;其次是高维灾难,通过引入隐向量(对参数矩阵进行矩阵分解),完成对特征的参数估计。
三、原理及求解
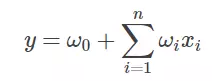
其中w0 为初始权值,或者理解为偏置项,wi 为每个特征xi 对应的权值。可以看到,这种线性表达式只描述了每个特征与输出的关系。
FM的表达式如下,可观察到,只是在线性表达式后面加入了新的交叉项特征及对应的权值。

求解过程 :
从上面的式子可以很容易看出,组合部分的特征相关参数共有n(n−1)/2个。但是如第二部分所分析,在数据很稀疏的情况下,满足xi,xj都不为0的情况非常少,这样将导致ωij无法通过训练得出。
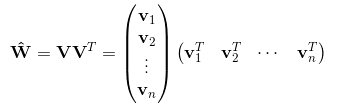
为了求出ωij,我们对每一个特征分量xi引入辅助向量Vi=(vi1,vi2,⋯,vik)。然后,利用vivj^T对ωij进行求解:

那么ωij组成的矩阵可以表示为:
那么,如何求解vi和vj呢?主要采用了公式:
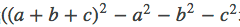
具体推导过程如下:

四、参数求解
利用梯度下降法,通过求损失函数对特征(输入项)的导数计算出梯度,从而更新权值。设m为样本个数,θ为权值。

其中,是和i无关的,可以事先求出来。每个梯度都可以在O(1)时间内求得,整体的参数更新的时间为O(kn)。