目录
BinaryNet:通过权重和激活约束为+1或-1训练深度神经网络
摘要
我们提出了BinaryNet,它是一种当计算参数的梯度时,可以用二进化权重和激活值训练DNN的方法。我们证明了可以用BinaryNet在MNIST上训练多层感知器,也可以在CIFAR-10和SNHN的训练ConvNets,并实现相当好的结果。 在运行时,BinaryNet大幅减少内存使用量并用1位异或非或(XNOR)运算替换大多数乘法运算,可能对通用和专用的深度学习硬件上产生重大影响。我们写了一个二进制矩阵乘法GPU内核,可以比未经优化的GPU内核的运行MNIST MLP快7倍,同时不会损失分类准确度。BinaryNet代码开源。
引言
深度神经网络(DNN)已在广泛的任务大幅推进人工智能(AI)应用范围,包括但不限于图像中的物体识别(Krizhevsky等,2012; Szegedy等,2014),语音识别(Hinton等,2012; Sainath等,2013),统计机器翻译(Devlin et al。,2014; Sutskever)等,2014; Bahdanau等,2015),Atari和围棋游戏(Mnih等,2015; Silver等,2016),甚至是抽象艺术(Mordvintsev等,2015)。
如今,DNN几乎全部在一个或多个非常快速和耗电的图形处理单位(GPU)接受训练(Coates等,2013)。因此,在目标低功耗设备上运行DNNs通常是一个挑战,并且大量研究工作希望通过一些通用方法和专业计算机硬件在运行时加速DNN的训练(Vanhoucke et al。,2011; Gong等,2014; Romero等,2014; Han et al。,2015)(Farabet等,2011a; b; Pham等人,2012; Chen等,2014a; b; Esser等,2015)。
我们认为,我们文章的贡献如下:
• 我们提出了BinaryNet,它是一种当计算参数的梯度时,可以用二进化权重和激活值训练DNN的方法(见第1节)。
• 我们证明了可以用BinaryNet在MNIST上训练多层感知器,也可以在CIFAR-10和SNHN的训练ConvNets,并实现相当好的结果(见第2节)。
• 我们表明,在运行时,BinaryNet大幅减少了内存使用量,并用1位异或非(XNOR)运算替代了大多数乘法,这可能会对通用和专用的深度学习硬件产生重大影响。我们写了一个二进制矩阵乘法GPU内核,可以比未经优化的GPU内核的运行MNIST MLP快7倍,同时不会损失分类准确度(见第3节)。
1.BinaryNet
在本节中,我们详细介绍了二值化函数,我们如何使用它来计算参数的梯度以及我们如何通过它进行反向传播。
符号函数
BinaryNet约束权重和激活值要么+1或-1。 从硬件的角度来看,这两个值是非常有利的,正如我们在第3节中解释的那样。我们的二值化函数只是符号函数:
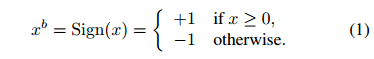
其中xb是二值化变量(权重或激活值)和x是实值变量。在实践中实施并运作良好这非常简单(见第2节)。可以使用随机二值化,如(Courbariaux等人,2015),在理论上更具吸引力,但也是更昂贵的替代方案,因为它需要硬件在量化时生成随机位。
梯度计算和累积
了解BinaryNet的一个关键点是,尽管我们使用二进化权重和激活值计算参数的梯度,但我们仍然用实值变量累积权重实值梯度,根据算法1所示。对于随机梯度下降(SGD)可能需要实值权重才能表现更好。SGD探索通过做小而嘈杂的步骤来确定参数的空间,并且每个权重累积的噪声会通过随机梯度平均化掉。因此它是对于这些累加器保持足够的分辨率很重要,乍看之下表明它是绝对需要高精度。
除此之外,在计算参数的梯度在权重和激活值中添加噪音提供了一种正则化的形式,可以帮助更好地训练,如先前的变量权重噪声所示(Graves,2011),类似于Dropout(Srivastava,2013; Srivastava等,2014)和DropConnect(Wan et al。,2013)。可以将BinaryNet看作为Dropout的变体,在计算参数的梯度时,我们不是将激活值的一半随机设置为零,而是将激活值和权重二值化而已。
通过离散化传播梯度
符号函数的导数处处为0,使得它显然与反向传播不兼容,因为离散化之前(预激活值或权重)关于量化的精确梯度代价将为零。注意,即使使用随机量化这仍然是正确的。 Bengio(2013)研究了通过随机离散神经元估计或传播梯度的问题。他们在实验中发现,当使用“straight-through estimator ”获得了最快的训练速度,之前在Hinton(2012)的讲座中介绍过。
我们遵循类似的方法,但使用straight-through estimator的版本考虑到饱和效应,并且确实使用了确定性而非随机抽样比特位。考虑符号函数量化
q = Sign(r)
并假设梯度 的估计量gq已获得(使用straight-through estimator时需要)。 然后,
的估计量gq已获得(使用straight-through estimator时需要)。 然后, 的straight-through estimator很简单
的straight-through estimator很简单
gr = gq1|r|≤1 (2)
请注意,这会保留梯度的信息,并在r过大时取消梯度。在算法1中解释了straight-through estimator的使用。导数1|r|≤1也可以看作是传播通过hard tanh的梯度,这是以下分段线性激活函数:
Htanh(x) = Clip(x,-1,1) = max(-1,min(1,x)) (3)
对于隐藏单元,我们使用符号函数非线性来获得二值化激活值,对于权重我们组合两个成分:
• 每个实值权重约束在-1和1之间,通过权重更新时将wr带到[-1,1]外将wr投影到-1或1,根据算法1即在训练期间削减权重。否则实值权重将变得非常大而对二值化权重没有任何影响。
• 当使用权重wr时,使用wb = Sign(wr)进行量化
根据等式2,当|wr|>1时的梯度始终取消。
一些有用的成分
我们的实验的一些元素虽然不是绝对必要的,但却显着提高了BinaryNets的准确性,如算法1所示:
• 批量标准化(BN)(Ioffe&Szegedy,2015),在算法2中部分详述,加速了训练而且似乎也减少了权重数值的整体影响。归一化噪声也可能有所帮助规范模型。
• 算法3中详述的ADAM学习规则(Kingma&Ba,2014)似乎也减少了权重数值的影响。
• 最后,根据(Glorot&Bengio,2010),用权重的初始化系数来缩放权重的学习率似乎也有所帮助,正如Courbariaux等所建议的那样(2015年)。
算法1 使用BinaryNet训练DNN
C是小批量的loss函数,λ为学习率衰减因子和L为层数。 ◦ 表示元素乘法。 函数Sign()指定如何对激活值和权重进行二值化,Clip()如何剪辑权重,BatchNorm()和BackBatchNorm()如何通过标准化进行批处理规范化归一化和反向传播(见算法2),Adam()如何知道其梯度来更新参数(见算法3)。

算法2 批量标准化转换(Ioffe和Szegedy,2015),适用于小批量激活x。

算法3 ADAM学习规则(Kingma&Ba,2014)。
gt2表示元素乘法gt◦ gt。默认设置为α= 0.001,β1= 0.9,β2= 0.999和ε=10-8。对向量的所有操作都是逐个元素的。我们将βt1和βt2用β1和β2的幂t形式表示。

2.基准测试结果
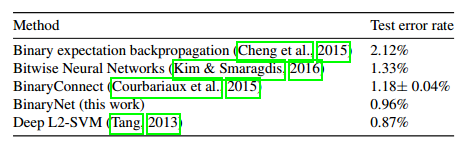
表1.根据不同方法,测试在置换不变量MNIST上训练的MLP的错误率(不知道输入是图像并且不是无监督学习)。 BinaryNet仅需每个权重和激活值一比特位,即可实现接近最优秀的结果。这个结果表明增加了隐藏神经元的数量可以弥补离散化噪声。
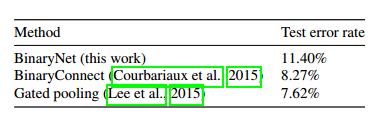
表2.根据不同方法,测试在CIFAR-10上训练的ConvNets的错误率(没有数据增加)。
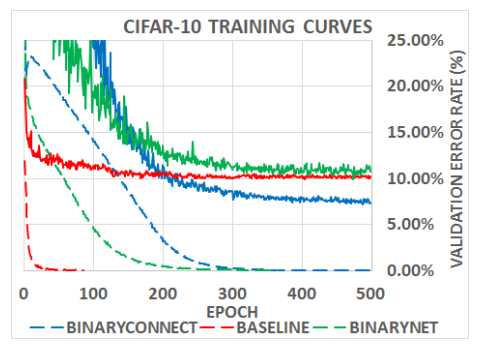
图1 .根据不同方法,在CIFAR-10上ConvNet的训练曲线。虚线表示训练代价(square hinge losses)与实线对应验证错误率。有趣的是,BinaryNet的训练速度更快并且产生比BinaryConnect更糟糕的结果(Courbariaux等,2015),表明它略微过度拟合并可能受益来自额外的噪音(例如Dropout)。

表3.根据不同方法,测试在SVHN上训练的ConvNets的错误率。
在MNIST,CIFAR-10和SVHN这些基准测试中,我们用BinaryNet获得了近乎最好的结果。复现这些结果代码开源。
MLP on MNIST
MNIST是基准图像分类数据集(LeCun等,1998)。它包含60K的训练集和一组10K 28×28灰度图像的测试集,数字范围从0到9。为了完成这个基准测试是一个挑战,我们没有使用任何卷积,数据增强,预处理或无监督学习。
我们在MNIST上训练的MLP包含3个隐藏层4096个二进制单元(见第1节)和L2-SVM输出层; 已经证明L2-SVM的性能优于Softmax在几个分类基准(Tang,2013;Lee et al。,2014)。我们使用Dropout对模型进行规范化(Srivastava,2013; Srivastava等,2014)

表4. CIFAR-10 ConvNet的体系结构。我们只用与VGG一样的“相同”卷积(Simonyan&Zisserman,2015)
使用ADAM自适应学习率方法将square hinge loss 降至最低(Kingma&Ba,2014)。我们使用了指数衰减的全局学习率,并且也根据算法1(Glorot&Bengio,2010)衡量权重学习率与权重初始化系数。我们使用小批量大小为100的批量标准化加快训练速度。通常,我们使用最后10K样本的训练集作为验证集来提前停止模型选择。我们得到的测试错误率与1000个eponchs之后的最佳验证错误率相关联(我们不会在验证集上重新训练)。结果见表1。
ConvNet on CIFAR-10
CIFAR-10是基准图像分类数据集。它包括50K的训练集和10K 32×32的测试集,彩色图像分别代表飞机,汽车,鸟类,猫,鹿,狗,青蛙,马,船和卡车。 我们的确是不使用任何预处理或数据扩充(这个数据集真的是游戏搅局者(Graham,2014)。
我们的ConvNet架构详见表4。除外二值化激活值外,它是与Courbariaux等人的架构相同。 Courbariaux的结构设计灵感来源于VGG(Simonyan&Zisserman,2015)。
使用ADAM可以最大限度地减少方铰链损耗。 我们使用了指数衰减的学习率,就像MNIST一样。我们利用权重初始化系数来衡量权重学习率(Glorot&Bengio,2010。 我们用使用大小为50的小批量进行批量标准化以加速训练。 使用训练集的最后5000个样本作为验证集。我们得到的测试错误率与500个eponchs之后的最佳验证错误率相关联(我们不会在验证集上重新训练)。结果见表2和图1。
ConvNet on SVHN
SVHN是基准图像分类数据集。它包含604K示例的训练集和26K的测试集32×32彩色图像,表示从0到9的数字。我们遵循用于CIFAR-10的相同程序,除了一些值得注意的例外:我们在卷积层中使用了一半的神经元,我们训练了200个epochs而不是500(因为SVHN是一个更大的数据集比CIFAR-10)。 结果如表3所示。
3.在运行时更快

BinaryNet,通过1位(XNOR)操作替换大多数32位乘法大幅减少内存使用量,运行速度比32位浮点值神经网络快得多,既可用于通用硬件,也可用于专用硬件。我们写了一个二进制矩阵乘法GPU内核可以运行我们的MNIST MLP比未经优化的GPU内核快7倍,且没有任何分类准确性的损失。复现这些结果的代码开源。
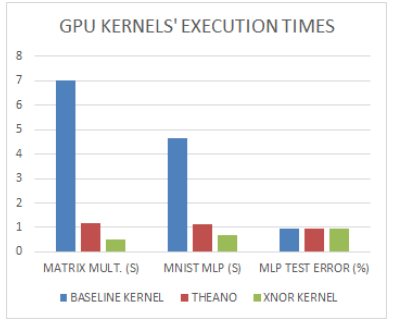
图2.前三列表示在GTX750 Nvidia GPU上执行8192×8192×8192(二进制)矩阵乘法所需时间的表现,这取决于使用的内核。我们可以看到我们的XNOR内核比我们的基线和Theano(Bergstra等,2010; Bastien等,2012)内核快得多。 接下来的三列表示运行第2节中关于完整MNIST测试集的MLP所需的时间表现。由于MNIST的图像不是二进制的,第一层的乘法总是如此由基线内核执行。 最后三列显示MLP精确度不依赖于使用哪个内核。
第一层
在BinaryNet中,权重和激活都是二进制的。由于一层的输出是下一个的输入,所有的图层输入是二进制的,第一层除外。但是,我们认为这不是一个重大问题。首先,在计算机视觉中,输入表示通常具有比内部表示(例如512)有更少的通道(例如,红色,绿色和蓝色)。结果,就参数和计算方面,第一层ConvNet通常是最小的卷积层(Szegedy等,2014)。
其次,处理连续值相对容易,输入为定点数,精度为m位。例如,在8位定点输入的常见情况下:

其中x是1024个8位输入的向量,x8 1是第一个输入的最高有效位,wb是1024个1位权重的向量并得到加权和。算法使用了这个技巧。
XNOR累加
DNN应用主要包括卷积和矩阵乘法。深度学习的关键算术运算就是多次累积的操作。人工神经元基本上是乘法累加器,计算其输入的加权和。使用BinaryNet,激活值和权重被约束为-1或+1。 因此,大多数32位浮点乘法都被1位XNOR运算所取代。这个可能会对深度学习专用硬件产生巨大影响。例如,32位浮点乘数成本大约200个FPGA片(Govindu等,2004; Beauchampet al。2006),而1位XNOR门只需要一个切片。
在GPU上运行时快7倍
通过在寄存器(SWAR)使用一种的人们叫做中SIMD的方法,用BinaryNet 训练DNN可以加速GPU执行。SWAR的基本思想是连接32个二进制变量组成32位寄存器,因此按位操作获得32倍的加速(例如,XNOR)。使用SWAR,可以仅使用4条指令评估32位连接计算:
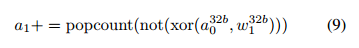
其中a1是结果加权和,a32b 0 和w32b1连接的输入和权重。那4条指令在最新的Nvidia GPU需要7个时钟周期(如果要成为一个融合的指令,它只需要一个单个时钟周期)。结果,我们获得了理论上的NvidiaGPU加速32 =7≈4:6。在实践中,这种加速是很容易获得,因为内存带宽与计算比率也增加了7倍。为了验证这些理论结果,我们写了2个GPU内核:
• 第一个内核(基线)是一个无优化的矩阵乘法内核。
• 第二个内核(XNOR)几乎与基线内核,除了它使用SWAR方法,如公式9所示。
当两个GPU内核的输入被约束为-1或+1时,他们在返回完全相同的输出(但不是其他)。XNOR内核比它基线内核快14倍,比Theano的快2.5倍(Bergstra等,2010; Bastien等,2012),如图2所示。最后但并非最不重要的是,第2节使用XNOR内核而不是基线内核的MLP运行速度提高了7倍,且不会损失任何分类准确性(见图2)。
4.相关工作
Courbariaux等人训练DNN在计算参数的梯度时使用二进制权重。在他们的一些实验中,他们也在某些部分指数量化激活值(但不是所有)的计算。相比之下,我们用二值化权重和激活值训练DNNs,可以更多在硬件方面有效(见第3节)。 此外,他们的方法(BinaryConnect)训练比我们慢(见图1),在MNIST上产生了更糟糕的结果(见表1)但对CIFAR-10和SVHN的结果更好(见表2和3)。
Soudry等人。(2014); 程等人。(2015)不用反向传播训练他们的DNN(BP),但有一个名为期望反向传播(EBP)。 EBP基于Expectation Propagation(EP)(Minka,2001),这是一个变量用于在概率论中进行推理的贝叶斯方法
图形模型。让我们的方法将他们的进行对比:
• 像我们一样,计算参数梯度时他们的方法二值化激活值和权重。
• 他们的方法优化权重后验分布(不是二进制)。在这方面,与我们在实值变量中累加权重的梯度非常相似。
• 为了获得良好的性能,他们的方法需要平均一些二进制的输出从权重后验采样的神经网络分配(可能代价大)。
• 他们的方法(二元期望反向传播)在MNIST上的全连接网络提供了良好的分类精度(见表1),但(尚未)对于ConvNets进行实验
Hwang&Sung(2014); Kim等人。 (2014)重新训练神经具有三元权重和3位激活的网络,即:
• 他们训练高精度的神经网络,
• 训练后,他们将权重三值化为三个可能的值-H,0和+ H,并调整H以最小化输出错误率
• 最终,他们在计算参数梯度时用三值化权重和3位激活值进行重新训练。
相比之下,我们一直用二进制权重训练和激活,即我们的训练程序可以硬件加速,因为它只需要很少的乘法,如(Lin et al。,2015),我们的二值化DNN很可能在运行时更有效。
同样,Kim&Smaragdis(2016)使用二值化权重和激活重新训练深度神经网络。 其方法(按位神经网络)在MNIST上的完全连接网络提供了良好的分类精度(见表1),但(尚未)ConvNets没有。
结论
我们引入了BinaryNet,这是一可以在当计算参数梯度训练时用二值化权重和激活值训练DNN的方法(见第1节)。我们有表明可以在MNIST上训练MLP,CIFAR-10上的ConvNets和带BinaryNet的SVHN并获得近乎最优秀的结果(见章节2)。此外,在运行时,BinaryNet大幅减少内存使用并将大多数乘法替换为1位非独占或(XNOR)操作,可能有对通用和专注的深度学习硬件影响很大。 我们编写了一个二进制矩阵乘法GPU内核,可以运行我们的MNIST MLP比未经优化的GPU内核快7倍,且没有任何分类准确性的损失(见第3节)。未来的工作应该探索如何扩展加速到训练时间(例如通过二值化一些梯度),并将基准测试结果扩展到其他模型(例如RNN)和数据集(例如ImageNet)。
参考资料
本人根据谷歌翻译组织整理语句,英语水平有限,翻译错误望指正
转载请注明出处