版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_35564813/article/details/86506104
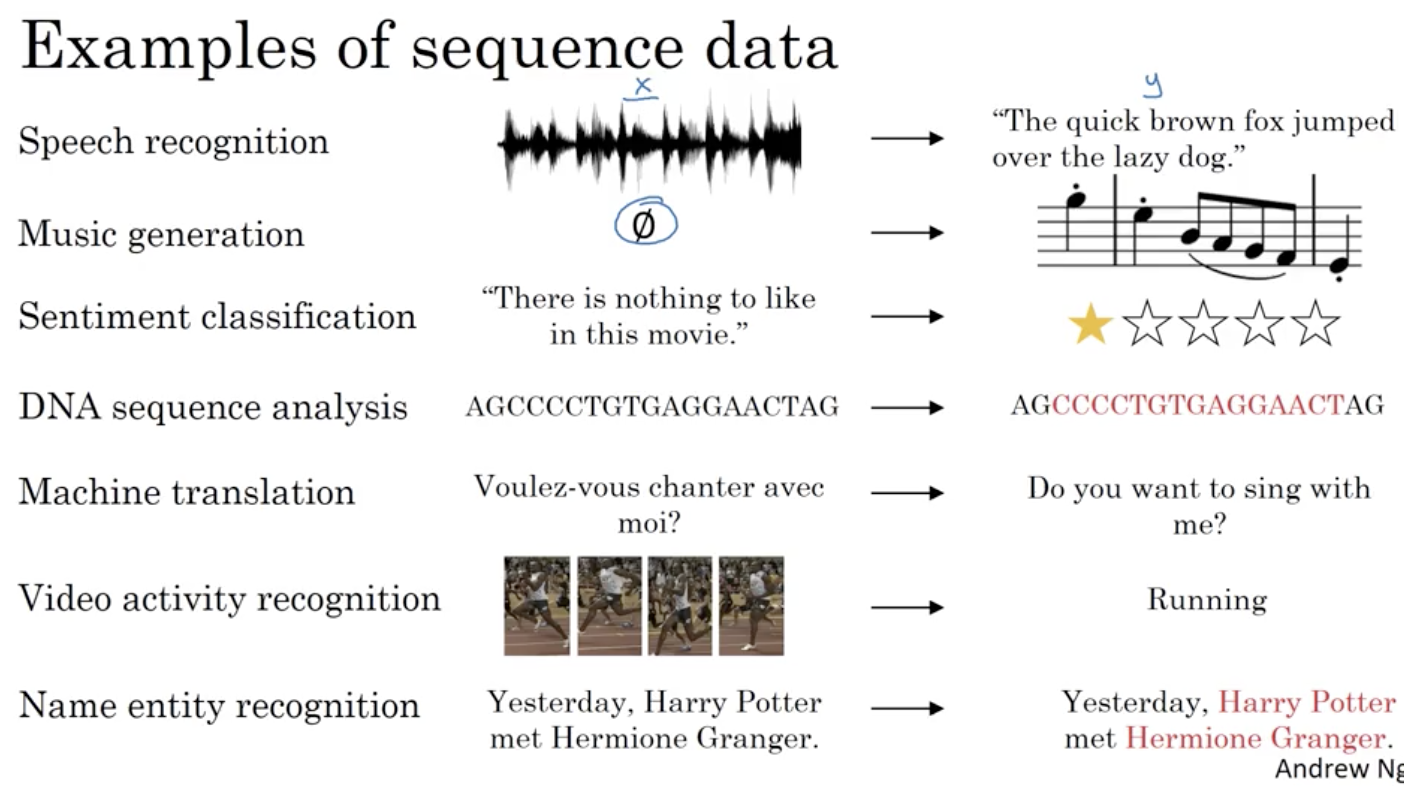
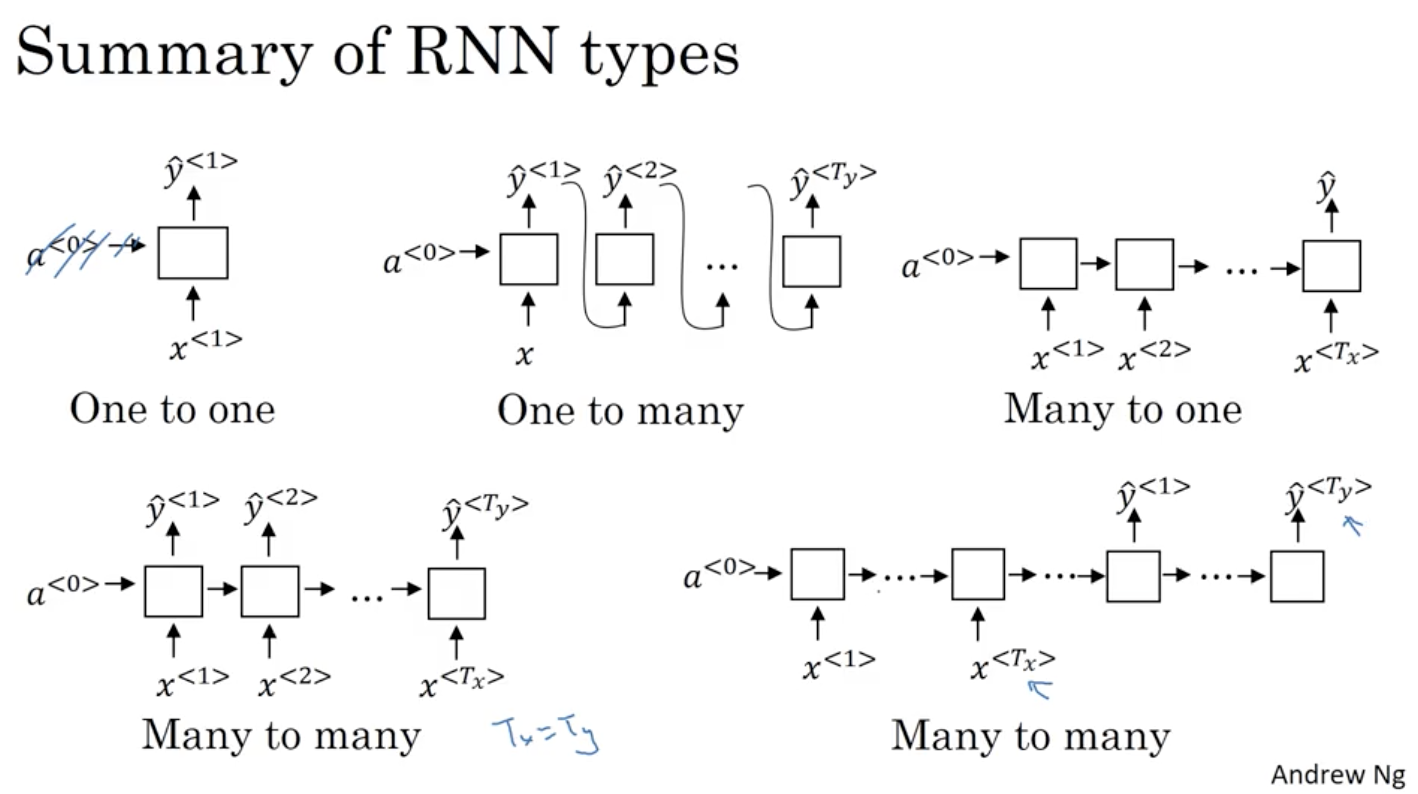
这些序列模型基本都属于监督式学习,输入x和输出y不一定都是序列模型。如果都是序列模型的话,模型长度不一定完全一致。
输入x:如“Harry Potter and Herminone Granger invented a new spell.”(以序列作为一个输入),
x
<
t
>
x^{<t>}
x < t >
输出y:如“1 1 0 1 1 0 0 0 0”(人名定位),同样,用
y
<
t
>
y^{<t>}
y < t >
T
x
T_x
T x
T
y
T_y
T y
x
(
i
)
<
t
>
x^{(i)<t>}
x ( i ) < t > 利用单词字典编码来表示每一个输入的符号:如one-hot编码等,实现输入x和输出y之间的映射关系。
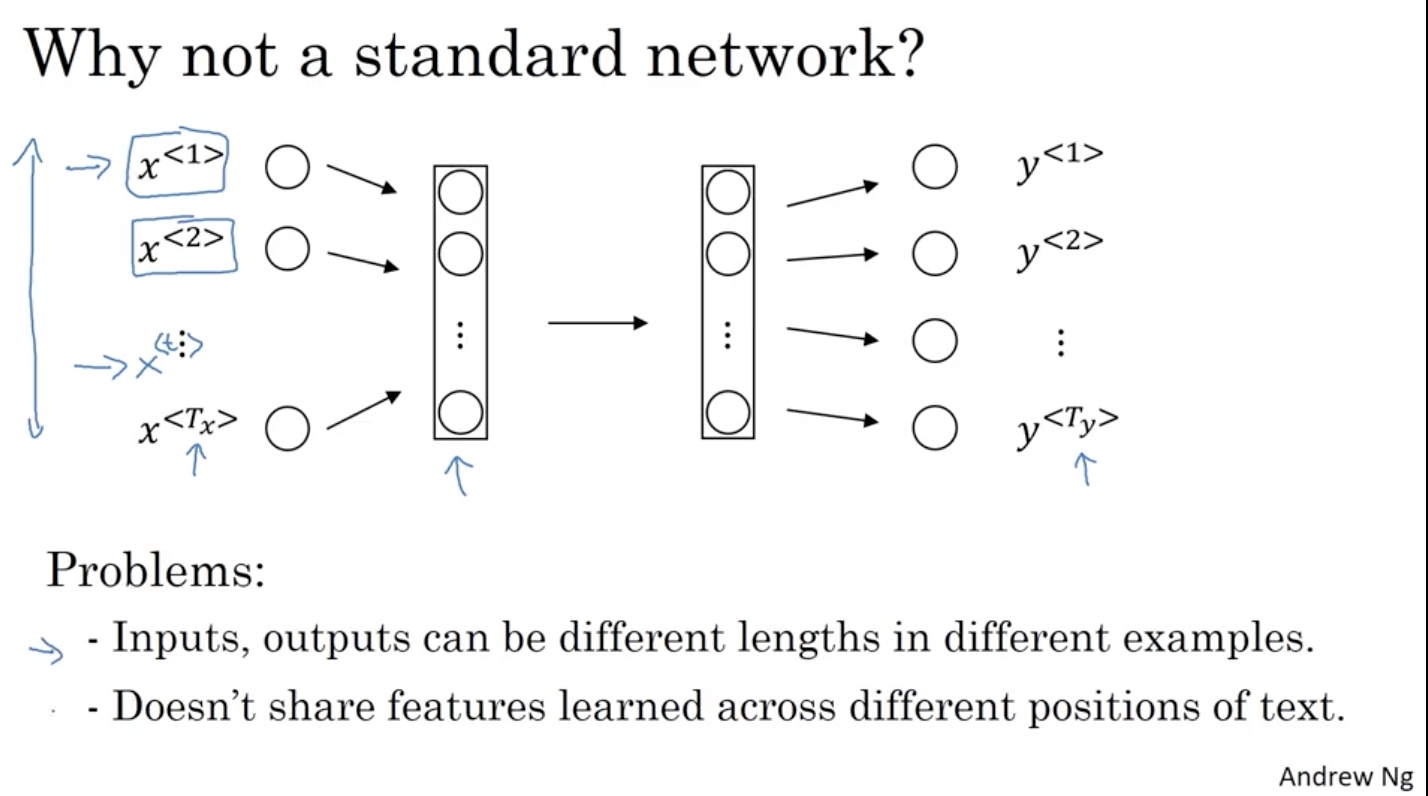
传统标准的神经网络 :
对于学习X和Y的映射,我们可以很直接的想到一种方法就是使用传统的标准神经网络。也许我们可以将输入的序列X以某种方式进行字典编码以后,如one-hot编码,输入到一个多层的深度神经网络中,最后得到对应的输出Y。如下图所示:
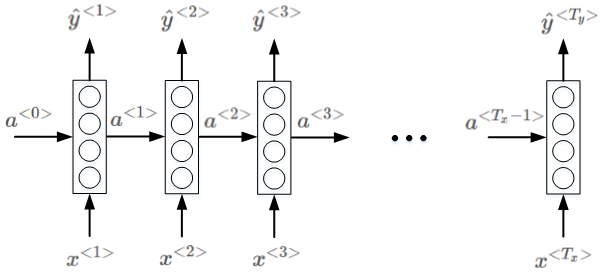
循环神经网络:
循环神经网络作为一种新型的网络结构,在处理序列数据问题上则不存在上面的两个缺点。如下图所示:
序列模型从左到右,依次传递,此例中,
T
x
=
T
y
T_x=T_y
T x = T y
x
<
t
>
x^{<t>}
x < t >
y
^
<
t
>
\hat{y}^{<t>}
y ^ < t >
a
<
t
>
a^{<t>}
a < t >
a
<
0
>
a^{<0>}
a < 0 >
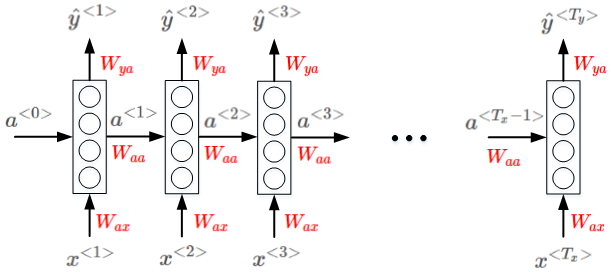
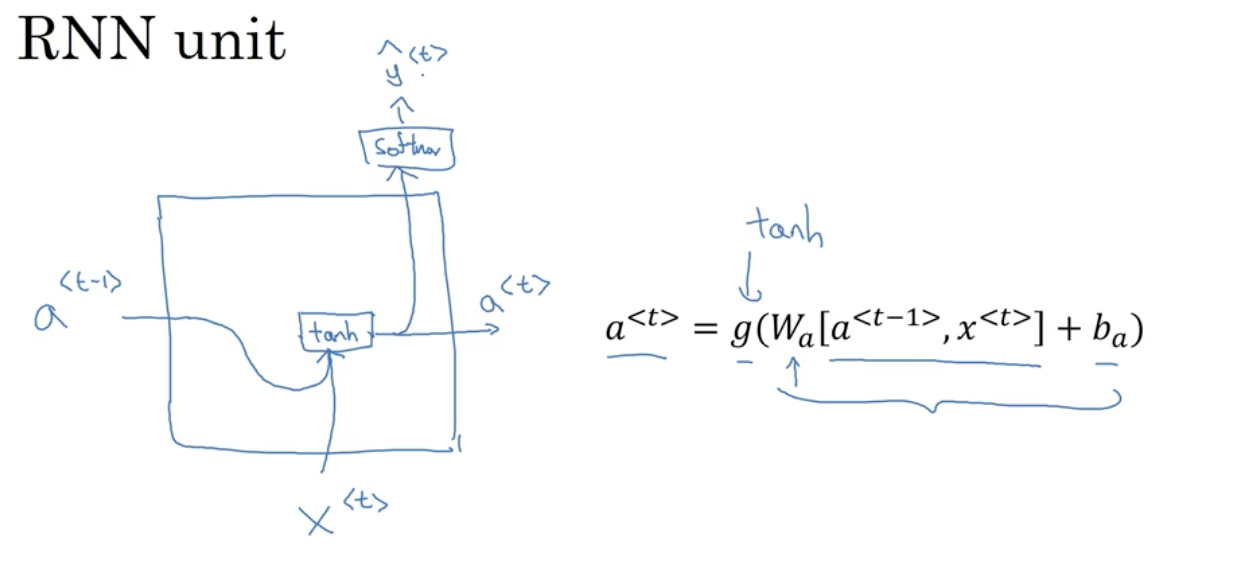
RNN模型包含三类权重系数,分别是
W
a
x
,
W
a
a
,
W
y
a
W_{ax},W_{aa},W_{ya}
W a x , W a a , W y a
RNN的正向传播(Forward Propagation)过程为:
a
<
t
>
=
g
(
W
a
a
⋅
a
<
t
−
1
>
+
W
a
x
⋅
x
<
t
>
+
b
a
)
a^{<t>}=g(W_{aa}⋅a^{<t−1>}+W_{ax}⋅x^{<t>}+b_a)
a < t > = g ( W a a ⋅ a < t − 1 > + W a x ⋅ x < t > + b a )
y
^
<
t
>
=
g
(
W
y
a
⋅
a
<
t
>
+
b
y
)
\hat{y}^{<t>}=g(W_{ya}⋅a^{<t>}+b_y)
y ^ < t > = g ( W y a ⋅ a < t > + b y )
a
<
t
>
a^{<t>}
a < t >
W
a
a
⋅
a
<
t
−
1
>
+
W
a
x
⋅
x
<
t
>
=
[
W
a
a
W
a
x
]
[
a
[
t
−
1
]
x
<
t
>
]
→
W
a
[
a
<
t
−
1
>
,
x
<
t
>
]
W_{aa}\cdot a^{<t-1>}+W_{ax}\cdot x^{<t>}=[W_{aa}\ \ W_{ax}]\begin{bmatrix}a^{[t-1]} \\x^{<t>}\end{bmatrix}\to\ W_a[a^{<t-1>},x^{<t>}]
W a a ⋅ a < t − 1 > + W a x ⋅ x < t > = [ W a a W a x ] [ a [ t − 1 ] x < t > ] → W a [ a < t − 1 > , x < t > ]
则正向传播可表示为:
a
<
t
>
=
g
(
W
a
[
a
<
t
−
1
,
x
<
t
>
]
+
b
a
)
a^{<t>}=g(W_a[a^{<t-1},x^{<t>}]+b_a)
a < t > = g ( W a [ a < t − 1 , x < t > ] + b a )
y
^
<
t
>
=
g
(
W
y
⋅
a
<
t
>
+
b
y
)
\hat{y}^{<t>}=g(W_y \cdot a^{<t>}+b_y)
y ^ < t > = g ( W y ⋅ a < t > + b y )
针对上面识别人名的例子,经过RNN正向传播,单个元素的Loss function为:
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
=
−
y
<
t
>
l
o
g
y
^
<
t
>
−
(
1
−
y
<
t
>
)
l
o
g
(
1
−
y
^
<
t
>
)
L^{<t>}(ŷ^{<t>},y^{<t>})=−y^{<t>}logŷ^{<t>}−(1−y^{<t>})log (1−ŷ^{<t>})
L < t > ( y ^ < t > , y < t > ) = − y < t > l o g y ^ < t > − ( 1 − y < t > ) l o g ( 1 − y ^ < t > )
L
(
y
^
,
y
)
=
∑
t
=
1
T
y
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
L(ŷ ,y)=\sum_{t=1}^TyL^{<t>}(ŷ^{<t>},y^{<t>})
L ( y ^ , y ) = ∑ t = 1 T y L < t > ( y ^ < t > , y < t > )
W
a
,
W
y
,
b
a
,
b
y
W_a,W_y,b_a,b_y
W a , W y , b a , b y
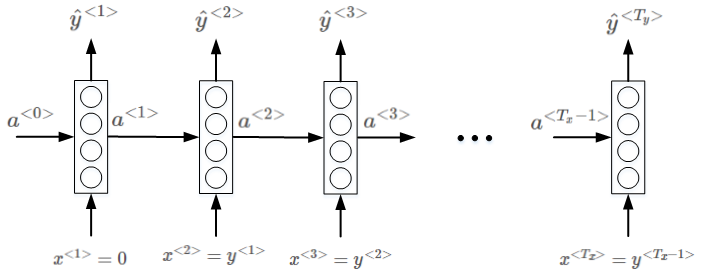
上图左下角many to many 模型是
T
x
=
T
y
T_x=T_y
T x = T y
T
x
≠
T
y
T_x\neq T_y
T x ̸ = T y
在NLP中,构建语言模型是最基础也是最重要的工作之一,我们可以通过RNN来很好的实现。
The apple and pair salad.
The apple and pear salad.
很明显,第二句话更有可能是正确的翻译。语言模型实际上会计算出这两句话各自的出现概率。比如第一句话概率为
1
0
−
13
10^{−13}
1 0 − 1 3
1
0
−
10
10^{−10}
1 0 − 1 0
P
(
y
<
1
>
,
y
<
2
>
,
.
.
.
.
,
y
<
T
y
>
)
P(y^{<1>},y^{<2>},....,y^{<T_y>})
P ( y < 1 > , y < 2 > , . . . . , y < T y > ) The Egyptian Mau is a bread of cat. The Egyptian < UNK > is a bread of cat. < EOS >
语言模型的RNN结构如上图所示,
x
<
1
>
x^{<1>}
x < 1 >
a
<
0
>
a^{<0>}
a < 0 >
y
^
<
1
>
\hat{y}^{<1>}
y ^ < 1 >
y
^
<
2
>
\hat{y}^{<2>}
y ^ < 2 >
单个元素的softmax loss function为:
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
=
−
∑
i
y
i
<
t
>
l
o
g
y
^
i
<
t
>
L^{<t>}(\hat{y}^{<t>},y^{<t>})=−\sum_iy^{<t>}_ilog\hat{y}^{<t>}_i
L < t > ( y ^ < t > , y < t > ) = − ∑ i y i < t > l o g y ^ i < t >
L
(
y
^
,
y
)
=
∑
t
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
L(\hat{y} ,y)=\sum_tL^{<t>}(\hat{y}^{<t>},y^{<t>})
L ( y ^ , y ) = ∑ t L < t > ( y ^ < t > , y < t > )
最后补充一点,整个语句出现的概率等于语句中所有元素出现的条件概率乘积。例如某个语句包含
y
<
1
>
,
y
<
2
>
,
y
<
3
>
y^{<1>},y^{<2>},y^{<3>}
y < 1 > , y < 2 > , y < 3 >
P
(
y
<
1
>
,
y
<
2
>
,
y
<
3
>
)
=
P
(
y
<
1
>
)
⋅
P
(
y
<
2
>
∣
y
<
1
>
)
⋅
P
(
y
<
3
>
∣
y
<
1
>
,
y
<
2
>
)
P(y^{<1>},y^{<2>},y^{<3>})=P(y^{<1>})⋅P(y^{<2>}|y^{<1>})⋅P(y^{<3>}|y^{<1>},y^{<2>})
P ( y < 1 > , y < 2 > , y < 3 > ) = P ( y < 1 > ) ⋅ P ( y < 2 > ∣ y < 1 > ) ⋅ P ( y < 3 > ∣ y < 1 > , y < 2 > )
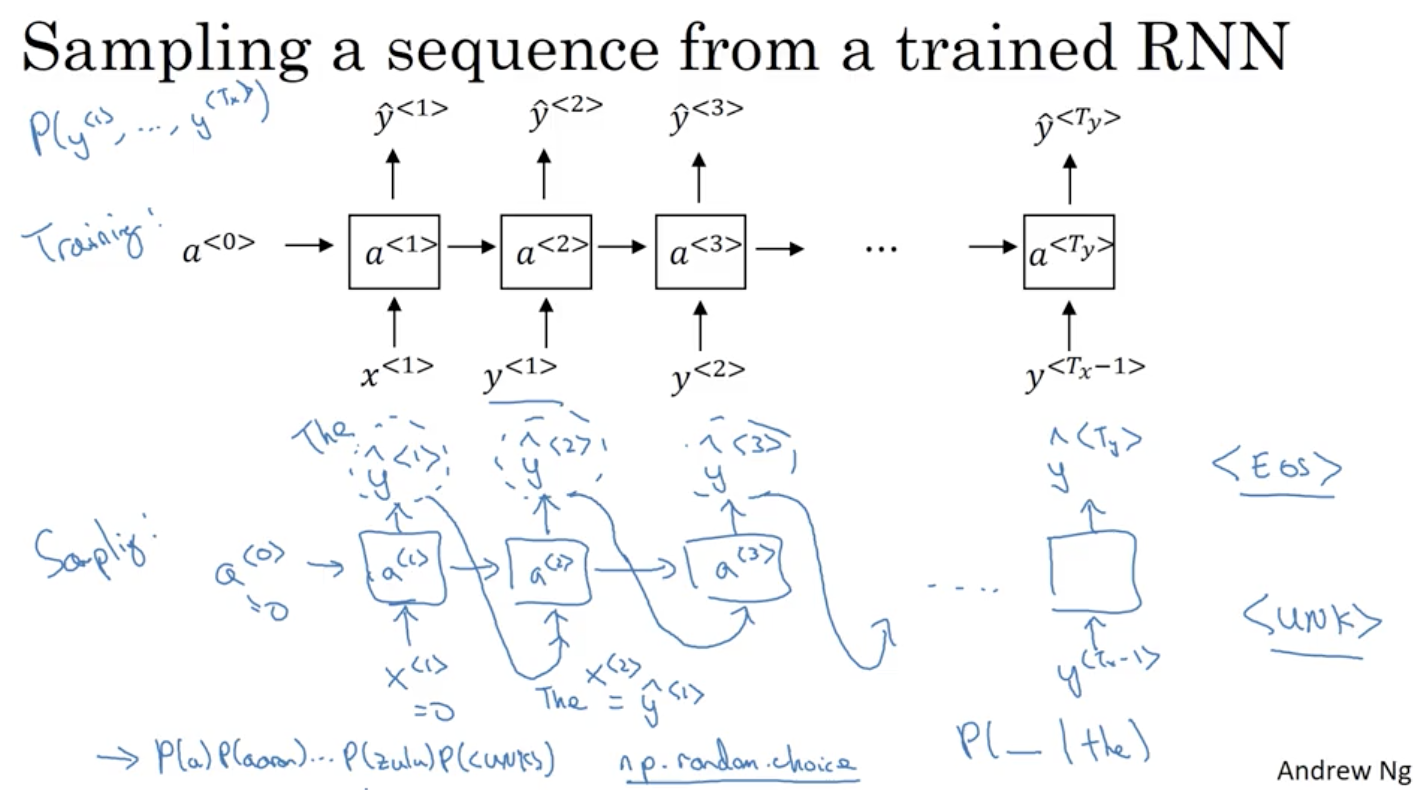
利用训练好的RNN语言模型,可以进行新的序列采样,从而随机产生新的语句。与上一节介绍的一样,相应的RNN模型如下所示:
首先输入
x
<
1
>
=
0
,
a
<
0
>
=
0
x^{<1>}=0,a^{<0>}=0
x < 1 > = 0 , a < 0 > = 0
y
^
<
1
>
\hat{y}^{<1>}
y ^ < 1 >
然后继续下一个时间戳,我们以刚刚采样得到的
y
^
<
1
>
\hat{y}^{<1>}
y ^ < 1 >
y
^
<
2
>
\hat{y}^{<2>}
y ^ < 2 >
如果字典中有结束的标志如:“EOS”,那么输出是该符号时则表示结束;若没有这种标志,则我们可以自行设置结束的时间戳。
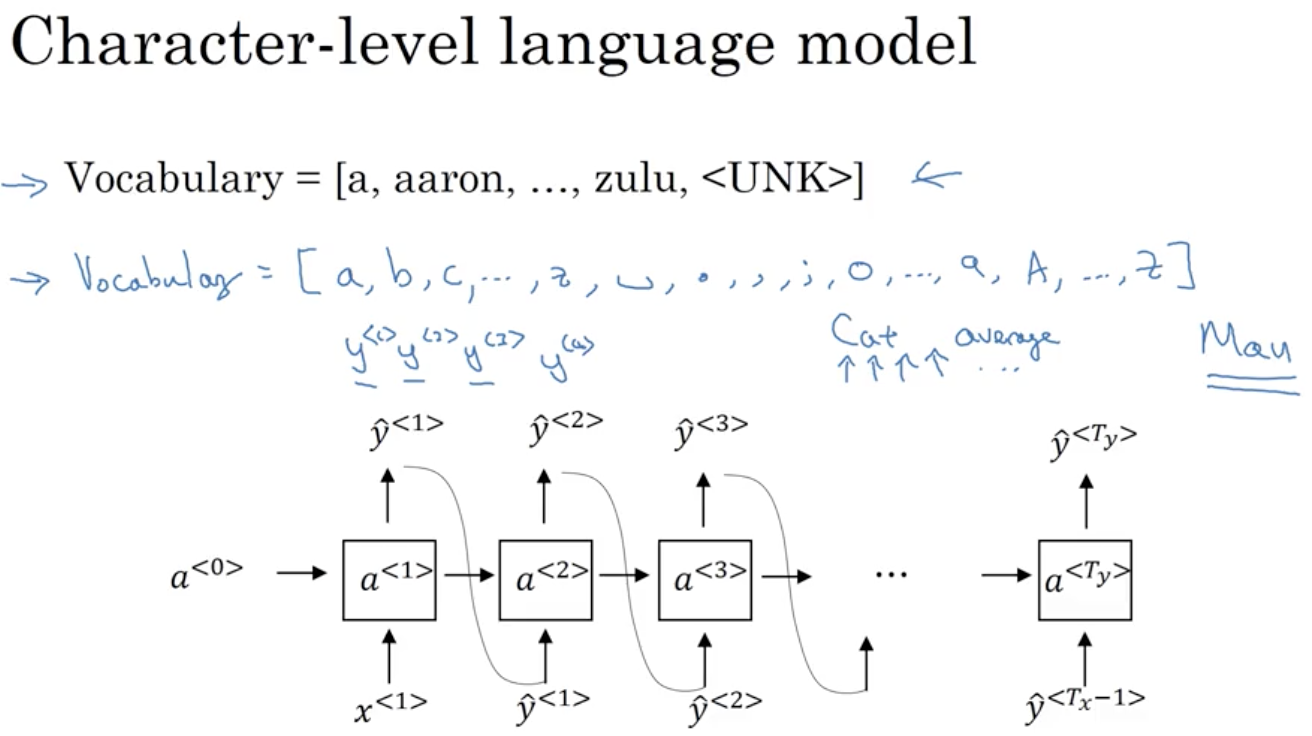
上面的模型是基于词汇的语言模型,我们还可以构建基于字符的语言模型,其中每个单词和符号则表示一个相应的输入或者输出:
character level RNN的优点是能有效避免遇到词汇表中不存在的单词< UNK >。但是,character level RNN的缺点也很突出。由于是字符表征,每句话的字符数量很大,这种大的跨度不利于寻找语句前部分和后部分之间的依赖性。另外,character level RNN的在训练时的计算量也是庞大的。基于这些缺点,目前character level RNN的应用并不广泛,但是在特定应用下仍然有发展的趋势。
语句中可能存在跨度很大的依赖关系,即某个word可能与它距离较远的某个word具有强依赖关系。例如下面这两条语句:
The cat, which already ate fish, was full.
The cats, which already ate fish, were full.
第一句话中,was受cat影响;第二句话中,were受cats影响。它们之间都跨越了很多单词。而一般的RNN模型每个元素受其周围附近的影响较大,难以建立跨度较大的依赖性。上面两句话的这种依赖关系,由于跨度很大,普通的RNN网络容易出现梯度消失,捕捉不到它们之间的依赖,造成语法错误。
另一方面,RNN也可能出现梯度爆炸的问题,即gradient过大。常用的解决办法是设定一个阈值,一旦梯度最大值达到这个阈值,就对整个梯度向量进行尺度缩小。这种做法被称为gradient clipping。
RNN的隐藏层单元结构如下图所示:
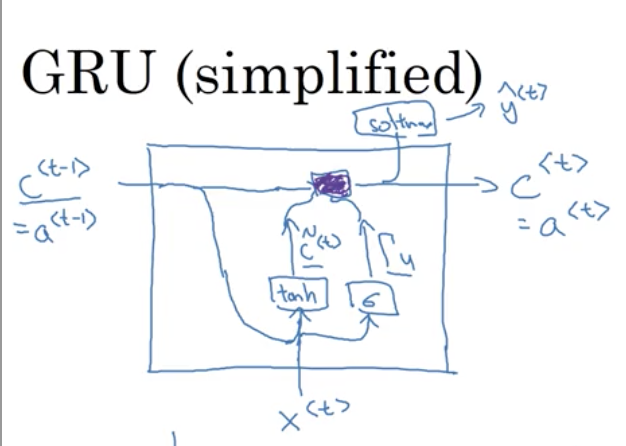
为了解决梯度消失问题,对上述单元进行修改,添加了记忆单元,构建GRU,如下图所示:
相应的表达式为:
c
~
<
t
>
=
t
a
n
h
(
W
c
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
\tilde{c}^{<t>}=tanh(W_c[c^{<t-1>},x^{<t>}]+b_c)
c ~ < t > = t a n h ( W c [ c < t − 1 > , x < t > ] + b c )
Γ
u
=
σ
(
W
u
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
\Gamma_u=\sigma(W_u[c^{<t-1>},x^{<t>}]+b_u)
Γ u = σ ( W u [ c < t − 1 > , x < t > ] + b u )
c
<
t
>
=
Γ
u
∗
c
~
<
t
>
+
(
1
−
Γ
u
)
∗
c
<
t
−
1
>
c^{<t>}=\Gamma_u\ * \tilde{c}^{<t>}+(1-\Gamma_u)\ *c^{<t-1>}
c < t > = Γ u ∗ c ~ < t > + ( 1 − Γ u ) ∗ c < t − 1 >
其中
c
<
t
−
1
>
=
a
<
t
−
1
>
,
c
<
t
>
=
a
<
t
>
c^{<t-1>}=a^{<t-1>},c^{<t>}=a^{<t>}
c < t − 1 > = a < t − 1 > , c < t > = a < t >
Γ
u
\Gamma_u
Γ u
Γ
u
=
1
\Gamma_u=1
Γ u = 1
Γ
u
\Gamma_u
Γ u
Γ
u
\Gamma_u
Γ u
上面介绍的是简化版的GRU模型,完整的GRU添加了另外一个gate,即
Γ
r
\Gamma_r
Γ r
c
~
<
t
>
=
t
a
n
h
(
Γ
r
∗
W
c
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
\tilde{c}^{<t>}=tanh(\Gamma_r\ *W_c[c^{<t-1>},x^{<t>}]+b_c)
c ~ < t > = t a n h ( Γ r ∗ W c [ c < t − 1 > , x < t > ] + b c )
Γ
u
=
σ
(
W
u
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
\Gamma_u=\sigma(W_u[c^{<t-1>},x^{<t>}]+b_u)
Γ u = σ ( W u [ c < t − 1 > , x < t > ] + b u )
Γ
r
=
σ
(
W
r
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
r
)
\Gamma_r=\sigma(W_r[c^{<t-1>},x^{<t>}]+b_r)
Γ r = σ ( W r [ c < t − 1 > , x < t > ] + b r )
c
<
t
>
=
Γ
u
∗
c
~
<
t
>
+
(
1
−
Γ
u
)
∗
c
<
t
−
1
>
c^{<t>}=\Gamma_u\ * \tilde{c}^{<t>}+(1-\Gamma_u)\ *c^{<t-1>}
c < t > = Γ u ∗ c ~ < t > + ( 1 − Γ u ) ∗ c < t − 1 >
LSTM是另一种更强大的解决梯度消失问题的方法。它对应的RNN隐藏层单元结构如下图所示:
相应的表达式为:
c
~
<
t
>
=
t
a
n
h
(
W
c
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
\tilde{c}^{<t>}=tanh(W_c[a^{<t-1>},x^{<t>}]+b_c)
c ~ < t > = t a n h ( W c [ a < t − 1 > , x < t > ] + b c )
Γ
u
=
σ
(
W
u
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
\Gamma_u=\sigma(W_u[a^{<t-1>},x^{<t>}]+b_u)
Γ u = σ ( W u [ a < t − 1 > , x < t > ] + b u )
Γ
f
=
σ
(
W
f
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
f
)
\Gamma_f=\sigma(W_f[a^{<t-1>},x^{<t>}]+b_f)
Γ f = σ ( W f [ a < t − 1 > , x < t > ] + b f )
Γ
o
=
σ
(
W
o
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
o
)
\Gamma_o=\sigma(W_o[a^{<t-1>},x^{<t>}]+b_o)
Γ o = σ ( W o [ a < t − 1 > , x < t > ] + b o )
c
<
t
>
=
Γ
u
∗
c
~
<
t
>
+
Γ
f
∗
c
<
t
−
1
>
c^{<t>}=\Gamma_u\ * \tilde{c}^{<t>}+\Gamma_f\ *c^{<t-1>}
c < t > = Γ u ∗ c ~ < t > + Γ f ∗ c < t − 1 >
a
<
t
>
=
Γ
o
∗
c
<
t
>
a^{<t>}=\Gamma_o\ *c^{<t>}
a < t > = Γ o ∗ c < t >
GRU可以看成是简化的LSTM,两种方法都具有各自的优势。
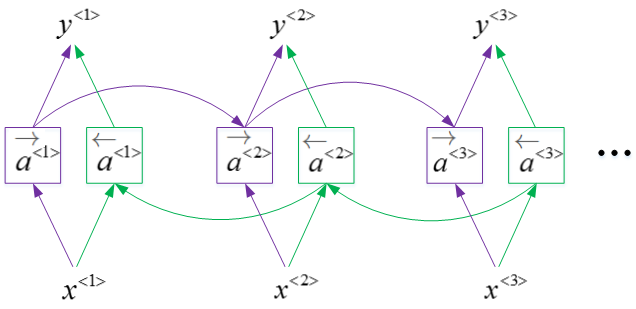
BRNN对应的输出
y
<
t
>
y^{<t>}
y < t >
y
^
<
t
>
=
g
(
W
y
[
a
→
<
t
>
,
a
←
<
t
>
]
+
b
y
)
\hat{y}^{<t>}=g(W_y[\overrightarrow{a}^{<t>},\overleftarrow{a}^{<t>}]+b_y)
y ^ < t > = g ( W y [ a
< t > , a
< t > ] + b y )
BRNN能够同时对序列进行双向处理,性能大大提高。但是计算量较大,且在处理实时语音时,需要等到完整的一句话结束时才能进行分析。
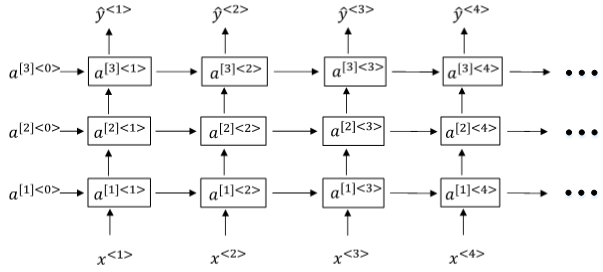
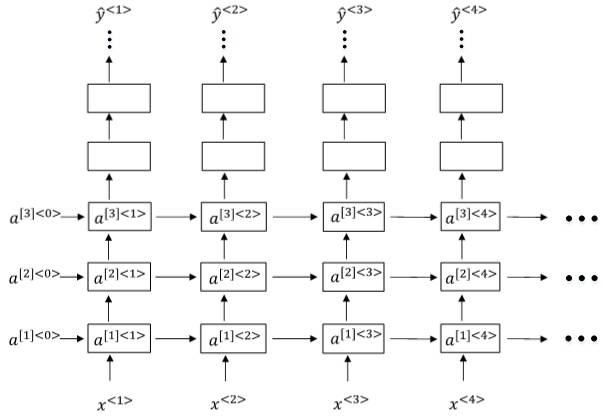
Deep RNNs由多层RNN组成,其结构如下图所示:
与DNN一样,用上标[l][l]表示层数。Deep RNNs中
a
[
l
]
<
t
>
a^{[l]<t>}
a [ l ] < t >
a
[
l
]
<
t
>
=
g
(
W
a
[
l
]
[
a
[
l
]
<
t
−
1
>
,
a
[
l
−
1
]
<
t
>
]
+
b
a
[
l
]
)
a^{[l]<t>}=g(W^{[l]}_a[a^{[l]<t−1>},a^{[l−1]<t>}]+b^{[l]}_a)
a [ l ] < t > = g ( W a [ l ] [ a [ l ] < t − 1 > , a [ l − 1 ] < t > ] + b a [ l ] )
另外一种Deep RNNs结构是每个输出层上还有一些垂直单元,如下图所示: